python3之scrapy数据存储问题(MySQL)
这次我用的是python3.6,scrapy在python2.7,3.5的使用方法都不同所以要特别注意,
列如 在python3.5的开发环境下scrapy 的主爬虫文件可以使用 from urllib import parse 而python3.6就不行,还有许多不兼容的黎姿例子还需我们去发现
一般python操作mysql数据时,都会用到MYSQLDB,目前来讲MYSQLDB只在2.7版板上支持
所以我选择了pymysql 和 sqlalchemy 用于scrapy爬取数据时存储数据,但在python3.6版本中sqlalchemy效果不佳,代码冗杂,所以我使用了pymysql
数据存储的过程中编码的问题十分重要,下图为大家展示错误的案例:
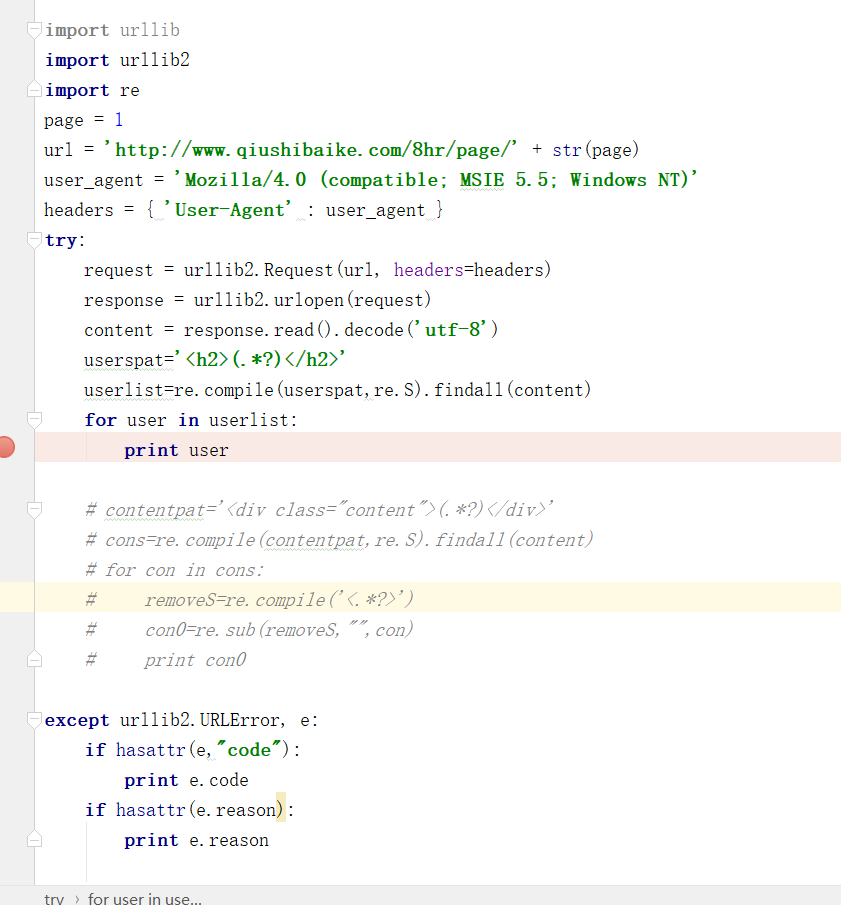
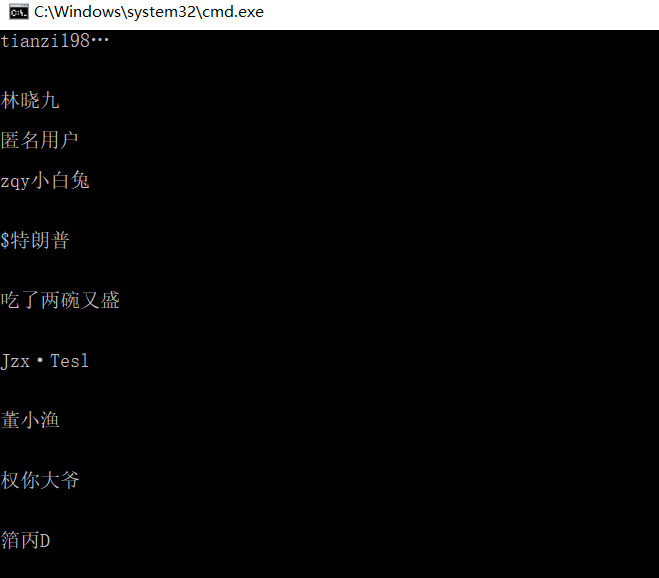
如上图所示我正常爬取了糗事百科某一页的用户名列表,结果如下:
现在我引入pymysql直接进行数据存储

在这里我将下载的数据强制转换为字符串存储,执行完毕后查看数据表:
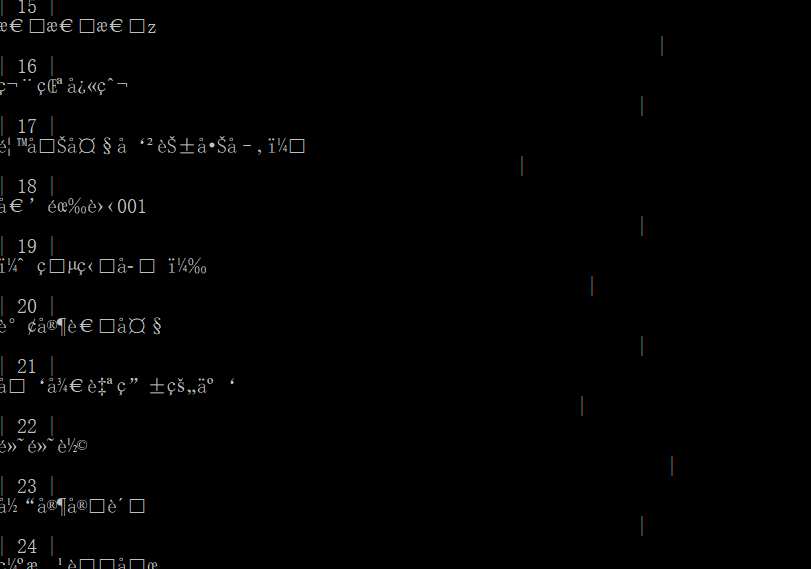
很明显乱码了
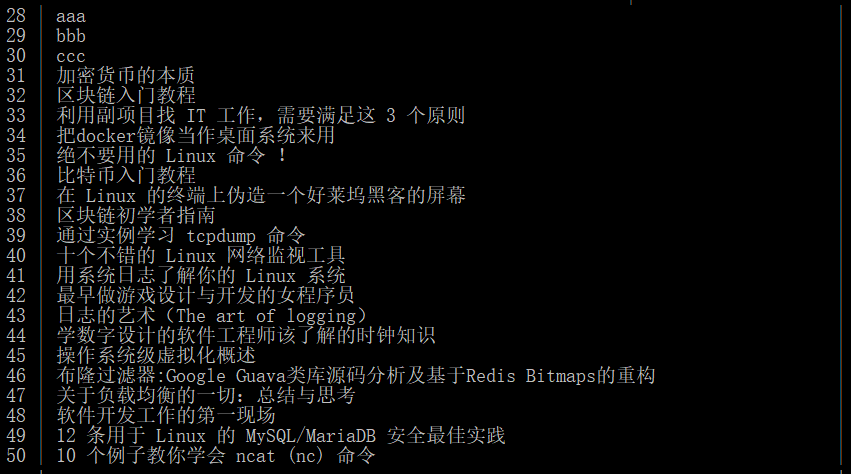
下面我将在scrapy里pipelines.py引入pymysql模块并进行改进:

运行结果如下:
python3之scrapy数据存储问题(MySQL)的更多相关文章
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- scrapy数据存储在mysql数据库的两种方式
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(se ...
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)
将爬取数据存储在JSON文件里并不难,只需修改pipelines文件 直接看代码: 来看下结果: 中文字符恶心的很 之后我会在后卷中做出修改
- 第四天,同步和异常数据存储到mysql,item loader方法
github对应代码:伯乐在线文章爬取 一. 普通插入方法 1. 连接到我的阿里云,用户名是test1,然后在navicat中新建数据库
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
随机推荐
- linux目录和安装目录学习
