python3之scrapy数据存储问题(MySQL)
这次我用的是python3.6,scrapy在python2.7,3.5的使用方法都不同所以要特别注意,
列如 在python3.5的开发环境下scrapy 的主爬虫文件可以使用 from urllib import parse 而python3.6就不行,还有许多不兼容的黎姿例子还需我们去发现
一般python操作mysql数据时,都会用到MYSQLDB,目前来讲MYSQLDB只在2.7版板上支持
所以我选择了pymysql 和 sqlalchemy 用于scrapy爬取数据时存储数据,但在python3.6版本中sqlalchemy效果不佳,代码冗杂,所以我使用了pymysql
数据存储的过程中编码的问题十分重要,下图为大家展示错误的案例:
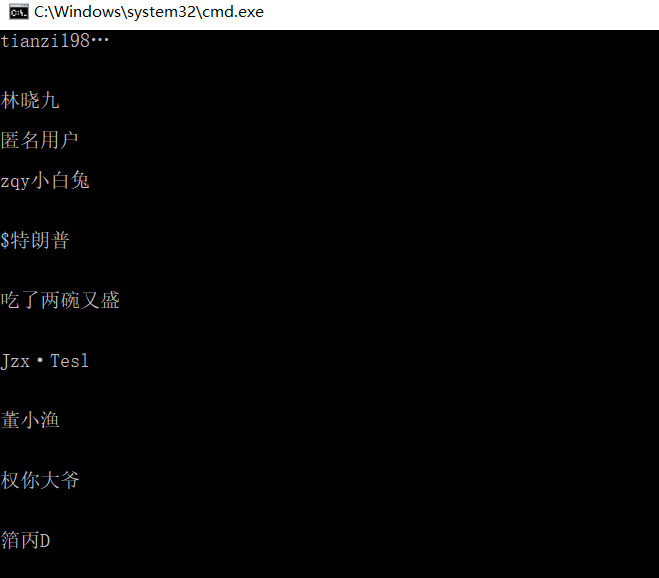
如上图所示我正常爬取了糗事百科某一页的用户名列表,结果如下:
现在我引入pymysql直接进行数据存储

在这里我将下载的数据强制转换为字符串存储,执行完毕后查看数据表:
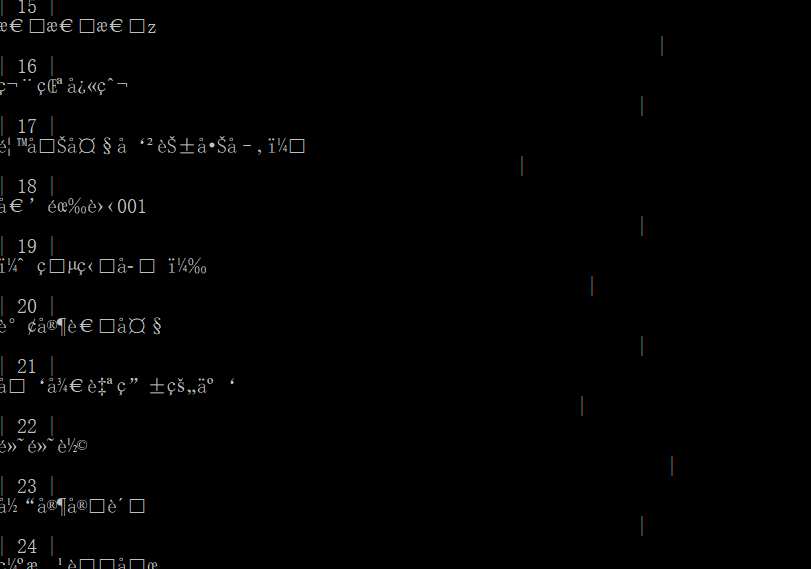
很明显乱码了
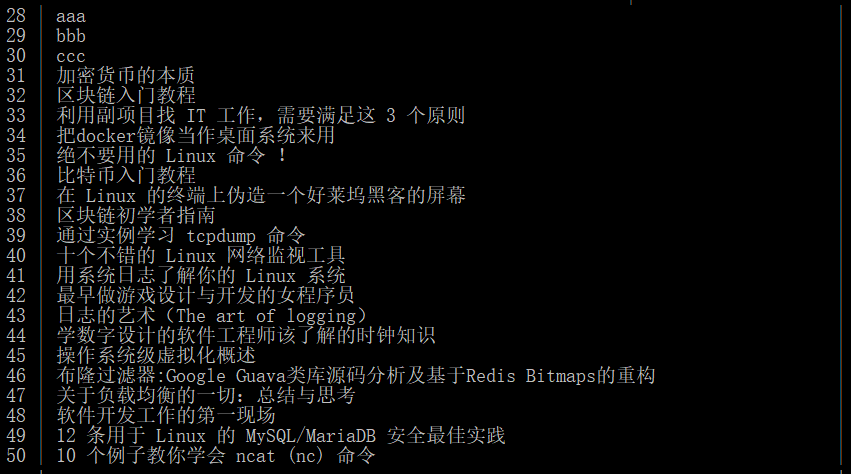
下面我将在scrapy里pipelines.py引入pymysql模块并进行改进:

运行结果如下:
python3之scrapy数据存储问题(MySQL)的更多相关文章
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- scrapy数据存储在mysql数据库的两种方式
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(se ...
