求lca(模板)
洛谷——P3379 【模板】最近公共祖先(LCA)
题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入输出格式
输入格式:
第一行包含三个正整数N、M、S,分别表示树的结点个数、询问的个数和树根结点的序号。
接下来N-1行每行包含两个正整数x、y,表示x结点和y结点之间有一条直接连接的边(数据保证可以构成树)。
接下来M行每行包含两个正整数a、b,表示询问a结点和b结点的最近公共祖先。
输出格式:
输出包含M行,每行包含一个正整数,依次为每一个询问的结果。
输入输出样例
5 5 4 3 1 2 4 5 1 1 4 2 4 3 2 3 5 1 2 4 5
4 4 1 4 4
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,M<=10
对于70%的数据:N<=10000,M<=10000
对于100%的数据:N<=500000,M<=500000
样例说明:
该树结构如下:
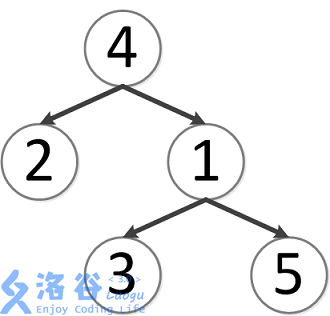
第一次询问:2、4的最近公共祖先,故为4。
第二次询问:3、2的最近公共祖先,故为4。
第三次询问:3、5的最近公共祖先,故为1。
第四次询问:1、2的最近公共祖先,故为4。
第五次询问:4、5的最近公共祖先,故为4。
故输出依次为4、4、1、4、4。
我的这几种做法都是70分,tle,这个题卡vec,把它改掉就好了,由于本人太懒,就暂且不改了
1.用倍增法。
代码:
#include<vector>
#include<stdio.h>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define N 500001
#define maxn 123456
using namespace std;
vector<int>vec[N];
int n,x,y,fa[N][20],deep[N],m,root;
void dfs(int x)
{
deep[x]=deep[fa[x][]]+;
;fa[x][i];i++)
fa[x][i+]=fa[fa[x][i]][i];
;i<vec[x].size();i++)
{
if(!deep[vec[x][i]])
{
fa[vec[x][i]][]=x;
dfs(vec[x][i]);
}
}
}
int lca(int x,int y)
{
if(deep[x]>deep[y])
swap(x,y);//省下后面进行分类讨论,比较方便
;i--)
{
if(deep[fa[y][i]]>=deep[x])
y=fa[y][i];//让一个点进行倍增,直到这两个点的深度相同
}
if(x==y) return x;//判断两个点在一条链上的情况
;i--)
{
if(fa[x][i]!=fa[y][i])
{
y=fa[y][i];
x=fa[x][i];
}
}
];//这样两点的父亲就是他们的最近公共祖先
}
int main()
{
scanf("%d%d%d",&n,&m,&root);
;i<n;i++)
{
scanf("%d%d",&x,&y);
vec[x].push_back(y);
vec[y].push_back(x);
}
deep[root]=;
dfs(root);
;i<=m;i++)
{
scanf("%d%d",&x,&y);
printf("%d\n",lca(x,y));
}
;
}
2.树剖法
#include<vector>
#include<stdio.h>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define N 500001
#define maxn 123456
using namespace std;
vector<int>vec[N];
int n,m,root,x,y,fa[N],deep[N],size[N],top[N];
int lca(int x,int y)
{
for( ;top[x]!=top[y];)
{
if(deep[top[x]]<deep[top[y]])
swap(x,y);
x=fa[x];
}
if(deep[x]>deep[y])
swap(x,y);
return x;
}
void dfs(int x)
{
size[x]=;
deep[x]=deep[fa[x]]+;
;i<vec[x].size();i++)
{
if(fa[x]!=vec[x][i])
{
fa[vec[x][i]]=x;
dfs(vec[x][i]);
size[x]+=size[vec[x][i]];
}
}
}
void dfs1(int x)
{
;
if(!top[x]) top[x]=x;
;i<vec[x].size();i++)
if(vec[x][i]!=fa[x]&&size[vec[x][i]]>size[t])
t=vec[x][i];
if(t)
{
top[t]=top[x];
dfs1(t);
}
;i<vec[x].size();i++)
if(vec[x][i]!=fa[x]&&vec[x][i]!=t)
dfs1(vec[x][i]);
}
int main()
{ scanf("%d%d%d",&n,&m,&root);
;i<n;i++)
{
scanf("%d%d",&x,&y);
vec[x].push_back(y);
vec[y].push_back(x);
}
dfs(root);
dfs1(root);
;i<=m;i++)
{
scanf("%d%d",&x,&y);
printf("%d\n",lca(x,y));
}
;
}
3.tarjian法
#include<vector>
#include<stdio.h>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<algorithm>
#define N 500001
using namespace std;
vector<int>vec[N],que[N];
int n,m,qx[N],qy[N],x,y,root,fa[N],dad[N],ans[N];
int find(int x)
{
return fa[x]==x?x:fa[x]=find(fa[x]);
}
void dfs(int x)
{
fa[x]=x;
;i<vec[x].size();i++)
if(vec[x][i]!=dad[x])
dad[vec[x][i]]=x,dfs(vec[x][i]);
;i<que[x].size();i++)
if(dad[y=qx[que[x][i]]^qy[que[x][i]]^x])
ans[que[x][i]]=find(y);
fa[x]=dad[x];
}
int main()
{
scanf("%d%d%d",&n,&m,&root);
;i<n;i++)
{
scanf("%d%d",&x,&y);
vec[x].push_back(y);
vec[y].push_back(x);
}
;i<=m;i++)
{
scanf("%d%d",&qx[i],&qy[i]);
que[qx[i]].push_back(i);
que[qy[i]].push_back(i);
}
dfs(root);
;i<=m;i++)
printf("%d\n",ans[i]);
;
}
求lca(模板)的更多相关文章
- 倍增求lca模板
倍增求lca模板 https://www.luogu.org/problem/show?pid=3379 #include<cstdio> #include<iostream> ...
