记一次uboot升级过程的两个坑
背景
之前做过一次uboot的升级,当时留下了一些记录,本文摘录其中比较有意思的两个问题。
启动失败问题
问题简述
uboot代码中用到了一个库,考虑到库本身跟uboot版本没什么关系,就直接把旧的库文件拷贝过来使用。结果编译链接是没问题,启动却会卡住。
消失的打印
为了明确卡住的位置,就去修改了库的源码,添加一些打印(此时还是在旧版本uboot下编译的),结果发现卡住的位置或随着添加打印的变化而变化,且有些打印语句,添加后未打印出来。
我决定先从这些神秘消失的打印入手。
分析下uboot中的printf实现,最底层就是写寄存器,是一个同步的函数,也没什么可疑的地方。
为了确认打印不出来的时候,到底有没有调用到printf,我决定给printf增加一个计数器,在gd结构体中,增加一个printf_count字段,初始化为0,每次打印时执行printf_count++并打印出值。
设计这个试验,本意是确认未打印出来时是否确实也调用到了printf,但却有了别的发现,实验结果中printf_count值会异常变化,不是按打印顺序递增,而是会突变成很大的异常值。
printf_count是gd结构体的成员,那就是gd的问题了。进一步将uboot全局结构体gd的地址打印出来。确认了原因是gd结构体的指针变化了。
这也可以解释部分打印消失的现象,原因是我们在gd中有另一个字段,用于控制打印等级。当gd被改动了,printf就可能解析出错,误以为打印等级为0而提前返回。
gd的实现
那么好端端的,gd为什么会被改了呢?这就要先看看gd到底是怎么实现的了。
uboot中维护了一个全局的结构体gd。在代码中加入
DECLARE_GLOBAL_DATA_PTR;
即可使用gd指针访问这个全局结构体,许多地方都会借助gd来保存传递信息。
进一步看看这个宏的定义
旧版本uboot:
#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
新版本uboot:
#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r9")
居然不一样,一个是将gd的值放到r8寄存器,一个是放在r9寄存器。
那么就可以猜测到,库是在旧版本uboot中编译出来的,可能使用了r9,那么放到新版本uboot中去,就会破坏r9寄存器中保存的gd值,导致一系列依赖gd的代码不能正常工作。
验证改动
为了求证,将库反汇编出来,发现确实避开了r8寄存器,但使用了r9寄存器。
说明uboot在指定gd寄存器的同时,还有某种方法让其他代码不使用这个寄存器。
那是不是把旧uboot中的这个r8改成r9,重新编译库就可以了呢?试一下,还是不行。
那么禁止其他代码使用r8寄存器肯定就是通过别的方式实现的了。简单粗暴地在旧版本uboot下搜索r8,去掉.c .h等类型后,很容易发现了
./arch/arm/cpu/armv7/config.mk:24:PLATFORM_RELFLAGS += -fno-common -ffixed-r8 -msoft-floa
将-ffixed-r8修改为-ffixed-r9,重新编译出库,这回就可以正常工作了,打印正常,启动正常。反汇编出来也可以看到,新编译出来的库用了r8没有用r9。
当然更好的改法,是直接在新版本的uboot中编译,这是最可靠的。
追本溯源
话说回来,为什么两个版本的uboot,会使用不同的寄存器呢?难道有什么坑?
这就得去翻一下git记录了。
commit fe1378a961e508b31b1f29a2bb08ba1dac063155
Author: Jeroen Hofstee <jeroen@myspectrum.nl>
Date: Sat Sep 21 14:04:41 2013 +0200
ARM: use r9 for gd
To be more EABI compliant and as a preparation for building
with clang, use the platform-specific r9 register for gd
instead of r8.
note: The FIQ is not updated since it is not used in u-boot,
and under discussion for the time being.