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)
将爬取数据存储在JSON文件里并不难,只需修改pipelines文件 直接看代码: 来看下结果: 中文字符恶心的很 之后我会在后卷中做出修改
- 第四天,同步和异常数据存储到mysql,item loader方法
github对应代码:伯乐在线文章爬取 一. 普通插入方法 1. 连接到我的阿里云,用户名是test1,然后在navicat中新建数据库
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
随机推荐
- linux的vi编辑器中如何查找内容(关键字)
按下”/“键,这时在状态栏(也就是屏幕左下脚)就出现了 “/” 然后输入你要查找的关键字敲回车就可以了. 找到相关文字以后: (1)按下小写n,向下查找 (2)按下大写N,向上查找
- Python说文解字_杂谈02
1. Py中三个中啊哟的概念type.object和class的关系. type生成了int生成了1 type->class->obj type用来生成类对象的 object是最顶层的基类 ...
- Object中有哪些公共方法及作用
大家在学习java的时候,一定遇到过Object类,因为在java单一继承体系中Object类是根类,所有的类都会继承它,并拥有Object的公共方法,意味着在java的面向对象的世界中,所有对象都拥 ...
- PAT Basic 1104 数字⿊洞 (20) [数学问题-简单数学]
题目 给定任⼀个各位数字不完全相同的4位正整数,如果我们先把4个数字按⾮递增排序,再按⾮递减排序,然后⽤第1个数字减第2个数字,将得到⼀个新的数字.⼀直重复这样做,我们很快会停在有"数字⿊洞 ...
- Cutting Sticks UVA - 10003(DP 仍有不明白的地方)
题意:对一根长为l的木棒进行切割,给出n个切割点,每次切割的价值,等于需要切割的木头长度. 一开始理解错了,认为切割点时根据当前木条的左端点往右推算. 实际上,左端点始终是不变的一直是0,右端点一直是 ...
- C/C++ 取整函数ceil(),floor()
使用floor函数.floor(x)返回的是小于或等于x的最大整数.如: floor(10.5) == 10 floor(-10.5) == -11 使用ceil函数.ceil(x)返回 ...
- UML-类图-箭头
概览 1.泛化 一般理解为 继承.实线+空心箭头 2.依赖 成员变量.局部变量.参数.虚线+箭头 public class Sale { public void updatePriceFor(Prod ...
- ZJNU 1528 - War--高级
类似于1213取水 可以把空投当作第0个城市 最后将0~n的所有城市跑最小生成树 /* Written By StelaYuri */ #include<iostream> #includ ...
- Python操作redis总结
安装模块及配置 首先安装redis,在Ubuntu下输入指令pip install redis即可.下载完成后,cd到指定目录下,打开指定文件,如下图所示: 输入密码打开后,修改指定地方的内容,与上篇 ...
- cygwin下命令行下切换目录
比我们正常切换目录多个挂载的文件夹 cygdrive