Tidyverse| XX_join :多个数据表(文件)之间的各种连接
本文首发于公众号:“生信补给站” Tidyverse| XX_join :多个数据表(文件)之间的各种连接
前面分享了单个文件中的select列,filter行,列拆分等,实际中经常是多个数据表,综合使用才能回答你所感兴趣的问题。
本次简单的介绍多个表(文件)连接的方法。
一 载入数据,R包
library(tidyverse)
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
二 合并数据
向数据框中加入新变量,新变量的值是另一个数据框中的匹配观测。
1 连接方式
1) 内连接 inner_join
内连接是最简单的一种连接,只要两个观测的键是相等的,即可匹配。
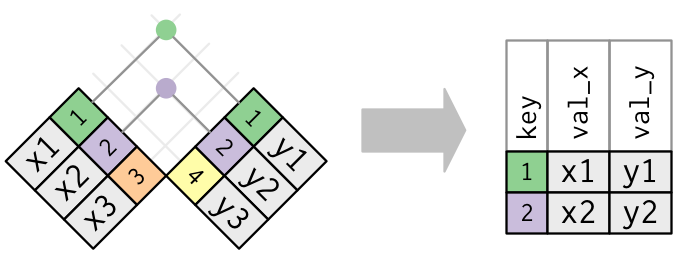
注释:匹配在实际的连接操作中是用圆点表示的。圆点的数量 = 匹配的数量 = 结果中行的数量。下同
x %>%
inner_join(y, by = "key")
# A tibble: 2 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
内连接最重要的性质是,没有匹配的行不会包含在结果中。容易丢失观测,慎用。
2) 外连接
外连接则保留至少存在于一个表中的观测。外连接有 3 种类型: • 左连接 left_join:保留 x 中的所有观测。 • 右连接 right_join:保留 y 中的所有观测 • 全连接 full_join:保留 x 和 y 中的所有观测。
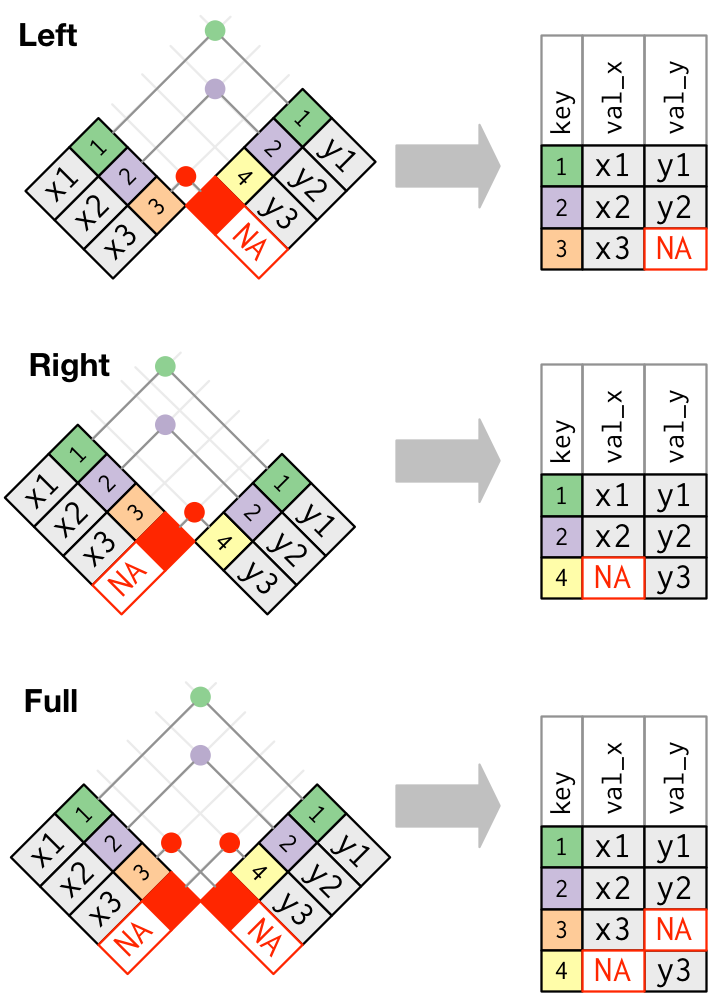
x %>%
left_join(y, by = "key")
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
x %>%
right_join(y, by = "key")
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3
x %>%
full_join(y, by = "key")
# A tibble: 4 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3
2 重复键
以上均假设键具有唯一性,但情况并非总是如此。
如果x中的key变量,在y中有多个同样的key,那么所有的结合可能都会罗列出来
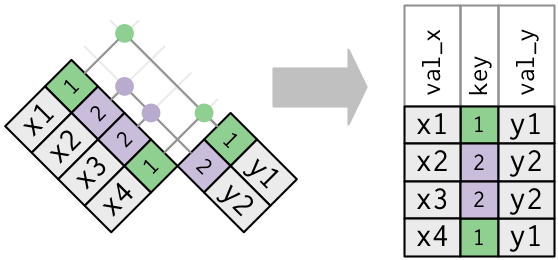
x1 <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
1, "x4"
)
y1 <- tribble(
~key, ~val_y,
1, "y1",
2, "y2"
)
left_join(x1, y1, by = "key")
# A tibble: 4 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x3 y2
4 1 x4 y1
3 定义连接键
1) 默认值 by = NULL
