Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件:
1、输入的数据来自可靠的数据源和可靠的接收器;
2、应用程序的metadata被application的driver持久化了(checkpointed );
3、启用了WAL特性(Write ahead log);
一、可靠的数据源和可靠的接收器
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
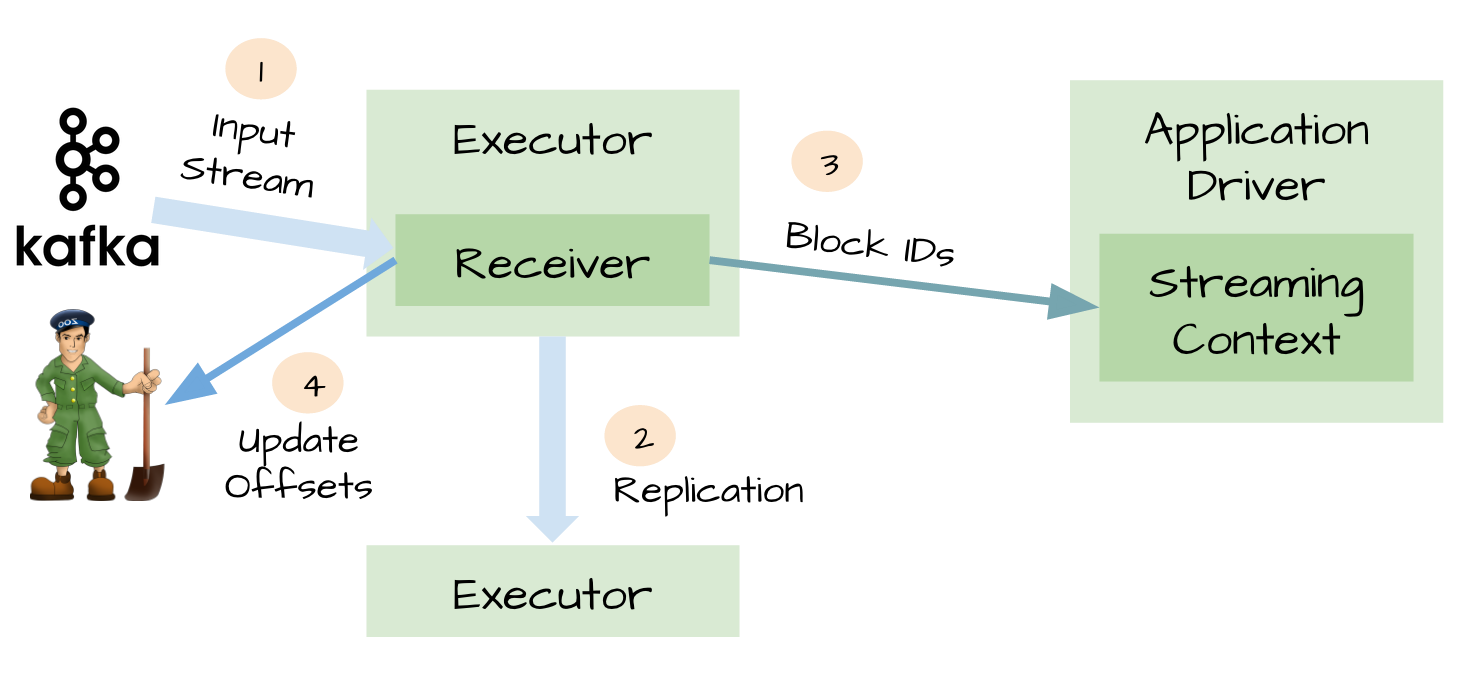
二、元数据持久化(Metadata checkpointing)
可靠的数据源和接收器可以让我们从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)。但是更棘手的问题是,如果Driver挂掉如何恢复?对此开发者们引入了很多技术来让Driver从失败中恢复。其中一个就是对应用程序的元数据进行Checkpint。利用这个特性,Driver可以将应用程序的重要元数据持久化到可靠的存储中,比如HDFS、S3;然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
1、配置;
2、代码;
3、那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)

由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
三、可能存在数据丢失的场景
令人惊讶的是,即使是可靠的数据源、可靠的接收器和对元数据进行Checkpint,仍然不足以阻止潜在的数据丢失。我们可以想象出以下的糟糕场景:
1、两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;
2、接收器通知输入源数据已经接收;
3、Exectuor根据应用程序的代码开始处理已经缓存的数据;
4、这时候Driver突然挂掉了;
5、从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;
6、既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;
7、缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
这对于很多关键型的应用程序来说非常的糟糕,不是吗?
