Tidyverse| XX_join :多个数据表(文件)之间的各种连接
本文首发于公众号:“生信补给站” Tidyverse| XX_join :多个数据表(文件)之间的各种连接
前面分享了单个文件中的select列,filter行,列拆分等,实际中经常是多个数据表,综合使用才能回答你所感兴趣的问题。
本次简单的介绍多个表(文件)连接的方法。
一 载入数据,R包
library(tidyverse)
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
二 合并数据
向数据框中加入新变量,新变量的值是另一个数据框中的匹配观测。
1 连接方式
1) 内连接 inner_join
内连接是最简单的一种连接,只要两个观测的键是相等的,即可匹配。
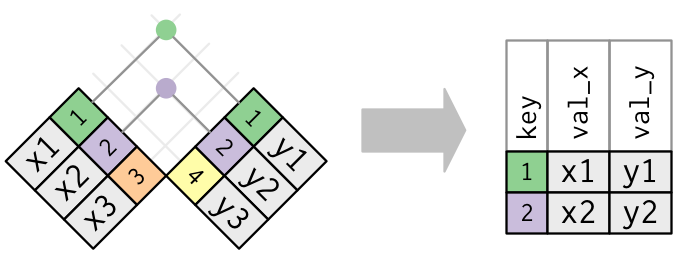
注释:匹配在实际的连接操作中是用圆点表示的。圆点的数量 = 匹配的数量 = 结果中行的数量。下同
x %>%
inner_join(y, by = "key")
# A tibble: 2 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
内连接最重要的性质是,没有匹配的行不会包含在结果中。容易丢失观测,慎用。
2) 外连接
外连接则保留至少存在于一个表中的观测。外连接有 3 种类型: • 左连接 left_join:保留 x 中的所有观测。 • 右连接 right_join:保留 y 中的所有观测 • 全连接 full_join:保留 x 和 y 中的所有观测。
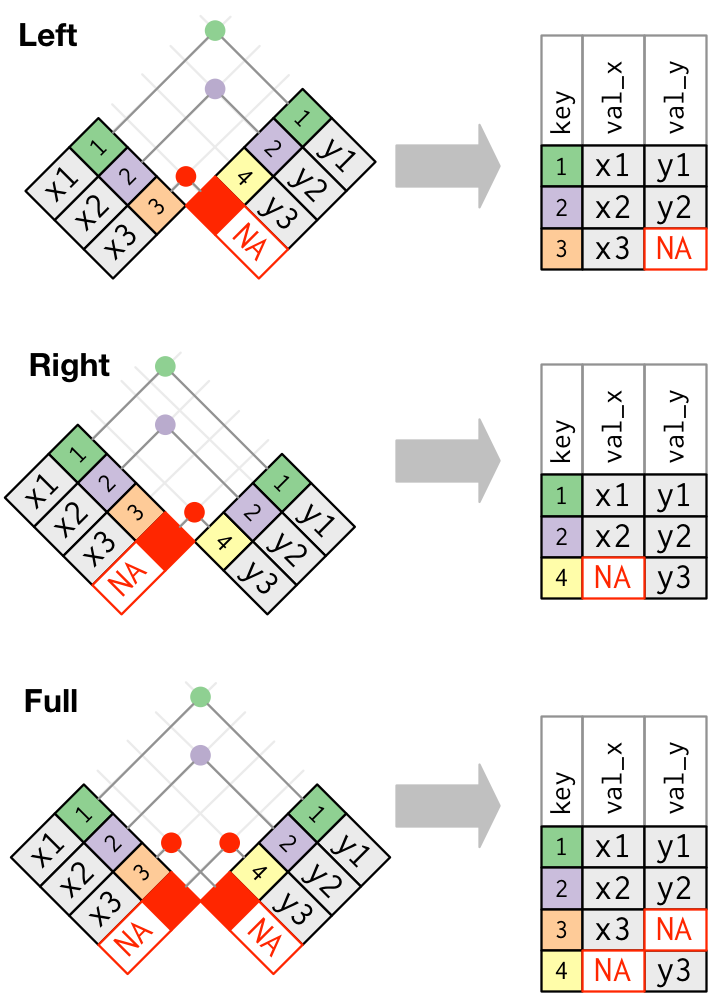
x %>%
left_join(y, by = "key")
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
x %>%
right_join(y, by = "key")
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3
x %>%
full_join(y, by = "key")
# A tibble: 4 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3
2 重复键
以上均假设键具有唯一性,但情况并非总是如此。
如果x中的key变量,在y中有多个同样的key,那么所有的结合可能都会罗列出来
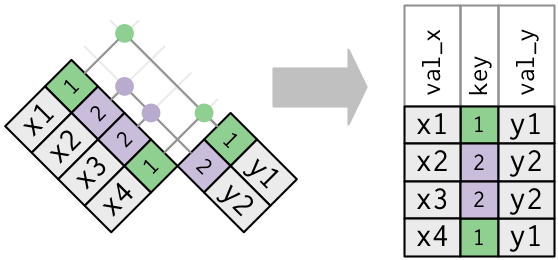
x1 <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
1, "x4"
)
y1 <- tribble(
~key, ~val_y,
1, "y1",
2, "y2"
)
left_join(x1, y1, by = "key")
# A tibble: 4 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x3 y2
4 1 x4 y1
3 定义连接键
1) 默认值 by = NULL
使用存在于两个表中的所有变量,这种方式称为自然连接。
left_join(x, y)
