09.Django-数据库优化
Django查询数据库性能优化
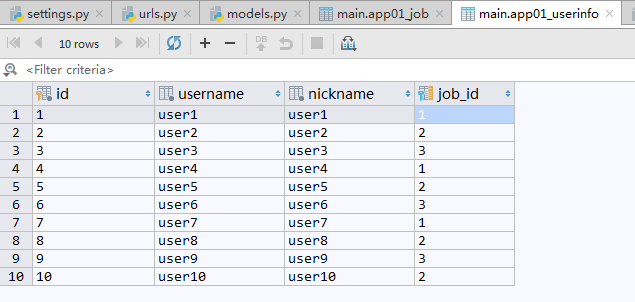
现在有一张记录用户信息的UserInfo数据表,表中记录了10个用户的姓名,呢称,年龄,工作等信息.
models文件
from django.db import models
class Job(models.Model):
title=models.CharField(max_length=32)
class UserInfo(models.Model):
username=models.CharField(max_length=32)
nickname=models.CharField(max_length=32)
job=models.ForeignKey(to="Job",to_field="id",null=True)
数据表中记录:
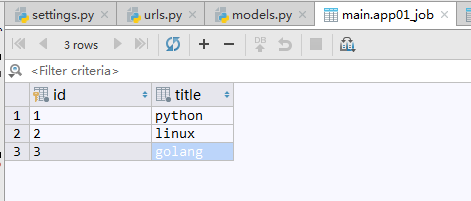
另一张数据表记录用户工作的Job表,关联用户的工作字段.
要查出每个用户的用户名,呢称和工作等信息
def index(request):
user_list=models.UserInfo.objects.all()
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
打印信息:
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
在服务端进行这些操作,这些查询语句的性能是很低的,遍历取出这10个用户的姓名,呢称,工作等信息要在两张数据库中执行11次查询操作.
首先只从UserInfo表中查出所有的用户记录,需要执行一次查询操作.
查询Job数据表,每循环一次用户信息的列表,都需要从Job表中查询一次用户的工作信息.
数据表中总共记录了10条用户记录,所以还需要循环10次才能从Job表中查询完成所有用户的工作信息.所以一共需要执行11次数据库查询操作.
那有没有什么好的方法能够提高数据库查询的效率呢???
def index(request):
user_list=models.UserInfo.objects.values("username","nickname","job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print(user["username"], user["nickname"], user["job"])
return render(request,'index.html')
运行程序,在服务端后台打印信息:
SELECT "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [{'username': 'user1', 'nickname': 'user1', 'job': 1}, {'username': 'user2', 'nickname': 'user2', 'job': 2}, {'username': 'user3', 'nickname': 'user3', 'job': 3}, {'username': 'user4', 'nickname': 'user4', 'job': 1}, {'username': 'user5', 'nickname': 'user5', 'job': 2}, {'username': 'user6', 'nickname': 'user6', 'job': 3}, {'username': 'user7', 'nickname': 'user7', 'job': 1}, {'username': 'user8', 'nickname': 'user8', 'job': 2}, {'username': 'user9', 'nickname': 'user9', 'job': 3}, {'username': 'user10', 'nickname': 'user10', 'job': 2}]>
user1 user1 1
user2 user2 2
user3 user3 3
user4 user4 1
user5 user5 2
user6 user6 3
user7 user7 1
user8 user8 2
user9 user9 3
user10 user10 2
可以看到,查询的结果user_list依然是一个QuerySet,但这个对象集合内部却是一个字典.
而且这次的查询只执行了两次数据库查询操作.
通过这种方式,只需要两次查询就能得到想要的数据,优化了数据库的查询效率.
Django数据库优化操作之select_related主动联表查询
上面的例子里,取对象集合的时候,难道只能查询当前数据表,不能查询其他数据表吗??
当然不是,在这里还可以使用select_related这个方法.
在第一次查询的时候,在all()后面加上一个select_related来做主动的联表查询.