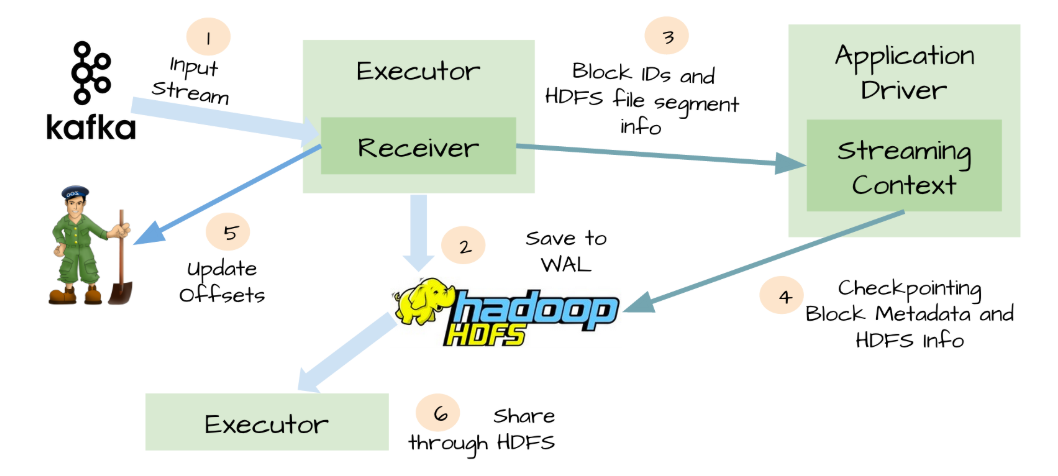
四、WAL(Write ahead log)
为了解决上面提到的糟糕场景,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中,比如HDFS或者S3。由于采用了WAl机制,Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了。在这个简单的方法下,Spark Streaming提供了一种即使是Driver挂掉也可以避免数据丢失的机制。
五、At-least-once语义
虽然WAL可以确保数据不丢失,它并不能对所有的数据源保证exactly-once语义。想象一下可能发生在Spark Streaming整合Kafka的糟糕场景。
1、接收器接收到输入数据,并把它存储到WAL中;
2、接收器在更新Zookeeper中Kafka的偏移量之前突然挂掉了;
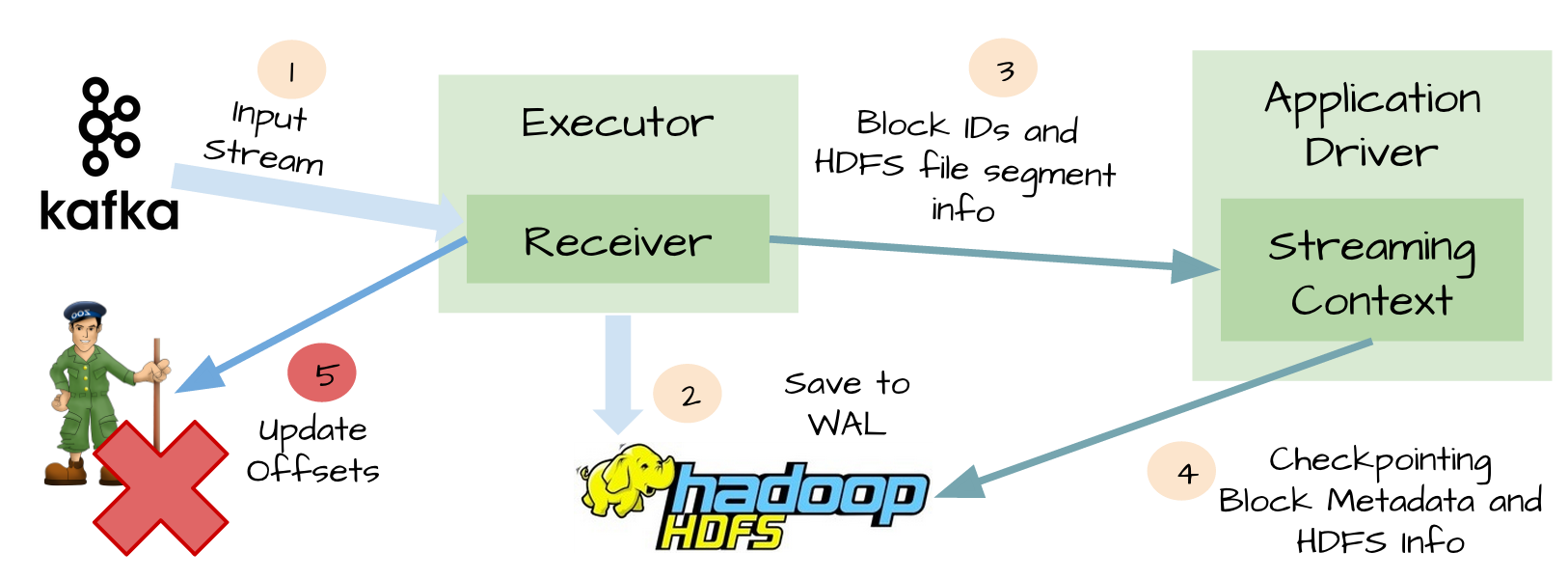
3、Spark Streaming假设输入数据已成功收到(因为它已经写入到WAL中),然而Kafka认为数据被没有被消费,因为相应的偏移量并没有在Zookeeper中更新;
4、过了一会,接收器从失败中恢复;
5、那些被保存到WAL中但未被处理的数据被重新读取;
6、一旦从WAL中读取所有的数据之后,接收器开始从Kafka中消费数据。因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,但是因为接收器挂掉的时候偏移量并没有更新到Zookeeper中,所有有一些数据被处理了2次。
六、WAL的缺点
除了上面描述的场景,WAL还有其他两个不可忽略的缺点:
1、WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中。
2、对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
七、Kafka direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API。
这个想法对于这个特性是非常明智的。Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。

在这个简单但强大的设计中:
1、不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据。
2、不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;
3、exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
Spark Streaming和Kafka整合是如何保证数据零丢失的更多相关文章
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- Spark Streaming和Kafka整合开发指南(二)
在本博客的<Spark Streaming和Kafka整合开发指南(一)>文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据.本文将介绍 ...
- Spark Streaming和Kafka整合开发指南(一)
Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的.本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming与kafka整合实践之WordCount
本次实践使用kafka console作为消息的生产者,Spark Streaming作为消息的消费者,具体实践代码如下 首先启动kafka server .\bin\windows\kafka-se ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
随机推荐
- metasploit魔鬼训练营靶机环境搭建(第二章)
环境搭建,书上已经很详细了,路由转发的那个鼓捣了好久都没弄好,菜的啊 所以先往书后面继续学习,不停留在配置环境上了. backtrack没有下载,使用的kali linux 其他的都是一样的 百度网盘 ...
- justify-content属性详解
justify-content 定义了flexbox flexbox内的元素在主轴的方向上的对齐方式. 它可以设置以下几种对齐方式: 靠近一方 justify-content:center: /*fl ...
- 【科技】单 $\log$ 合并两棵有交集 FHQ-Treap 的方法
维护可分裂 & 合并的可重集 考虑这样一个问题: 维护 \(n\) 个 可重集 \(S_1, S_2, \cdots, S_n\),元素值域为 \([1, U]\),初始集合为空.支持一下操作 ...
- 使用Tomcat Native提升Tomcat IO效率
目录 简介 Tomcat的连接方式 APR和Tomcat Native 在tomcat中使用APR 简介 IO有很多种,从最开始的Block IO,到nonblocking IO,再到IO多路复用和异 ...
- CIBN手机电视8.3.2永久VIP
一款互联网电视的手机客户端.可以观看最新的电影和电视剧,还会为你推荐人气热门电影,让你不会错过每一部精彩的大片,以去除app内的所有可见广告,解锁VIP特权,无需登录直接使用! 下载地址:https: ...
- MySQL PXC集群安装配置
1.关闭防火墙 [root@node04 ~]#systemctl disable firewalld [root@node04 ~]#systemctl stop firewalld [root@n ...
- Jmeter之登录接口参数化实战
为了纪念我走过的坑(为什么有些简单的问题就是绊住我了,还是不够细啊) Jmeter之接口登录参数化实战 因为想要在登录时使用不同的数据进行测试,所以我选择了将数据进行参数化.因为涉及到新建一个接口的功 ...
- Docker(六):Docker安装Kibana
查找Kibana镜像 镜像仓库 https://hub.docker.com/ 下拉镜像 docker pull kibana:7.7.0 查看镜像 docker images 创建Kibana容器 ...
- js上 十、循环语句-1:
十.循环语句-1: 非常之重要. 作用:重复执行一段代码 ü while ü do...while ü for 它们的相同之处,都能够实现循环. 不同的地方,格式不一样,使用的场景略有不同. #10- ...
- [日常摸鱼]UVA393 The Doors 简单计算几何+最短路
The Boy Next Doors 题意:给定一个固定大小的房间($x,y$的范围都是$[0,10]$),有$n$个墙壁作为障碍(都与横坐标轴垂直),每个墙壁都有两扇门分别用四个点来描述,起点 ...