day8 python 列表,元组,集合,字典的操作及方法 和 深浅拷贝
2.2 list的方法
# 增
list.append() # 追加
list.insert() # 指定索引前增加
list.extend() # 迭代追加(可迭代对象,打散追加)
# 删
list.pop() # 指定索引删除(默认删最后一个元素,返回值为删除对象,没有则报错)
list.remove() # 指定元素删除(若有相同元素,默认删除第一个)
list.clear() # 清空
# 其他
list.index() # 获取元素的索引(可指定范围)
list.count() # 获取元素的个数
list.sort() # 排升序
list.sort(revarse = True) # 排降序
list.reverse() # 反转
list.copy() # 复制
3、深浅拷贝
import copy
# 浅拷贝(只拷贝第一层)
lst = [1,2,3,[4,5,6]]
lst1 = lst
lst2 = copy.copy(lst)
lst.append(7)
print(lst1,lst2) # [1, 2, 3, [4, 5, 6], 7] ------ [1, 2, 3, [4, 5, 6]]
lst[3].append(888)
print(lst1,lst2) # [1, 2, 3, [4, 5, 6, 888], 7] ----- [1, 2, 3, [4, 5, 6, 888]]
# 深拷贝
lst = [1,2,3,[4,5,6]]
lst1 = lst
lst2 = copy.deepcopy(lst)
lst.append(7)
print(lst1,lst2) # [1, 2, 3, [4, 5, 6], 7] ----- [1, 2, 3, [4, 5, 6]]
lst[3].append(888)
print(lst1,lst2) # [1, 2, 3, [4, 5, 6, 888], 7] ----- [1, 2, 3, [4, 5, 6]]
4、tuple
tuple.index() # 获取元素的索引(可指定范围)
tuple.count() # 获取元素的个数
5、dict
# 增
dict = {}
lst = ["name","age","happy"]
dict.fromkeys(lst,None) # 创建默认值字典
# 删
dict.pop("key","返回的默认值") # 不设置默认值,没有找到会报错
dict.popitem() # 删除最后一组键值对
dict.clear() # 清空
# 改
dict.updata() # 批量更新
# 查
dict.get("key","返回的默认值") # 不设置默认值,没有找返回None
dict.keys() # 获取所有 key ,返回可迭代对象,非列表
dict.values() # 获取所有 value,返回可迭代对象,非列表
dict.items() # 获取所有键值对 ,返回可迭代对象,非元组
6、set
6.1 set的操作

s1 = {0,1,3,5,7,9}
s2 = {0,2,4,5,6,8}
# 交集 ===== &
s1.intersection(s2) # s1 & s2 ------> {0, 5}
# 查集 ===== -
s1.difference(s2) # s1 - s2 ------> {1, 3, 9, 7}
s2.difference(s1) # s2 - s1 ------> {8, 2, 4, 6}
# 并集 ===== |
s1.union(s2) # s2 | s1 ------> {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
# 对称差集
s1.symmetric_difference(S2) # s2 ^ s1 ------> {1, 2, 3, 4, 6, 7, 8, 9}
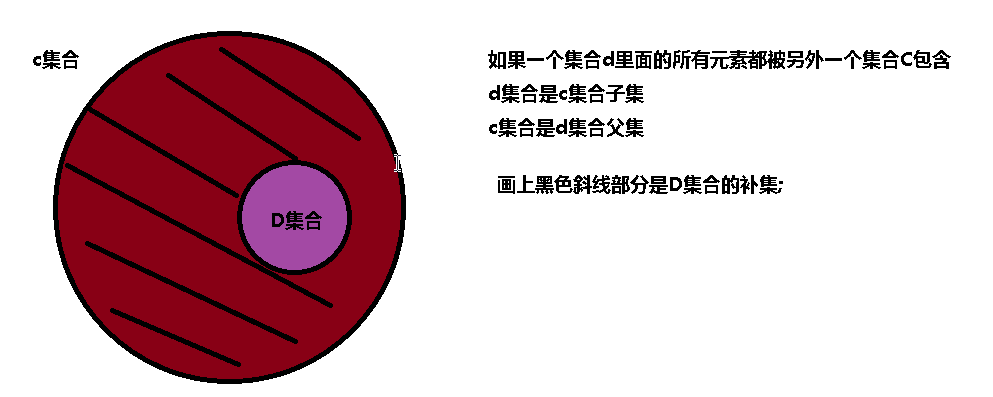
s1 = {1,2,3}
s2 = {1,2,3,4,5,6}
# 判断子集
s1.issubset(s2) # s1 < s2 ------> True
# 判断父级
s1.issuperset(s2) # s1 > s2 ------> False
# 判断是否无相交
s1.isdisjoint(s2) # False
6.2 set 的方法
# 增
set.add() # 单个增加
set.updata() # 迭代增加
# 删
set.pop() # 随机删除
set.remove() # 指定元素删除,不存在会抱错
set.discard() # 指定元素删除,不存在不报错
set.clear() # 清空
6.3 冰冻集合
# 强制转换成frozenset对象,只能做交差并补操作
s1 = [0,1,3,5,7,9]
res = frozenset(s1)
day8 python 列表,元组,集合,字典的操作及方法 和 深浅拷贝的更多相关文章
- Python—列表元组和字典
Python-列表元组和字典 列表 元组 字典 列表: 列表是Python中的一种数据结构,他可以存储不同类型的数据.尽量存储同一种类型 列表索引是从0开始的,我们可以通过索引来访问列表的值. 列表的 ...