使用存在于两个表中的所有变量,这种方式称为自然连接。
left_join(x, y)
Joining, by = "key"
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
2) 定义匹配键 by = c("a" = "b")
匹配 x 表中的 a 变量和 y 表中的 b 变量,输出结果中使用的是 x 表中的变量。
y_1 <- tribble(
~key2, ~val_y,
1, "y1",
2, "y2"
)
left_join(x, y_1, by = c("key" = "key2"))
# A tibble: 3 x 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
3) 多个匹配键
x2 <- tribble(
~key,~key1, ~val_x,
1, 2018,"x1",
2, 2019,"x2",
3, 2019,"x3"
)
y2 <- tribble(
~key, ~key1,~val_y,
1, 2018,"y1",
2, 2018,"y2",
4, 2019,"y3"
)
inner_join(x2,y2,by = c("key","key1"))
# A tibble: 1 x 4
key key1 val_x val_y
<dbl> <dbl> <chr> <chr>
1 1 2018 x1 y1
三 筛选连接
筛选连接匹配观测的方式与合并连接相同,但前者影响的是观测,而不是变量。筛选连接 有两种类型。
semi_join函数
保留 x 表中与 y 表中的观测相匹配的所有观测
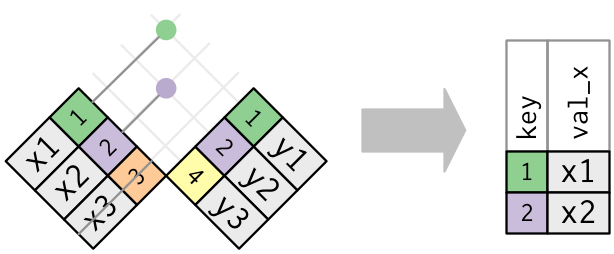
semi_join(x, y, by = "key")
# A tibble: 2 x 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
anti_join函数
丢弃 x 表中与 y 表中的观测相匹配的所有观测。
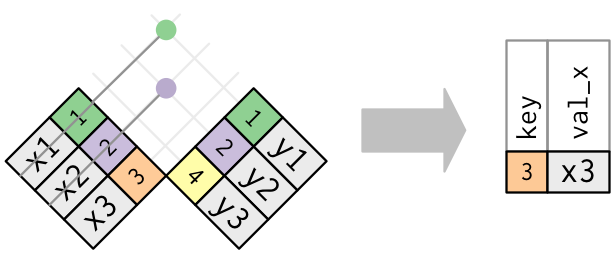
anti_join(x, y, by = "key")
# A tibble: 1 x 2
key val_x
<dbl> <chr>
1 3 x3
参考资料:
《R数据科学》
【觉得不错,右下角点个“在看”,期待您的转发,谢谢!】
Tidyverse| XX_join :多个数据表(文件)之间的各种连接的更多相关文章
- MySQL数据表修复, 如何修复MySQL数据库(MyISAM / InnoDB)
常用的Mysql数据库修复方法有下面3种: 1. mysql原生SQL命令: repair 即执行REPAIR TABLE SQL语句 语法:REPAIR TABLE tablename[,table ...
- 使用Pandas将多个数据表合一
使用Pandas将多个数据表合一 将多张数据表合为一张表,便于统计分析,进行这一操作的前提为这多张数据表互相之间有关联信息,或者有相同的列. import pandas as pd unames = ...