The following checkpatch warning is ignored:
WARNING: Use of volatile is usually wrong: see
Documentation/volatile-considered-harmful.txt
Signed-off-by: Jeroen Hofstee <jeroen@myspectrum.nl>
cc: Albert ARIBAUD <albert.u.boot@aribaud.net>
从git记录中,也可以确认完整地将r8切换到r9,都需要做哪些修改
diff --git a/arch/arm/config.mk b/arch/arm/config.mk
index 16c2e3d1e0..d0cf43ff41 100644
--- a/arch/arm/config.mk
+++ b/arch/arm/config.mk
@@ -17,7 +17,7 @@ endif
LDFLAGS_FINAL += --gc-sections
PLATFORM_RELFLAGS += -ffunction-sections -fdata-sections \
- -fno-common -ffixed-r8 -msoft-float
+ -fno-common -ffixed-r9 -msoft-float
# Support generic board on ARM
__HAVE_ARCH_GENERIC_BOARD := y
diff --git a/arch/arm/cpu/armv7/lowlevel_init.S b/arch/arm/cpu/armv7/lowlevel_init.S
index 82b2b86520..69e3053a42 100644
--- a/arch/arm/cpu/armv7/lowlevel_init.S
+++ b/arch/arm/cpu/armv7/lowlevel_init.S
@@ -22,11 +22,11 @@ ENTRY(lowlevel_init)
ldr sp, =CONFIG_SYS_INIT_SP_ADDR
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
#ifdef CONFIG_SPL_BUILD
- ldr r8, =gdata
+ ldr r9, =gdata
#else
sub sp, #GD_SIZE
bic sp, sp, #7
- mov r8, sp
+ mov r9, sp
#endif
/*
* Save the old lr(passed in ip) and the current lr to stack
diff --git a/arch/arm/include/asm/global_data.h b/arch/arm/include/asm/global_data.h
index 79a9597419..e126436093 100644
--- a/arch/arm/include/asm/global_data.h
+++ b/arch/arm/include/asm/global_data.h
@@ -47,6 +47,6 @@ struct arch_global_data {
#include <asm-generic/global_data.h>
-#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
+#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r9")
#endif /* __ASM_GBL_DATA_H */
diff --git a/arch/arm/lib/crt0.S b/arch/arm/lib/crt0.S
index 960d12e732..ac54b9359a 100644
--- a/arch/arm/lib/crt0.S
+++ b/arch/arm/lib/crt0.S
@@ -69,7 +69,7 @@ ENTRY(_main)
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
sub sp, #GD_SIZE /* allocate one GD above SP */
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
- mov r8, sp /* GD is above SP */
+ mov r9, sp /* GD is above SP */
mov r0, #0
bl board_init_f
@@ -81,15 +81,15 @@ ENTRY(_main)
* 'here' but relocated.
*/
- ldr sp, [r8, #GD_START_ADDR_SP] /* sp = gd->start_addr_sp */
+ ldr sp, [r9, #GD_START_ADDR_SP] /* sp = gd->start_addr_sp */
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
- ldr r8, [r8, #GD_BD] /* r8 = gd->bd */
- sub r8, r8, #GD_SIZE /* new GD is below bd */
+ ldr r9, [r9, #GD_BD] /* r9 = gd->bd */
+ sub r9, r9, #GD_SIZE /* new GD is below bd */
adr lr, here
- ldr r0, [r8, #GD_RELOC_OFF] /* r0 = gd->reloc_off */
+ ldr r0, [r9, #GD_RELOC_OFF] /* r0 = gd->reloc_off */
add lr, lr, r0
- ldr r0, [r8, #GD_RELOCADDR] /* r0 = gd->relocaddr */
+ ldr r0, [r9, #GD_RELOCADDR] /* r0 = gd->relocaddr */
b relocate_code
here:
@@ -111,8 +111,8 @@ clbss_l:cmp r0, r1 /* while not at end of BSS */
bl red_led_on
/* call board_init_r(gd_t *id, ulong dest_addr) */
- mov r0, r8 /* gd_t */
- ldr r1, [r8, #GD_RELOCADDR] /* dest_addr */
+ mov r0, r9 /* gd_t */
+ ldr r1, [r9, #GD_RELOCADDR] /* dest_addr */
/* call board_init_r */
ldr pc, =board_init_r /* this is auto-relocated! */
启动慢问题
问题简述
填了几个坑之后,新的uboot可以启动到内核了,但发现启动速度非常慢,内核启动速度慢了接近10倍!明明是同一个内核,为什么差异这么大。
排查寄存器
初步排查了下设备树配置,以及uboot跳转内核前的一些关键寄存器,确实在两个版本的uboot中有所不同,但具体去看这些不同,发现都不会影响速度,将一些驱动对齐之后寄存器差异基本就消失了。
差异的分界
那再细看,kernel的速度有差异,uboot呢?在哪个时间点之后,速度开始产生差异?
尝试在两个版本的uboot中插入一些操作,对比时间戳,发现两个uboot在某个节点之后的速度确实有区别。
进一步排查,原来是在打开cache操作之后,旧uboot的速度就会比新uboot快。尝试将旧uboot的cache关掉,则二者基本一致。尝试将旧uboot操作cache的代码,移植到新uboot,未发生改变。
此时可确认新uboot的开cache有问题。但觉得这个跟kernel启动慢没关系。因为uboot进入kernel之前都会关cache,由kernel自己去重新打开。
也就是不管是用哪份uboot,也不管uboot中是否开了cache,对kernel阶段都应该没有影响才对。
于是记录下来uboot的这个问题,待后续修复。先继续找kernel启动慢的原因。(注:现在看来当时的做法是有问题的,这里的异常这么明显,应该设法追踪下去找出原因才对)
锁定uboot
uboot的嫌疑非常大,但还不能完全确认,因为uboot之前还有一级spl。是否会是spl的问题呢?
