MPI聚合函数
MPI聚合通信
- MPI_Barrier
int MPI_Barrier(
MPI_Comm comm
);
所有在该通道的函数都执行完后,才开始其他步骤。

0进程在状态T1调用MPI_Barrier函数,并在该位置挂起,等待其他进程到达。最后在T4状态同时进行。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nprocs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Barrier(MPI_COMM_WORLD);
printf("Hello,world,I am %d of %d\n", rank, nprocs);
MPI_Finalize();
return 0;
}
- MPI_Bcast
int MPI_Bcast(
void *buffer,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm comm
);
广播函数,root表示要广播的进程。发送和接收进程都需要写该函数。
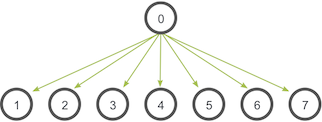
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank,nproc;
int ibuf;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) ibuf = 8888;
else ibuf = 0;
MPI_Bcast(&ibuf, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
printf("rank = %d ibuf = %d\n", rank, ibuf);
}
MPI_Finalize();
return 0;
}
- MPI_Gather
int MPI_Gather(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
每个进程(包括root进程)都要发送buffer给root进程,root进程接收到这些buffer并且按照顺序排好序。
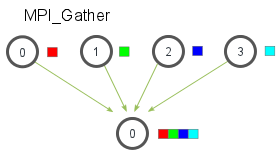
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int isend, irecv[32];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
isend = rank + 1;
MPI_Gather(&isend, 1, MPI_INT, irecv, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
printf("%d \n", irecv[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Gatherv
int MPI_Gatherv(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int *recvcnts,
int *displs,// 接收的数据放在说明位置,即位移。
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
是MPI_Gather函数的一个扩展,recvcnts是数组,允许每个进程的数量不同,而且每个进程的位置更灵活。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
//这里为了简单,假设有4个进程。
int send_buffer[6];
int recv_buffer[6];
int rank, nproc;
int receive_counts[4] = { 0,1,2,3 };
int receive_disp[4] = { 0,0,1,3 };//偏移数组
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
//初始化数据
for (int i = 0; i < rank; i++)
{
send_buffer[i] = rank;
recv_buffer[i] = rank+1;
}
MPI_Gatherv(send_buffer, rank, MPI_INT, recv_buffer, receive_counts, receive_disp, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 6; i++)
{
printf("[%d]", recv_buffer[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Scatter
int MPI_Scatter(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
MPI_Scatter与MPI_Bcast非常相似,都是一对多的通信方式,不同的是后者的0号进程将相同的信息发送给所有的进程,而前者则是将一段array 的不同部分发送给所有的进程。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
#define MAX_PRO 10//最大进程数
int main(int argc, char* argv[])
{
int rank, nproc;
int table[MAX_PRO][MAX_PRO];
int row[MAX_PRO];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
for (int j = 0; j < MAX_PRO; j++)
{
table[i][j] = i + j;
}
}
}
MPI_Scatter(&table[0][0], MAX_PRO, MPI_INT, &row[0], MAX_PRO, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
for (int i = 0; i < MAX_PRO; i++)
{
printf("%d ", row[i]);
}
printf("processs of %d\n",rank);
}
MPI_Finalize();
return 0;
}
- MPI_Alltoall
int MPI_Alltoall(
void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
);
当前进程向其他每个进程(包括自己)要发送数据,都是发送sendbuf中的数据。接收到不同进程的数据。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int send[1];
int recv[10];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
send[0] = rank*rank;
for (int i = 0; i < 10; i++)
{
recv[i] = 0;
}
MPI_Alltoall(&send, 1, MPI_INT, recv, 1, MPI_INT, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 10; i++)
{
printf("%d ", recv[i]);
}
}
MPI_Finalize();
return 0;
}
MPI归约操作
- MPI_Reduce
int MPI_Reduce(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm comm
);
MPI_Op有如下类型:
| 运算操作符 | 描述 | 运算操作符 | 描述 |
|---|---|---|---|
| MPI_MAX | 最大值 | MPI_LOR | 逻辑或 |
| MPI_MIN | 最小值 | MPI_BOR | 位与 |
| MPI_SUM | 求和 | MPI_LXOR | 逻辑异或 |
| MPI_PROD | 求积 | MPI_BXOP | 位异或 |
| MPI_LAND | 逻辑与 | MPI_MINLOC | 计算一个全局最小值 |
| MPI_BAND | 位与 | MPI_MAXLOC | 计算一个全局最大值 |
将通信子内各进程的同一个变量参与规约计算,并向指定的进程输出计算结果。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Reduce(&send, &recv, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("%d", recv);
}
MPI_Finalize();
return 0;
}
- MPI_Scan
int MPI_Scan(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
前缀和函数 MPI_Scan(),将通信子内各进程的同一个变量参与前缀规约计算,并将得到的结果发送回每个进程,使用与函数 MPI_Reduce() 相同的操作类型。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Scan(&send, &recv, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("the %d process is %d", rank, recv);
MPI_Finalize();
return 0;
}
- MPI_Reduce_scatter
int MPI_Reduce_scatter(
void *sendbuf,
void *recvbuf,
int *recvcnts,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
将规约结果分片发送到各进程.