Joining, by = "key"
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
2) 定义匹配键 by = c("a" = "b")
匹配 x 表中的 a 变量和 y 表中的 b 变量,输出结果中使用的是 x 表中的变量。
y_1 <- tribble(
~key2, ~val_y,
1, "y1",
2, "y2"
)
left_join(x, y_1, by = c("key" = "key2"))
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
3) 多个匹配键
x2 <- tribble(
~key,~key1, ~val_x,
1, 2018,"x1",
2, 2019,"x2",
3, 2019,"x3"
)
y2 <- tribble(
~key, ~key1,~val_y,
1, 2018,"y1",
2, 2018,"y2",
4, 2019,"y3"
)
inner_join(x2,y2,by = c("key","key1"))
# A tibble: 1 x 4
key key1 val_x val_y
<dbl> <dbl> <chr> <chr>
1 1 2018 x1 y1
三 筛选连接
筛选连接匹配观测的方式与合并连接相同,但前者影响的是观测,而不是变量。筛选连接 有两种类型。
semi_join函数
保留 x 表中与 y 表中的观测相匹配的所有观测
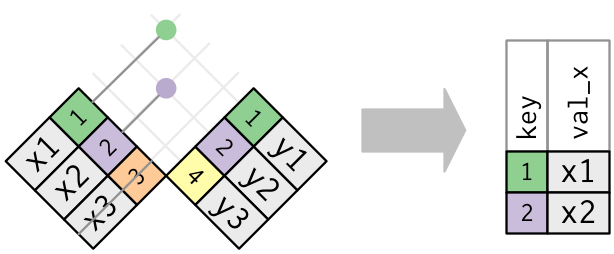
semi_join(x, y, by = "key")
# A tibble: 2 x 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
anti_join函数
丢弃 x 表中与 y 表中的观测相匹配的所有观测。
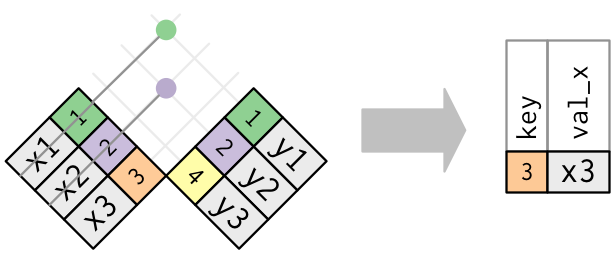
anti_join(x, y, by = "key")
# A tibble: 1 x 2
key val_x
<dbl> <chr>
1 3 x3
参考资料:
《R数据科学》
【觉得不错,右下角点个“在看”,期待您的转发,谢谢!】
Tidyverse| XX_join :多个数据表(文件)之间的各种连接的更多相关文章
- MySQL数据表修复, 如何修复MySQL数据库(MyISAM / InnoDB)
常用的Mysql数据库修复方法有下面3种: 1. mysql原生SQL命令: repair 即执行REPAIR TABLE SQL语句 语法:REPAIR TABLE tablename[,table ...
- 使用Pandas将多个数据表合一
使用Pandas将多个数据表合一 将多张数据表合为一张表,便于统计分析,进行这一操作的前提为这多张数据表互相之间有关联信息,或者有相同的列. import pandas as pd unames = ...
- COPY - 在表和文件之间拷贝数据
SYNOPSIS COPY tablename [ ( column [, ...] ) ] FROM { 'filename' | STDIN } [ [ WITH ] [ BINARY ] [ O ...