尝试改用新spl+旧uboot,启动速度正常。而新spl+新uboot的启动速度则很慢,其他因素都不变,说明问题确实出在uboot阶段。
多做or少做
当时到这一步就卡住了,直接比较两份uboot的代码不太现实,差异太大了。
后来我就给自己提了个问题,到底新uboot是多做了某件事情,还是少做了某件事情?
换个说法,目前已知
spl --> 旧uboot --> kernel(速度快)
spl --> 新uboot --> kernel(速度快)
但到底是以下的情况A还是情况B呢?
A: spl(速度慢) --> 旧uboot(做了某个会提升速度的操作) --> kernel(速度快)
spl(速度慢) --> 新uboot(少做了某个会提升速度的操作) --> kernel(速度慢)
B: spl(速度快) --> 旧uboot(没做特殊操作) --> kernel(速度快)
spl(速度快) --> 新uboot(多做了某个会限制速度的操作) --> kernel(速度慢)
为了验证,我决定让spl直接启动内核,看看内核到底是快是慢。
支持过程碰到了一些小问题
1.spl没有能力加载这么大的kernel
解决:此时不需要kernel能完全启动,只需要能加载启动一段,足以体现出启动速度是否正常即可,于是裁剪出一个非常小kernel来辅助实验。
2.kernel需要dtb
解决:内核有一个CONFIG_BUILD_ARM_APPENDED_DTB_IMAGE选项。选上重新编译。编译后再用dd将kernel和dtb拼接到一起,作为新的kernel。这样,spl就只需要加载一个文件并跳转过去即可。
试验结果,spl启动的kernel和使用新uboot启动的kernel速度一致,均比旧uboot启动的kernel慢。
说明,旧uboot中做了某个关键操作,而新uboot没做。
找出关键操作
那接下来的任务就是,找出旧uboot中的这个关键操作了。
怎么找呢?有了上一步的成果,我们可以使用以下方法来排查
spl加载kernel和旧ubootspl跳转到旧uboot,此时kernel其实已经在dram中准备好了,随时可以启动在旧
uboot的启动流程各个阶段,尝试直接跳转到kernel,观察启动速度如果在旧
uboot的A点跳转kernel启动慢,B点跳转启动快,则说明关键操作位于AB点之间。
方法有了,很快就锁定到start.S,进一步在start.S中揪出了这段代码
#if defined(CONFIG_ARM_A7)
@set SMP bit
mrc p15, 0, r0, c1, c0, 1
orr r0, r0, #(1<<6)
mcr p15, 0, r0, c1, c0, 1
#endif
新uboot的start.S中没有这段代码,尝试在新uboot的start.S中添加此操作,速度立马恢复正常了。
再全局搜索下,原来这个新版本uboot中,套路是在board_init中进行此项设置的,而这个平台从旧版本移植过来,就没有设置 SMP bit, 补上即可。
SMP bit是什么
SMP 是指对称多处理器,看起来这个 bit 会影响多核的 cache一致性,此处没有再深入研究。
但可以知道,对于单处理器的情况,也需要设置这个bit才能正常使用cache。
贴下arm的图和描述:
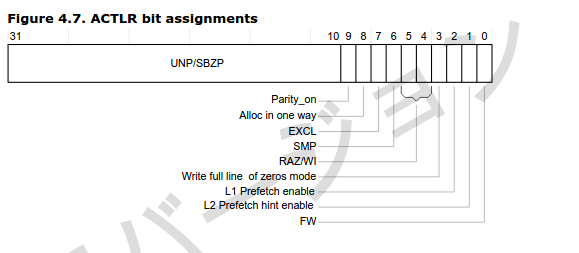
[6] SMP
Signals if the Cortex-A9 processor is taking part in coherency or not.
In uniprocessor configurations, if this bit is set, then Inner Cacheable Shared is treated as Cacheable. The reset value is zero.
搜下kernel的代码,发现也是有地方调用了的。不过这个芯片是单核的,根本就没配置CONFIG_SMP。
#ifdef CONFIG_SMP
ALT_SMP(mrc p15, 0, r0, c1, c0, 1)
ALT_UP(mov r0, #(1 << 6)) @ fake it for UP
tst r0, #(1 << 6) @ SMP/nAMP mode enabled?
orreq r0, r0, #(1 << 6) @ Enable SMP/nAMP mode
orreq r0, r0, r10 @ Enable CPU-specific SMP bits
mcreq p15, 0, r0, c1, c0, 1
#endif
总结
整理出来一方面是记录这两个bug,另一方面也是想记录下当时的一些操作。
毕竟同样的bug可能以后都不会碰到了,但解bug的方法和思路却是可以积累复用的。
blog: https://www.cnblogs.com/zqb-all/p/13172546.html
公众号:https://sourl.cn/shT3kz
记一次uboot升级过程的两个坑的更多相关文章
- android recovery升级过程中掉电处理
一般在升级过程,都会提示用户,请勿断电,不管是android的STB,TV还是PHONE,或者是其他的终端设备,升级过程,基本上都可以看到“正在升级,请勿断电”,然后有个进度条,显示升级的进度. 但是 ...
