Spark Streaming与流处理
Spark Streaming与流处理
一、流处理
1.1 静态数据处理
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
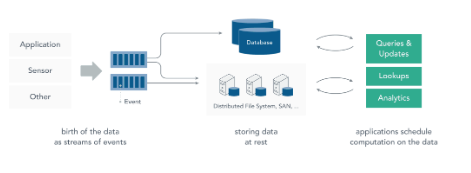

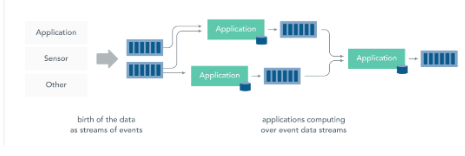
1.2 流处理
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。

流处理带来了静态数据处理所不具备的众多优点:
应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
二、Spark Streaming
2.1 简介
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
通过高级 API 构建应用程序,简单易用;
支持多种语言,如 Java,Scala 和 Python;
良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态;
能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合;
Spark Streaming 可以从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,也支持自定义数据源。

2.2 DStream
Spark Streaming 提供称为离散流 (DStream) 的高级抽象,用于表示连续的数据流。 DStream 可以从来自 Kafka,Flume 和 Kinesis 等数据源的输入数据流创建,也可以由其他 DStream 转化而来。在内部,DStream 表示为一系列 RDD。

2.3 Spark & Storm & Flink
storm 和 Flink 都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
Spark Streaming与流处理的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十三之铭文升级版
铭文一级: 第10章 Spark Streaming整合Kafka spark-submit \--class com.imooc.spark.KafkaReceiverWordCount \--ma ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
官网文档:<http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example> Sp ...
- Spark学习之路(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop采用HDFS进行数据 ...
- Spark 系列(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop 采用 HDFS 进 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二十一之铭文升级版
铭文一级: DataV功能说明1)点击量分省排名/运营商访问占比 Spark SQL项目实战课程: 通过IP就能解析到省份.城市.运营商 2)浏览器访问占比/操作系统占比 Hadoop项目:userA ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十八之铭文升级版
铭文一级: 功能二:功能一+从搜索引擎引流过来的 HBase表设计create 'imooc_course_search_clickcount','info'rowkey设计:也是根据我们的业务需求来 ...
随机推荐
- js 一个或多个一维数组,算出元素之间相互组合的所有情况
// 数据源 var target = { state1: ['1', '2'], state2: ['01', '02', '03'], state3: ['001','002'] } stackS ...
- 在 Azure CentOS VM 中配置 SQL Server 2019 AG - (上)
前文 假定您对Azure和SQL Server HA具有基础知识 假定您对Azure Cli具有基础知识 目标是在Azure Linux VM上创建一个具有三个副本的可用性组,并实现侦听器和Fenci ...
- Python logging 模块打印异常 exception
logger.exception(sys.exc_info())
- (c++ std) 查找 vector 中的元素
You can use std::find from <algorithm>: std::find(vector.begin(), vector.end(), item) != vecto ...
- ELK6.3版本安装部署
一.Elasticsearch 安装 1.部署系统以及环境准备 cat /etc/redhat-release CentOS Linux release 7.4.1708 (Core) uname - ...
- handlebars模板引擎使用初探1
谈到handlebars,我们不禁产生疑问,为什么要使用这样的一个工具呢?它究竟能为我们带来什么样的好处?如何使用它呢? 一.handlebars可以干什么? 首先,我们来看一个案例: 有这样的htm ...
- javascript中Function、ArrowFunction和GeneratorFunction介绍
ECMAScript规范中对Function的文档描述,我认为是ECMAScript规范中最复杂也是最不好理解的一部分,它涉及到了各方面.光对Function就分了Function Definitio ...
- php beast windows编译教程
git clone https://github.com/Microsoft/php-sdk-binary-tools.git c:\php-sdk cd c:\php-sdk git checkou ...
- CentOS 6.5下通过yum安装MongoDB记录
安装MongoDB 1.创建repo vi /etc/yum.repos.d/mongodb-org-3.6.repo [mongodb-org-3.6] name=MongoDB Repos ...
- 图论--最短路--dijkstra(含路径输出)模板
#include<iostream> #include<stack> #include<queue> #include<cstring> #includ ...