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char** argv)
{
int* sendbuf, recvbuf, * recvcounts;
int size, rank;
MPI_Comm comm;
MPI_Init(&argc, &argv);
comm = MPI_COMM_WORLD;
MPI_Comm_size(comm, &size);
MPI_Comm_rank(comm, &rank);
sendbuf = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
sendbuf[i] = i;
recvcounts = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
recvcounts[i] = 1;
MPI_Reduce_scatter(sendbuf, &recvbuf, recvcounts, MPI_INT, MPI_SUM, comm);
printf("the %d process is %d", rank, recvbuf);
MPI_Finalize();
return 0;
}
MPI聚合函数的更多相关文章
- 可以这样去理解group by和聚合函数
写在前面的话:用了好久group by,今天早上一觉醒来,突然感觉group by好陌生,总有个筋别不过来,为什么不能够select * from Table group by id,为什么一定不能是 ...
- TSQL 聚合函数忽略NULL值
max,min,sum,avg聚合函数会忽略null值,但不代表聚合函数不返回null值,如果表为空表,或聚合列都是null,则返回null.count 聚合函数忽略null值,如果聚合列都是null ...
- SQL Server 聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值 ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
- sql语句 之聚合函数
聚合分析 在访问数据库时,经常需要对表中的某列数据进行统计分析,如求其最大值.最小值.平均值等.所有这些针对表中一列或者多列数据的分析就称为聚合分析. 在SQL中,可以使用聚合函数快速实现数据的聚 ...
- oracle数据库函数之============‘’分析函数和聚合函数‘’
1分析函数 分析函数根据一组行来进行聚合计算,用于计算完成狙击的累积排名等,分析函数为每组记录返回多个行 rank_number() 查询结果按照次序排列,不存在并列和站位的情况,可以用于做Oracl ...
- ORACLE 自定义聚合函数
用户可以自定义聚合函数 ODCIAggregate,定义了四个聚集函数:初始化.迭代.合并和终止. Initialization is accomplished by the ODCIAggrega ...
- sql 聚合函数、排序方法详解
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排 ...
- SQL Server 自定义聚合函数
说明:本文依据网络转载整理而成,因为时间关系,其中原理暂时并未深入研究,只是整理备份留个记录而已. 目标:在SQL Server中自定义聚合函数,在Group BY语句中 ,不是单纯的SUM和MAX等 ...
随机推荐
- Springboot 多数据源配置,结合tk-mybatis
一.前言 作为一个资深的CRUD工程师,我们在实际使用springboot开发项目的时候,难免会遇到同时使用多个数据库的情况,比如前脚刚查询mysql,后脚就要查询sqlserver. 这时,我们很直 ...
- matplotlib 去掉坐标轴
#去掉x轴 plt.xticks([]) #去掉y轴 plt.yticks([]) #去掉坐标轴 plt.axis('off') 2020-06-26
- Django学习路25_ifequal 和 ifnotequal 判断数值是否相等及加减法 {{数值|add 数值}}
{% ifequal 数值 数值 %} <body> {# 判断是否相等 #} num 当前的值 {{ num }}<br/> {% ifequal num 5 %} {# 判 ...
- Python os.readlink() 方法
概述 os.readlink() 方法用于返回软链接所指向的文件.可能返回绝对或相对路径.高佣联盟 www.cgewang.com 在Unix中有效 语法 readlink()方法语法格式如下: os ...
- PHP xml_set_element_handler() 函数
定义和用法 xml_set_element_handler() 函数规定在 XML 文档中元素的起始和终止调用的函数. 如果成功,该函数则返回 TRUE.如果失败,则返回 FALSE.高佣联盟 www ...
- PHP mysqli_thread_safe() 函数
定义和用法 mysqli_thread_safe() 函数返回是否将客户端库编译成 thread-safe. 语法 mysqli_thread_safe();高佣联盟 www.cgewang.com ...
- P5979 [PA2014]Druzyny dp 分治 线段树 分类讨论 启发式合并
LINK:Druzyny 这题研究了一下午 终于搞懂了. \(n^2\)的dp很容易得到. 考虑优化.又有大于的限制又有小于的限制这个非常难处理. 不过可以得到在限制人数上界的情况下能转移到的最远端点 ...
- luogu P2510 [HAOI2008]下落的圆盘
LINK:下落的圆盘 计算几何.n个圆在平面上编号大的圆将编号小的圆覆盖求最后所有没有被覆盖的圆的边缘的总长度. 在做这道题之前有几个前置知识. 极坐标系:在平面内 由极点 极轴 和 极径组成的坐标系 ...
- SparkBench安装使用入门
SparkBench安装以及快速开始 欢迎关注我的GitHub~ 本指南假定已经可以正常使用Spark 2.x,并且可以访问安装它的系统. 系统环境 CentOS 7.7.1908 Ambari-Sp ...
- 教你如何使用零代码开发的Foreach循环功能代替for循环
使用技巧:Foreach循环功能! 项目中为了避免将同样的语句重复写很多次,相信大家在编程过程中肯定用过循环语句.其中For循环作为基础中的基础,大家一定不会陌生.不过今天小V要讲的可不是For循环, ...