- uboot启动过程理解
对于2440而言,启动的方式不多.一般就是外界一个NAND FLASH ,2440内部有个NAND FLASH Controller,会自动把NAND FLASH的前4K拷贝到2440的片内SRAM. ...
- OTA制作及升级过程笔记【转】
本文转载自:http://www.it610.com/article/5752570.htm 1.概述 1.1 文档概要 前段时间学习了AndroidRecovery模式及OTA升级过程,为加深理 ...
- U-Boot启动过程完全分析
U-Boot启动过程完全分析 1.1 U-Boot工作过程 U-Boot启动内核的过程可以分为两个阶段,两个阶段的功能如下: (1)第一阶段的功能 硬件设备初始化 加载U-Boot第二阶段 ...
- 通过 yum update 将系统从CentOS 6.2 升级到 CentOS 6.6 及升级过程中的简单排错
本文说明 本文写于2014年的WP中,后WP停止维护,今天翻到此记录整理下,记录于此,方便日后查看. 话说那时候写博客真是认真啊~哈哈~ 升级前的系统信息 [root@thatsit ~]# unam ...
- Android系统Recovery工作原理之使用update.zip升级过程---updater-script脚本语法简介以及执行流程(转)
目前update-script脚本格式是edify,其与amend有何区别,暂不讨论,我们只分析其中主要的语法,以及脚本的流程控制. 一.update-script脚本语法简介: 我们顺着所生成的脚本 ...
- App安全(一) Android防止升级过程被劫持和换包
文/ Tamic 地址/ http://blog.csdn.net/sk719887916/article/details/52233112 前言 APP 安全一直是开发者头痛的事情,越来越多的安全漏 ...
- recovery 升级过程LED灯闪烁
Android设备在进入recovery升级的过程,我们在屏幕上面可以看到升级的机器人动画,以及升级的进度显示.这仅限于有屏幕的设备,比如平板PAD,电视TV等,对与没有屏幕的盒子BOX,那么在不接入 ...
- 与PHP5.3.5的战斗----记php5.3.5安装过程
与PHP5.3.5的战斗----记php5.3.5安装过程 摘自:http://blog.csdn.net/lgg201/article/details/6125189这篇文章写的很是不错,,,也是我 ...
随机推荐
- 4 CSS文本属性
CSStext(文本)属性可定义文本外观,比如文本颜色,对齐文本,装饰文本,文本缩进,行间距等 4.1文本颜色 color属性用于定义文本颜色. div { color: red; } 颜色表示方法: ...
- 【Gabor】基于多尺度多方向Gabor融合+分块直方图的表情识别
Topic:表情识别Env: win10 + Pycharm2018 + Python3.6.8Date: 2019/6/23~25 by hw_Chen2018 ...
- IT笑话十则(二)
一.女程序员征婚 女程序员是这么征婚的: SELECT * FROM 男人们 WHERE 未婚=true and 同性恋=false and 有房=true and 有车=true and 条件 in ...
- 00016-layui 动态加载菜单 laytpl
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <%@ i ...
- JAVA WEB EL表达式注入
看猪猪侠以前的洞,顺便总结下: 一.EL表达式简介 EL 全名为Expression Language.EL主要作用: 1.获取数据 EL表达式主要用于替换JSP页面中的脚本表达式,以从各种类型的we ...
- 01 . RabbitMQ简介及部署
RabbitMQ简介 MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它 ...
- Scala - 语言专家 - Desugar Scala code
https://mp.weixin.qq.com/s/zwrG1MfUzXwtik7jotpQsA 介绍Intellij IDEA中的一个去除Scala语法糖的功能. 1. 去除 ...
- HttpServletRequest对象,请求行、请求头、请求体
HttpServletRequest 公共接口类HttpServletRequest继承自ServletRequest.客户端浏览器发出的请求被封装成为一个HttpServletRequest对象.对 ...
- 从0开始探究vue-公共变量的管理
背景 在Vue项目中,我们总会遇到一些公共数据的处理,如方法拦截,全局变量等,本文旨在解决这些问题 解决方案 事件总线 所谓事件总线,就是在当前的Vue实例之外,再创建一个Vue实例来专门进行变量传递 ...
- Java实现 LeetCode 733 图像渲染(DFS)
733. 图像渲染 有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间. 给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的 ...