D. Mike and distribution 首先学习了一个玄学的东西
http://codeforces.com/contest/798/problem/D
2 seconds
256 megabytes
standard input
standard output
Mike has always been thinking about the harshness of social inequality. He's so obsessed with it that sometimes it even affects him while solving problems. At the moment, Mike has two sequences of positive integersA = [a1, a2, ..., an] and B = [b1, b2, ..., bn] of length n each which he uses to ask people some quite peculiar questions.
To test you on how good are you at spotting inequality in life, he wants you to find an "unfair" subset of the original sequence. To be more precise, he wants you to select k numbers P = [p1, p2, ..., pk] such that 1 ≤ pi ≤ n for1 ≤ i ≤ k and elements in P are distinct. Sequence P will represent indices of elements that you'll select from both sequences. He calls such a subset P "unfair" if and only if the following conditions are satisfied: 2·(ap1 + ... + apk)is greater than the sum of all elements from sequence A, and 2·(bp1 + ... + bpk) is greater than the sum of all elements from the sequence B. Also, k should be smaller or equal to 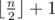 because it will be to easy to find sequence P if he allowed you to select too many elements!
because it will be to easy to find sequence P if he allowed you to select too many elements!
Mike guarantees you that a solution will always exist given the conditions described above, so please help him satisfy his curiosity!
The first line contains integer n (1 ≤ n ≤ 105) — the number of elements in the sequences.
On the second line there are n space-separated integers a1, ..., an (1 ≤ ai ≤ 109) — elements of sequence A.
On the third line there are also n space-separated integers b1, ..., bn (1 ≤ bi ≤ 109) — elements of sequence B.
On the first line output an integer k which represents the size of the found subset. k should be less or equal to 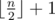 .
.
On the next line print k integers p1, p2, ..., pk (1 ≤ pi ≤ n) — the elements of sequence P. You can print the numbers in any order you want. Elements in sequence P should be distinct.
5
8 7 4 8 3
4 2 5 3 7
3
1 4 5
用了一个叫random_shuffle的东西,每次都乱选,然后暴力前k个。
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cmath>
#include <algorithm>
#include <assert.h>
#define IOS ios::sync_with_stdio(false)
using namespace std;
#define inf (0x3f3f3f3f)
typedef long long int LL; #include <iostream>
#include <sstream>
#include <vector>
#include <set>
#include <map>
#include <queue>
#include <string>
#include <bitset>
const int maxn = 1e5 + ;
int a[maxn], b[maxn]; bool in[maxn];
LL sumA, sumB;
LL allA, allB;
int c[maxn];
int n, en;
bool ok() {
LL ta = , tb = ;
for (int i = ; i <= en; ++i) {
ta += * a[c[i]];
tb += * b[c[i]];
if (ta > allA && tb > allB) return true;
}
return false;
}
void work() {
cin >> n;
for (int i = ; i <= n; ++i) {
scanf("%d", &a[i]);
allA += a[i];
}
for (int i = ; i <= n; ++i) {
scanf("%d", &b[i]);
allB += b[i];
c[i] = i;
}
en = (n) / + ;
while (!ok()) {
random_shuffle(c + , c + + n);
// for (int i = 1; i <= n; ++i) {
// cout << c[i] << " ";
// }
// cout << endl;
}
cout << en<< endl;
for (int i = ; i <= en; ++i) {
printf("%d ", c[i]);
}
} int main() {
#ifdef LOCAL
freopen("data.txt", "r", stdin);
// freopen("data.txt", "w", stdout);
#endif
work();
return ;
}
正解:
首先注意到,选出n / 2 + 1个数,2倍的和大于总和,等价于选出n / 2 + 1个数,总和大于剩下的数。
因为可以取n / 2 + 1个,那么先对A排序,B不动,先把A[1]选了(这个是用在证明A数组成立用的),A【1】是当前A中最大的了。当然了也选了一个B,就是选了B[A[1].id],
然后每两个做一pair,选一个比较大的B,也就是max(B[A[i].id], B[A[i + 1].id])
这样,B数组是满足的,这很容易证明,因为没一对中,都选了一个较大的。然后加上第一个,总和肯定大于剩下 的。
也就是
max(b[1], b[2]) >= min(b[1], b[2])
max(b[3], b[4]) >= min(b[3], b[4])
max(b[5], b[6]) >= min(b[5], b[6])
那么全部相加,不等号方向不变。而且开头还有一个b[A[1].id]加了进来,所以是严格大于的。
再来看看A的证明。
第一是选了a[1]
然后选a[2]和a[3]的那个呢?不固定的,还要看B,但是不管,有以下不等式。
a[1] >= any(a[2], a[3])
any(a[2], a[3]) >= any(a[4], a[5])
any(a[4], a[5]) >= any(a[5], a[6])
也就是,你选了一个a[1],然后a[2]和a[3]选那个是没关系的,可以用a[1]和它比较,然后又因为选了any(a[2], a[3]),那么你a[4]和a[5]选那个是没所谓的,因为可以用any(a[2], a[3])和它比较。
最后,any(a[n - 1], a[n]) > 0,所以是严格大于的。
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cmath>
#include <algorithm>
#include <assert.h>
#define IOS ios::sync_with_stdio(false)
using namespace std;
#define inf (0x3f3f3f3f)
typedef long long int LL; #include <iostream>
#include <sstream>
#include <vector>
#include <set>
#include <map>
#include <queue>
#include <string>
#include <bitset>
const int maxn = 1e5 + ;
struct Node {
int a, id;
bool operator < (const struct Node & rhs) const {
return a > rhs.a;
}
}a[maxn];
int b[maxn];
vector<int>ans;
void work() {
int n;
cin >> n;
for (int i = ; i <= n; ++i) {
cin >> a[i].a;
a[i].id = i;
}
for (int i = ; i <= n; ++i) {
cin >> b[i];
}
sort(a + , a + + n);
int sel = n / + ;
ans.push_back(a[].id);
for (int i = ; i <= n; i += ) {
int want = a[i].id;
if (i + <= n && b[want] < b[a[i + ].id]) {
want = a[i + ].id;
}
ans.push_back(want);
}
cout << ans.size() << endl;
for (int i = ; i < ans.size(); ++i) {
cout << ans[i] << " ";
}
} int main() {
#ifdef local
freopen("data.txt", "r", stdin);
// freopen("data.txt", "w", stdout);
#endif
IOS;
work();
return ;