- Oracle 表空间和数据文件之间的关系
首先,你需要明白的一点是:数据库的物理结构是由数据库的操作系统文件所决定,每一个Oracle数据库是由三种类型的文件组成:数据文件.日志文件和控制文件.数据库的文件为数据库信息提供真正的物理存储. 每 ...
- ubuntu下面mysql,通过载入txt文件初始化数据表
环境:ubuntu12.04 mysql(通过apt安装) (1)根据数据表中的属性列,对应在txt中构造记录(一行对应一条记录),不同属性之间通过tab键(以/root目录下构建的init.tx ...
- MyBatis学习(二)---数据表之间关联
想要了解MyBatis基础的朋友可以通过传送门: MyBatis学习(一)---配置文件,Mapper接口和动态SQL http://www.cnblogs.com/ghq120/p/8322302. ...
- sql server迁移数据(文件组之间的互相迁移与 文件组内文件的互相迁移)
转自:https://www.cnblogs.com/lyhabc/p/3504380.html?utm_source=tuicool SQLSERVER将数据移到另一个文件组之后清空文件组并删除文件 ...
- wordpress数据库结构以及数据表之间的关系
默认WordPress一共有以下11个表.这里加上了默认的表前缀 wp_ . wp_commentmeta:存储评论的元数据 wp_comments:存储评论 wp_links:存储友情链接(Blog ...
- 3dTiles 数据规范详解[3] 内嵌在瓦片文件中的两大数据表
转载请声明出处:全网@秋意正寒 零.本篇前言 说实话,我很纠结是先介绍瓦片的二进制数据文件结构,还是先介绍这两个重要的表.思前想后,我决定还是先介绍这两个数据表. 因为这两个表不先给读者灌输,那么介绍 ...
随机推荐
- 黑马程序员_毕向东_Java基础视频教程——java语言组成部分(随笔)
java语言组成部分 Java是一种强类型语言,所谓强类型语言就是对具体的数据进行不同的定义.对类型的划分的十分细致,对内存中分配了不同大小的内u你空间 关键字 标识符 注释 变量和常量 运算符 语句 ...
- Redis的几种集群方式分析
一 单机版 分析: 无论多少用户,都访问这一台服务器 .服务器一旦挂了,所有用户都无法访问.风险很大,一般不会有人使用. 二 主从模式(master/slaver) 分析: 主从模式中, 无论多少用户 ...
- XCode Interface Builder开发——1
XCode Interface Builder开发--1 创建Xcode项目 选择第二个选项 选择Single View App,点击Next 设置完后点击Next Xcode基本面板 导航面板 工具 ...
- 如何将你的node服务放到线上服务器
最近在用node写后端数据处理,以前虽然也用node写数据来进行测试,但是一直都是处于本地使用, 今天想将node作为后端服务来处理数据, 特此,以此博客记录. 第一步,写node 接口, 在本地我们 ...
- JQuery 高级
来源于传智播客老师发的笔记 今日内容: 1. JQuery 高级 1. 动画 2. 遍历 3. 事件绑定 4. 案例 5. 插件 JQuery 高级 1. 动画 1. 三种方式显示和隐藏元素 1. 默 ...
- SpringBoot_自动装配
SpringBoot SrpingBoot 给人的第一印象就是 简洁,易上手.它是自 Spring 而来为了简化我们开发的,而经历过了 Spring 中繁琐的配置文件,我确实很好奇它到底是怎么帮我们把 ...
- BZOJ1066 网络流
拆点,将一个柱子拆成入点和出点,入点出点之间的容量就是柱子的容量 1066: [SCOI2007]蜥蜴 在一个r行c列的网格地图中有一些高度不同的石柱,一些石柱上站着一些蜥蜴,你的任务是让尽量多 ...
- 405 - 不允许用于访问此页的 HTTP 谓词的处理办法
今天介绍的是针对访问html页面时出现此类错误的处理办法,如果你的问题页面是其他类型,可以参考如下信息: IIS 返回 405 - 不允许用于访问此页的 HTTP 谓词.终极解决办法!!!! 1.为什 ...
- Centos7 安装完以后安全配置
1.更新系统和补丁 我们的互联网是很不安全的,每天都有新的漏洞出现和修复,所以一定要更新.更新.更新, yum -y update 上面的命令是检查更新并安装,包括内核和软件,建议刚安装完就更新一次, ...
- SQL面试50题
1.查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号(重点) SELECT a.s_id,a.s_score FROM (') as a INNER JOIN (') as b on ...