Scrapy 框架结构及工作原理
1、下图为 Scrapy 框架的组成结构,并从数据流的角度揭示 Scrapy 的工作原理
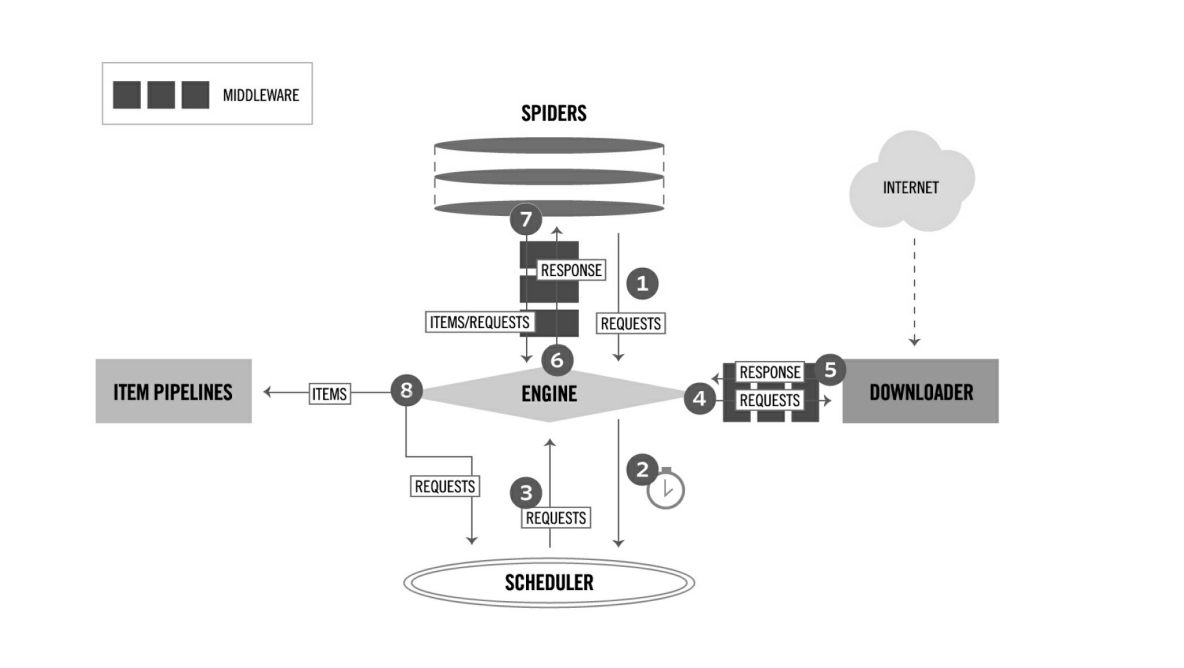 2、首先、简单了解一下 Scrapy 框架中的各个组件
2、首先、简单了解一下 Scrapy 框架中的各个组件
| 组 件 | 描 述 | 类 型 |
| ENGINE | 引擎,框架的核心,其他所有组件在其控制下协同工作 | 内部组件 |
| SCHEDULER | 调度器,负责对 SPIDER 提交的下载请求进行调度 | 内部组件 |
| DOWNLOADER | 下载器,负责下载页面(发送 HTTP 请求/接收 HTP 响应) | 内部组件 |
| SPIDER | 爬虫,负责提取页面中的数据,并产生对新页面的下载请求 | 外部组件 |
| MIDDLEWAERE | 中间件,负责对 Request 对象和 Response 对象进行处理 | 可选组件 |
| ITEM PIPELINE | 数据管道,负责对爬取到的数据进行处理 | 可选组件 |
对于用户来说,Spider 是最核心的组件,Scrapy 开发是围绕着 Spider 展开的
3、接下来,看一下框架中的数据流
| 对 象 | 描 述 |
| REQUEST | Scrapy 中的 HTTP 请求对象 |
| RESPONSE | Scrapy 中的 HTTP 响应对象 |
| ITEM | 从页面中爬取的一项数据 |
Request 和 Response 是 HTTP 协议的术语,即 HTTP 请求和 HTTP 响应,Scrapy 框架中定义了相应的 Request 和 Response 类,这里的 Item 带白哦Spider 从页面中爬取的一项数据
4、最后,我们来说明一下以上几种对象在框架中的流动过程
(1)当 Spider 要爬取某 URL 地址的页面时,需要用该 URL 构造一个 Request 对象,提交给 ENGINE.