在创建这两张数据表时,job在UserInfo数据表中是做为一个ForeignKey存在的,所以加上select_related后不仅只查询到了UserInfo数据库的记录,同时也查询了Job数据表中的记录.
def index(request):
user_list=models.UserInfo.objects.all().select_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
服务端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id", "app01_job"."id", "app01_job"."title" FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
查看打印出来的查询语句,其中有"FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")"用来做联表查询,只需要一次就可以查询所有的数据了.
同样的,如果还想继续联表,例如在Job表中再加一个外键字段desc,只需要在查询语句中把desc加入进来就可以了
user_list=models.UserInfo.objects.all().select_related("job__desc")
这样一来就把三张表联系起来做联表查询了,但是一定要确保所加的字段为ForeignKey.
如果使用类似models.UserInfo.objects.all()语句进行查询时,不要做跨表查询,只查询当前表中有的数据,否则查询语句的性能会下降很多.
如果想查其他表中的数据,就加上select_related(ForeignKey字段名);
如果想取多个ForeignKey字段的数据,则可以使用select_related(ForeignKey字段1,ForeignKey字段2,...)
联表查询操作性能也会降低,select_related就是用来做主动联表查询的.
Django数据库优化操作之perfetch_related非主动联表查询
perfetch_related方法是既非主动联表查询,又不进行很多查询语句的一种折衷方案
修改视图函数index
def index(request):
user_list=models.UserInfo.objects.all().prefetch_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
后端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
使用prefetch_related方法未联表执行两次查询操作
先查询用户表中的所有数据,把用户表中所有的job_id全部查询出来,并执行去重操作;
结果查询出用户的3种工作,接下来执行"select"语句查询"Job"数据表中的"title"字段
这样一来就只执行了两次数据表的查询操作
在prefetch_related方法中加入一个字段"job",执行了两次数据库查询操作;
如果再加一个字段,则会再多加一次数据为操作操作.
Django数据库优化操作之only方法
def index(request):
user_list=models.UserInfo.objects.all().only("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s" %(user.username,user.nickname))
return render(request,'index.html')
服务端后台打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."username" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1
user2-->user2
user3-->user3
user4-->user4
user5-->user5
user6-->user6
user7-->user7
user8-->user8
user9-->user9
user10-->user10
执行查询操作的时候加上only方法,其查询结果还是一个对象集合,但是从打印出的查询语句可以看到,执行查询操作时只查询了用户的id字段和username字段,并没有查询nickname字段.
但是在后面的循环中,又可以打印用户的nikename信息.为什么呢,因为又执行了一次查询的请求操作.由此得知,查询操作使用了only方法,在only方法中加入哪个查询字段,在后面就使用哪个查询字段.
加only参数是从查询结果中只取某个字段,而另外一个defer方法则是从查询结果中排除某个字段
Django数据库优化操作之defer方法
修改index视图函数
def index(request):
user_list=models.UserInfo.objects.all().defer("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s" % user.nickname)
return render(request,'index.html')
服务端打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1
user2
user3
user4
user5
user6
user7
user8
user9
user10
通过打印的查询语句可以知道,使用defer方法后,只从数据库中查询了用户的id字段和用户的nickname字段操作,并没有查询username字段,由此也可以提高Django查询数据库的性能.
09.Django-数据库优化的更多相关文章
- $Django 站点:样式--文章--分类文章--文章详情--文章评论点赞--文章评论点赞统计(数据库优化)
<h3>个人站点下的</h3> 知识点 url (r'(?P<username>\w+)/p/(?P<id>\d+)', xiangxi,name='x ...
- Django 数据库访问性能优化
使用标准的数据库优化技术: 在进行Django数据库访问性能优化之前,首先应该使用标准的数据库技术对其进行优化,比如给字段加索引,通过使用 django.db.models.Field.db_inde ...
- django性能优化
1. 内存.内存,还是加内存 2. 使用单独的静态文件服务器 3. 关闭KeepAlive(如果服务器不提供静态文件服务,如:大文件下载) 4. 使用memcached 5. 使用select_rel ...