我一般会在/opt目录下创建 一个software目录,用来存放我们从官网下载的软件格式是.tar.gz文件,或者通过 wget+地址下载的.tar.gz文件 执行解压缩命令,这里以nginx举例 t ...
- 17.3.12--urllib2模块
1---urllib2是非常强大的Python网络资源访问模块,它的功能和urllib模块相似 python标准库中的urllib2模块可以说是urlib模块的一个升级的复杂版,不需要另外下载, 比如 ...
- druid socket timeout超时15分钟(转载)
背景 在应用端通过mybatis的interceptor自定义Plugin拦截Executor, 统计输出sql的执行耗时. 今天生产发生一个很奇怪的问题: 莫名其妙卡顿15分钟+,其后正常返回sql ...
- LGOJ3747 六省联考2017 分手是祝愿
这两天遇到不少这种"人类智慧题"了,感觉都是很巧妙的 Description link 现在有 \(n\) 盏灯,设每一次操作控制第 \(i\) 占灯,而改变状态的灯就是 \(i\ ...
- MySQL--SHOW TABLE STATUS命令
show table status 获取表的信息 来自:http://blog.csdn.net/java2000_wl/article/details/7935035
- 批量刷数据sql
update t_free_m** m set m.plate_no = ( select v.plate_num from t_wh_vehi*** v where v.vin = m.car_v ...
- 控制台输出<迷你DVD管理>
使用顺序.选择.循环.跳转语句 数组 功能实现菜单显示和切换 输入的数字不符合要求直接退出程序 用户可以选择新增.查看. 删除.借出.归还.退出 思路分析 使用switch语句实现菜单选择 使用do- ...
- 论文翻译——Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection
Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection 动态池和展开递归自动编码器的意译检测 论文地 ...
- Ioc和依赖注入
转自https://www.cnblogs.com/zhangzonghua/p/8540701.html 1.IOC 是什么 IOC- Inversion of Control , 即“控制反转” ...
- coursera课程视频
#!/usr/bin/env python # coding=utf-8 import urllib import urllib2 import cookielib def setcookie(ena ...