(2)Request 对象随后进入 SCHEDULER 按某种算法进行排队,之后的某个时刻 SCHEDULER 将其出队,送往 DOWNLOADER
(3)DOWNLOADER 根据Request 对象中的 URL 地址发送一次 HTTP 请求到网站服务器,之后用服务器返回的 HTTP 响应构造出一个 Response 对象,其中包含页面的 HTML 文本
(4)Response 对象最终会被递交给 SPIDER 的页面解析函数(构造 Request 对象时指定)进行处理,页面解析函数从页面中提取带数据,封装成 Item 提交给 ENGINE,
item之后被送往 ITEM PIPELINES 进行处理,最终可能由 EXPORTER 易某种数据格式写入文件(csv, json)另一方面,页面解析函数还从页面中提取链接,构造新的
Request 对象提交给 ENGINE
理解了框架中的数据流,也就理解了 Scrapy 爬虫的工作原理,如果把框架中的组件比作人体的各个器官,Request 和 Response 对象便是血液,Item 则是代谢产物
Scrapy 框架结构及工作原理的更多相关文章
- scrapy框架结构与工作原理
组件: ENGINE:引擎,框架的核心,其他组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度 DOWNLOADER:下载器,负责下载页面,发送HTTP请求 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
随机推荐
- 通过WMI获取网卡MAC地址、硬盘序列号、主板序列号、CPU ID、BIOS序列号
转载:https://www.cnblogs.com/tlduck/p/5132738.html #define _WIN32_DCOM #include<iostream> #inclu ...
- java使用bitmap求两个数组的交集
一般来说int代表一个数字,但是如果利用每一个位 ,则可以表示32个数字 ,在数据量极大的情况下可以显著的减轻内存的负担.我们就以int为例构造一个bitmap,并使用其来解决一个简单的问题:求两个数 ...
- 【CSS选择器】
" 目录 一.介绍 二.语法 三.引入方式 1. 行内样式 2. 嵌入式 3. 外部样式 四.选择器 1. 基本选择器 2. 组合选择器 3. 属性选择器 4. 不常用选择器 5. 分组和嵌 ...
- CSS3实现魔方动画
本文将借助css3实现魔方动画效果,设计思路如下: HTML方面采用六个div容器形成六个立方面: CSS方面采用transform-style: preserve-3d;形成三维场景:transfo ...
- C语言:求n(n<10000)以内的所有四叶玫瑰数。-将字符串s1和s2合并形成新的字符串s3,先取出1的第一个字符放入3,再取出2的第一个字符放入3,
//函数fun功能:求n(n<10000)以内的所有四叶玫瑰数并逐个存放到result所指数组中,个数作为返回值.如果一个4位整数等于其各个位数字的4次方之和,则称该数为函数返回值. #incl ...
- 【实战】Springboot +jjwt+注解实现需登录才能操作
springboot +jjwt+注解实现需登录才能调用接口 1.开发需要登录才能进行操作的自定义注解NeedLogin,后面可以写在需要登陆后操作的接口上 package com.songzhen. ...
- Intellij IDEA中创建Package变成一级目录
1.创建包,但是出来的却是一级目录 2.因为Compact Middle Packages默认勾选上了,取消掉即可
- 搭建一个ssm框架的maven项目需要配置的文件
单独功能需要的配置文件: 1,mybatis配置文件 mybatis-config.xml2,spring配置文件 spring-context.xml ......3,we ...
- 802.1X基本配置
基本的802.1X部署工作包括以下4步: 1. 为Cisco Catalyst交换机配置802.1X认证方 2. 为交换机配置访客VLAN或者受限VLAN,并调整802.1X定时器(可选) ...
- mybatis源码探索笔记-5(拦截器)
前言 mybatis中拦截器主要用来拦截我们在发起数据库请求中的关键步骤.其原理也是基于代理模式,自定义拦截器时要实现Interceptor接口,并且要对实现类进行标注,声明是对哪种组件的指定方法进行 ...