- COPY - 在表和文件之间拷贝数据
SYNOPSIS COPY tablename [ ( column [, ...] ) ] FROM { 'filename' | STDIN } [ [ WITH ] [ BINARY ] [ O ...
- Oracle 表空间和数据文件之间的关系
首先,你需要明白的一点是:数据库的物理结构是由数据库的操作系统文件所决定,每一个Oracle数据库是由三种类型的文件组成:数据文件.日志文件和控制文件.数据库的文件为数据库信息提供真正的物理存储. 每 ...
- ubuntu下面mysql,通过载入txt文件初始化数据表
环境:ubuntu12.04 mysql(通过apt安装) (1)根据数据表中的属性列,对应在txt中构造记录(一行对应一条记录),不同属性之间通过tab键(以/root目录下构建的init.tx ...
- MyBatis学习(二)---数据表之间关联
想要了解MyBatis基础的朋友可以通过传送门: MyBatis学习(一)---配置文件,Mapper接口和动态SQL http://www.cnblogs.com/ghq120/p/8322302. ...
- sql server迁移数据(文件组之间的互相迁移与 文件组内文件的互相迁移)
转自:https://www.cnblogs.com/lyhabc/p/3504380.html?utm_source=tuicool SQLSERVER将数据移到另一个文件组之后清空文件组并删除文件 ...
- wordpress数据库结构以及数据表之间的关系
默认WordPress一共有以下11个表.这里加上了默认的表前缀 wp_ . wp_commentmeta:存储评论的元数据 wp_comments:存储评论 wp_links:存储友情链接(Blog ...
- 3dTiles 数据规范详解[3] 内嵌在瓦片文件中的两大数据表
转载请声明出处:全网@秋意正寒 零.本篇前言 说实话,我很纠结是先介绍瓦片的二进制数据文件结构,还是先介绍这两个重要的表.思前想后,我决定还是先介绍这两个数据表. 因为这两个表不先给读者灌输,那么介绍 ...
随机推荐
- 一分钟掌握MySQL的InnoDB引擎B+树索引
MySQL的InnoDB索引结构采用B+树,B+树什么概念呢,二叉树大家都知道,我们都清楚随着叶子结点的不断增加,二叉树的高度不断增加,查找某一个节点耗时就会增加,性能就会不断降低,B+树就是解决这个 ...
- 未联网下,在eclipse中编辑xml文件如何自动提示设置
断网情况下,用eclipse编辑xml文件如何自动提示? 以编辑hibernate中的xml为例: 首先,我们都知道xml提示是引用.dtd文件的. 1.复制这个dtd路径,设置eclipse属性,搜 ...
- 终于,帮开发写了一个bug
写在文章的开头 最近项目比较紧,尤其前端的的需求比较多,作为一名测试,也会些vue,本着加快项目进度的美好想法,就自告奋勇的向组长承接了一部分开发的任务,其中有个需求需要在我们的广告管理后台新增一个上 ...
- vue的slot
1.明确一点:分发内容是在父作用域内编译: 2.slot作为备用内容的条件:宿主元素为空且父元素没有要分发的内容. 3.具名slot:<slot name="XXX"> ...
- SpringBoot整合Redis实现简单的set、get
一.导入pom.xml文件相关的依赖并配置 <dependency> <groupId>org.springframework.boot</groupId> < ...
- MCP3421使用详解
0 摘要 因某项目需要,需要采集微弱的电压信号,且对电压精度要求较高,于是选中MCP3421这款18 bit 高精度IIC AD转换芯片.本文将结合MCP3421的手册,对该芯片的使用进行详细解释,并 ...
- python操作MySQL之pymysql模块
import pymysql#pip install pymysql db=pymysql.connect(','day040') cursor=db.cursor() #创建游标 book_list ...
- TypeError: Cannot assign to read only property 'exports' of object '#<Object>'
我的项目在mac上运行的很好,结果windows电脑,就一直报这个错误 解决方案: babel增加 @babel/plugin-transform-modules-commonjs 参考文章: htt ...
- Jquery获取select option动态添加自定义属性值失效
Jquery获取select option动态添加自定义属性值失效 2014/12/31 11:49:19 中国学网转载 编辑:李强 http://www.xue163.com/588880/3909 ...
- linux DRM/KMS 测试工具 modetest、kmscude、igt-gpu-tools (二)
kmscube kmscube is a little demonstration program for how to drive bare metal graphics without a c ...