- tarjan求lca 模板
#include <iostream> #include <cstdio> #include <sstream> #include <cstring> ...
- 倍增求lca(模板)
定义LCA,最近公共祖先,是指一棵树上两个节点的深度最大的公共祖先.也可以理解为两个节点之间的路径上深度最小的点.我们这里用了倍增的方法求了LCA.我们的基本的思路就是,用dfs遍历求出所有点的深度. ...
- 求LCA最近公共祖先的在线倍增算法模板_C++
倍增求 LCA 是在线的,而且比 ST 好写多了,理解起来比 ST 和 Tarjan 都容易,于是就自行脑补吧,代码写得容易看懂 关键理解 f[i][j] 表示 i 号节点的第 2j 个父亲,也就是往 ...
- 倍增求LCA学习笔记(洛谷 P3379 【模板】最近公共祖先(LCA))
倍增求\(LCA\) 倍增基础 从字面意思理解,倍增就是"成倍增长". 一般地,此处的增长并非线性地翻倍,而是在预处理时处理长度为\(2^n(n\in \mathbb{N}^+)\ ...
- 【模板】Tarjian求LCA
概念 公共祖先,就是两个节点在这棵树上深度最大的公共的祖先节点 举个例子吧,如下图所示4和5的最近公共祖先是2,5和3的最近公共祖先是1,2和1的最近公共祖先是1. 算法 常用的求LCA的算法有:Ta ...
- 树链剖分求LCA
树链剖分中各种数组的作用: siz[]数组,用来保存以x为根的子树节点个数 top[]数组,用来保存当前节点的所在链的顶端节点 son[]数组,用来保存重儿子 dep[]数组,用来保存当前节点的深度 ...
- POJ 1330 Nearest Common Ancestors(LCA模板)
给定一棵树求任意两个节点的公共祖先 tarjan离线求LCA思想是,先把所有的查询保存起来,然后dfs一遍树的时候在判断.如果当前节点是要求的两个节点当中的一个,那么再判断另外一个是否已经访问过,如果 ...
- 树上倍增求LCA及例题
先瞎扯几句 树上倍增的经典应用是求两个节点的LCA 当然它的作用不仅限于求LCA,还可以维护节点的很多信息 求LCA的方法除了倍增之外,还有树链剖分.离线tarjan ,这两种日后再讲(众人:其实是你 ...
- tarjan,树剖,倍增求lca
1.tarjan求lca 思想: void tarjan(int u,int f){ for(int i=---){//枚举边 if(v==f) continue; dfs(v); //继续搜 uni ...
随机推荐
- GoF23种设计模式之结构型模式之代理模式
一.概述 为其他对象提供一种代理以控制对这个对象的访问. 二.适用性 1.远程代理(RemoteProxy):为一个对象在不同的地址空间土工局部代表. 2.虚代理(VirtualProxy):根据需要 ...
- Windows Bash on Ubuntu
windows Bash on Ubuntu, 之前就是尝试一下,更多是在不安装虚拟机的情况下,学下 bash. 这几天,在 上面 make u-boot,这个用起来比 cygwin方便多了. 之前在 ...
- LeetCode(228) Summary Ranges
题目 Given a sorted integer array without duplicates, return the summary of its ranges. For example, g ...
- socketserver源码剖析
作者:人世间链接:https://www.jianshu.com/p/357e436936bf來源:简书简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处 BaseServer 和 B ...
- Eclipse下创建Spring MVC web程序--maven版
1. 创建一个maven工程: File->New->Other... 2. 创建完成后的结构如下: 3. 配置pom.xml文件,添加spring-webmvc依赖项 <pro ...
- 【LeetCode】Balanced Binary Tree(平衡二叉树)
这道题是LeetCode里的第110道题. 题目要求: 给定一个二叉树,判断它是否是高度平衡的二叉树. 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1. ...
- 九度oj 题目1085:求root(N, k) 清华2010年机试题目
题目描述: N<k时,root(N,k) = N,否则,root(N,k) = root(N',k).N'为N的k进制表示的各位数字之和.输入x,y,k,输出root(x^y,k)的值 (这里^ ...
- Python杂技
py转exe文件 用 pyinstaller,可以把所有文件打包成一个单独的exe文件 win10X64 =>pip install pyinstaller pyinstaller [参数] [ ...
- oracle查询包含大小写的数据
查询包含小写的所有数据: select oper_no from info_oper where regexp_like(oper_no,'[[:lower:]]'); select oper_no ...
- 【Luogu】P2053修车(费用流)
题目链接 早上状态不好,虚树搞崩只好来刷网络流了qwq. (然后我犹豫几秒之后看了题解) 使用拆点大法把工人拆成n*m个点,然后每个点代表每个时间段的工人, 然后从车到每个工人点连一条边,权值是耽误的 ...