- Python成长笔记 - 基础篇 (三)python列表元组、字典、集合
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 一.列表和元组的操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义 ...
- python—列表,元组,字典
——列表:(中括号括起来:逗号分隔每个元素:列表中的元素可以是数字,字符串,列表,布尔值等等) (列表元素可以被修改) list(类) (有序的) [1]索引取值:切片取值:for循环:whi ...
- Python列表元组和字典解析式
目录 列表解析式List comprehensive 集合解析式Set comprehensive 字典解析式Dict comprehensive 总结 以下内容基于Python 3x 列表解析式Li ...
- python列表元组
python列表元组 索引 切片 追加 删除 长度 循环 包含 定义一个列表 my_list = [] my_list = list() my_list = ['Michael', ' ...
- python运算符,数据类型,数据类型操作,三目运算,深浅拷贝
算数运算符: Py2中精确除法需要导入:from __future__ import division,(符由特 ,将来的.滴未省,除法) py3不需要导入 赋值运算符: 比较运算符: 成员运算符: ...
- Python 入门之代码块、小数据池 与 深浅拷贝
Python 入门之代码块.小数据池 与 深浅拷贝 1.代码块 (1)一个py文件,一个函数,一个模块,终端中的每一行都是代码块 (代码块是防止我们频繁的开空间降低效率设计的,当我们定一个变量需要开辟 ...
- Python列表,元组,字典,集合详细操作
菜鸟学Python第五天 数据类型常用操作及内置方法 列表(list) ======================================基本使用====================== ...
- python3笔记十八:python列表元组字典集合文件操作
一:学习内容 列表元组字典集合文件操作 二:列表元组字典集合文件操作 代码: import pickle #数据持久性模块 #封装的方法def OptionData(data,path): # ...
随机推荐
- CentOS Linux release 7.7.1908 (Core)--redis安装
1.通过filezilla把安装包扔到linux上,建立一个redis 的目录 2.解压 tar -zxvf redis-4.0.6.tar.gz 3. yum安装gcc依赖 yum install ...
- 贪吃蛇游戏(printf输出C语言版本)
这一次我们应用printf输出实现一个经典的小游戏—贪吃蛇,主要难点是小蛇数据如何存储.如何实现转弯的效果.吃到食物后如何增加长度. 1 构造小蛇 首先,在画面中显示一条静止的小蛇.二维数组canva ...
- Spring整合JDBC temple
一.Spring对Jdbc的支持 Spring为了提供对Jdbc的支持,在Jdbc API的基础上封装了一套实现,以此建立一个 JDBC 存取框架. 作为 Spring JDBC 框架的核心, JDB ...
- 虹软AI 人脸识别SDK接入 — 参数优化篇
引言 使用了免费的人脸识别算法,感觉还是很不错的,但是初次接触的话会对一些接口的参数有些疑问的.这里分享一下我对一些参数的验证结果(这里以windows版本为例,linux.android基本一样), ...
- 初识MQ消息队列
MQ 消息队列 消息队列(Message Queue)简称MQ,是阿里巴巴集团中间件技术部自主研发的专业消息中间件. 产品基于高可用分布式集群技术,提供消息发布订阅.消息轨迹查询.定时(延时)消息.资 ...
- Java 中的数据结构类 Vector 和 ArrayList
今天刷算法题目时,使用到了 Java 的内置栈类 Stack,好奇它是怎么实现的,发现它是继承于 Vector 这个类.那么,就先学习下 Vector 这个类的实现吧! Vector 和 ArrayL ...
- 使用JUnit 和Jacoco进行单元测试
Jacoco配置 <dependency> <groupId>org.jacoco</groupId> <artifactId>jacoco-maven ...
- android面试详解
前台就是和用户交互的进程 可见进程例如一个activity被一个透明的对话框覆盖,该activity就是可见进程 服务:service进程 后台一个activity按了home按键就是从前台退回到后台 ...
- nmap二层发现
使用nmap进行arp扫描要使用一个参数:-sn,该参数表明屏蔽端口扫描而只进行arp扫描. nmap支持ip段扫描,命令:nmap -sn 192.168.1.0/24 nmap速度比arping快 ...
- ABP(ASP.NET Boilerplate Project)快速入门
前言 这两天看了一下ABP,做个简单的学习记录.记录主要有以下内容: 从官网创建并下载项目(.net core 3.x + vue) 项目在本地成功运行 新增实体并映射到数据库 完成对新增实体的基本增 ...