}
2017-4-23 22:22:03
要开始补sg函数(博弈)和构造题。先复习下字符串准备省赛。
D. Mike and distribution 首先学习了一个玄学的东西的更多相关文章
- codeforces 798 D. Mike and distribution
D. Mike and distribution time limit per test 2 seconds memory limit per test 256 megabytes input sta ...
- CF798D Mike and distribution
CF798D Mike and distribution 洛谷评测传送门 题目描述 Mike has always been thinking about the harshness of socia ...
- [深度学习]实现一个博弈型的AI,从五子棋开始(1)
好久没有写过博客了,多久,大概8年???最近重新把写作这事儿捡起来……最近在折腾AI,写个AI相关的给团队的小伙伴们看吧. 搞了这么多年的机器学习,从分类到聚类,从朴素贝叶斯到SVM,从神经网络到深度 ...
- [深度学习]实现一个博弈型的AI,从五子棋开始(2)
嗯,今天接着来搞五子棋,从五子棋开始给小伙伴们聊AI. 昨天晚上我们已经实现了一个五子棋的逻辑部分,其实讲道理,有个规则在,可以开始搞AI了,但是考虑到不够直观,我们还是顺带先把五子棋的UI也先搞出来 ...
- 学习建一个spring-Mvc项目
学习建一个spring-Mvc项目 首先要有jdk1.8以上,spring,mybatis,以及整合jar包,tomcat ,然后配置环境(前面有配置得方法). 1)右键new project,--& ...
- 6、GNU makefile工程管理学习的一个例子
在之前我们已经学习了一个文件的编译过程,但是做过项目的都知道,一个工程中的源文件不计其数,其按类型.功能.模块会分别放在若干个目录中,而这些文件如何编译就需要有一个编译规则,虽然现在很多大型的项目都是 ...
- PDNN: 深度学习的一个Python工具箱
PDNN: 深度学习的一个Python工具箱 PDNN是一个在Theano环境下开发出来的一个Python深度学习工具箱.它由苗亚杰(Yajie Miao)原创.现在仍然在不断努力去丰富它的功能和扩展 ...
- #410div2D. Mike and distribution
D. Mike and distribution time limit per test 2 seconds memory limit per test 256 megabytes input sta ...
- Codeforces 798D Mike and distribution(贪心或随机化)
题目链接 Mike and distribution 题目意思很简单,给出$a_{i}$和$b_{i}$,我们需要在这$n$个数中挑选最多$n/2+1$个,使得挑选出来的 $p_{1}$,$p_{2} ...
随机推荐
- Linux_异常_01_CentOS7无法ping 百度
一.原因 vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no B ...
- kettle每天自动发送邮件总结_20161128
kettle作为java开发的工具,很多功能在目前工作中还用不到,原来它也是支持java代码的,现在用到的也就是它从服务器导数到数据库,然后再进行数据处理的功能. 如何快速学会使用kettle发送邮件 ...
- ACM学习历程—POJ1151 Atlantis(扫描线 && 线段树)
Description There are several ancient Greek texts that contain descriptions of the fabled island Atl ...
- 【Lintcode】062.Search in Rotated Sorted Array
题目: Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 ...
- VirtualBox文件系统已满--磁盘扩容
第1步:为virtualbox虚拟电脑扩容 进入命令行,以Windows系统为例 (特别注意空格和中文) 1.启动CMD命令行,进入VirtualBox的安装目录.如 运行:cmd C:\Users\ ...
- 相对路径转绝对路径C++实现
#include<iostream> #include<string> #include<vector> using namespace std; //相对路径转绝 ...
- HL7 Event Type
Table 0003 - Event type Value Description A01 ADT/ACK - Admit / visit notification A02 ADT/ACK - Tra ...
- JS极品日历
<!DOCTYPE><html><head><meta http-equiv="Content-Type" content="t ...
- 转:使用 VisualVM 进行性能分析及调优
使用 VisualVM 进行性能分析及调优 VisualVM 是一款免费的\集成了多个 JDK 命令行工具的可视化工具,它能为您提供强大的分析能力,对 Java 应用程序做性能分析和调优.这些功能包括 ...
- php使用curl带cookie访问一直失败求助
最近需要批量向织梦后台导入一些数据,但是遇到了一个头疼的问题. 环境:xampp + 别人的dede后台. 首先,利用curl发送post请求登录login.php,成功,并且保存了cookie文件. ...