- Django - 02 优化一个应用
Django - 02 优化一个应用 上一篇中我们已经创建了一个blog app,现在来用一下~ 2.1 添加第一篇blog 这个post 列表很丑陋哦,连标题都木有显示~ 2.2 自定义bl ...
- Django 数据库查询优化
Django数据层提供各种途径优化数据的访问,一个项目大量优化工作一般是放在后期来做,早期的优化是“万恶之源”,这是前人总结的经验,不无道理.如果事先理解Django的优化技巧,开发过程中稍稍留意,后 ...
- Django数据库操作性能相关
Django数据库操作性能相关 案例: 现在我们的数据库中有两张表如下: 1.职员表: class UserInfo(models.Model): name = models.CharField(ma ...
- mysql数据库优化 pt-query-digest使用
mysql数据库优化 pt-query-digest使用 一.pt-query-digest工具简介 pt-query-digest是用于分析 mysql慢查询的一个工具,它可以分析binlog.Ge ...
- Django数据库查询优化-事务-图书管理系统的搭建
数据库查询优化 优化:虽然减轻了数据库的压力,但查询速度大大的减慢 ORM内所有的语句操作,默认都是惰性查询,只有你在真正的需要数据的时候才会走数据, 如果你只是写ORM语句时,是不会走数据库的,这样 ...
- 06 ORM常用字段 关系字段 数据库优化查询
一.Django ORM 常用字段和参数 1.常用字段 models中所有的字段类型其实本质就那几种,整形varchar什么的,都没有实际的约束作用,虽然在models中没有任何限制作用,但是还是要分 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
随机推荐
- 14.4 Go Xorm
14.4 Go Xorm 获取xorm go get -u -v github.com/go-xorm/xorm xorm增删改查 /** * 应用程序 * 同目录下多文件引用的问题解决方法: * h ...
- 2.2 Go变量类型
内置类型 值类型: bool 布尔类型 int(32 or 64), int8, int16, int32, int64 整数类型 uint(32 or 64), uint8(byte), uint1 ...
- linux常用命令---yum 工具
yum 工具 yum工具是红帽子才有的软件管理工具,例如suse乌班图等系统,没有yum,apt-get apt-install
- redis 主从哨兵02
一.为什么要复制 1.实现数据的多副本存储,从而可以实现服务的高可用 2.提供更好的读性能,分担读请求 二.复制技术的关键点及难点 1.如何指定被复制对象 2.增量还是全量,以及如何实现增量 3.复制 ...
- 最全面的Android Studio使用教程
http://www.admin10000.com/document/5496.html
- 【Java】面试官灵魂拷问:if语句执行完else语句真的不会再执行吗?
写在前面 最近跳槽找工作的朋友确实不少,遇到的面试题也是千奇百怪,这不,一名读者朋友面试时,被面试官问到了一个直击灵魂的问题:if 语句执行完else语句真的不会再执行吗?这个奇葩的问题把这名读者问倒 ...
- 实验6、Python-OpenCV宽度测量
一. 题目描述 测量所给图片的高度,即上下边缘间的距离. 思路: 将图片进行阈值操作得到二值化图片. 截取只包含上下边框的部分,以便于后续的轮廓提取 轮廓检测 得到结果 二. 实现过程 1.用于给图片 ...
- SQL——SELECT、UPDATE、DELETE和INSERT INTO
SQL是一种ANSI的标准计算机语言.ANSI:美国国家标准化组织.除SQL标准外,大部分SQL数据库都拥有私有的扩展.SQL对大小写不敏感.某些数据库系统要求在SQL命令末端使用分号,这样可以执行一 ...
- springboot中yml常用配置
server: port: 8080 spring: datasource: #数据源配置 driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc: ...
- xshell行号显示
xshell显示行号: 输入命令: vim ~/.vimrc 输入: set nu 之后在打开文件 就可以 看到行号显示.