python爬取+使用网易卡搭作品数量api
第一步,当然是打开浏览器~
然后打开卡搭~
看着熟悉的界面,是不是有点不知所措?
这就对了,咱找点事情干干。

随便找个倒霉蛋,比如这位:“混世大王”,打开他的主页!
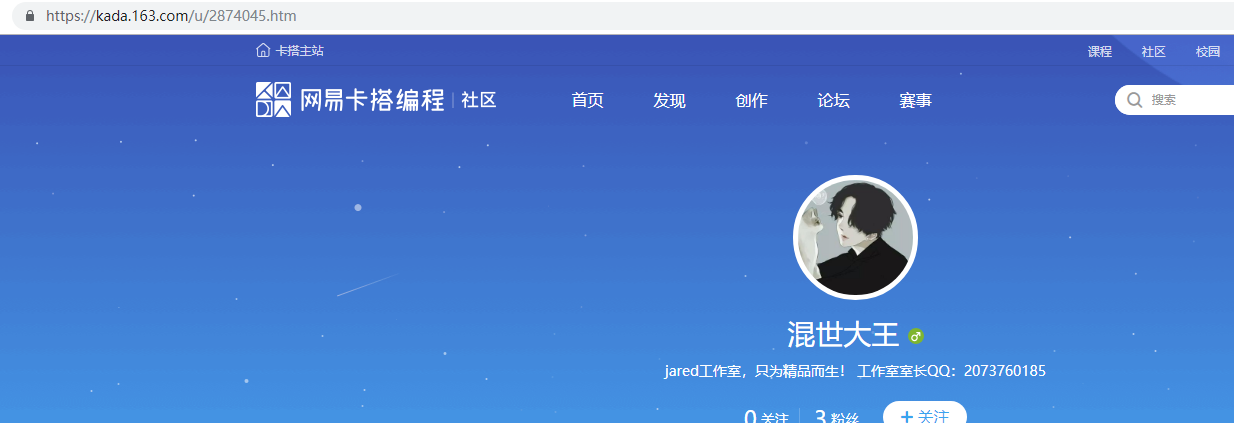
按下f12(我这个是chrome,别的浏览器可能不一样),选进“network",ctrl+r刷新;

在过滤器里选”XHR“,从第一个往下看,如果代码是下图这样的,那就右键在新标签页打开,能看到api返回的数据。
如果不是,就点下一个;
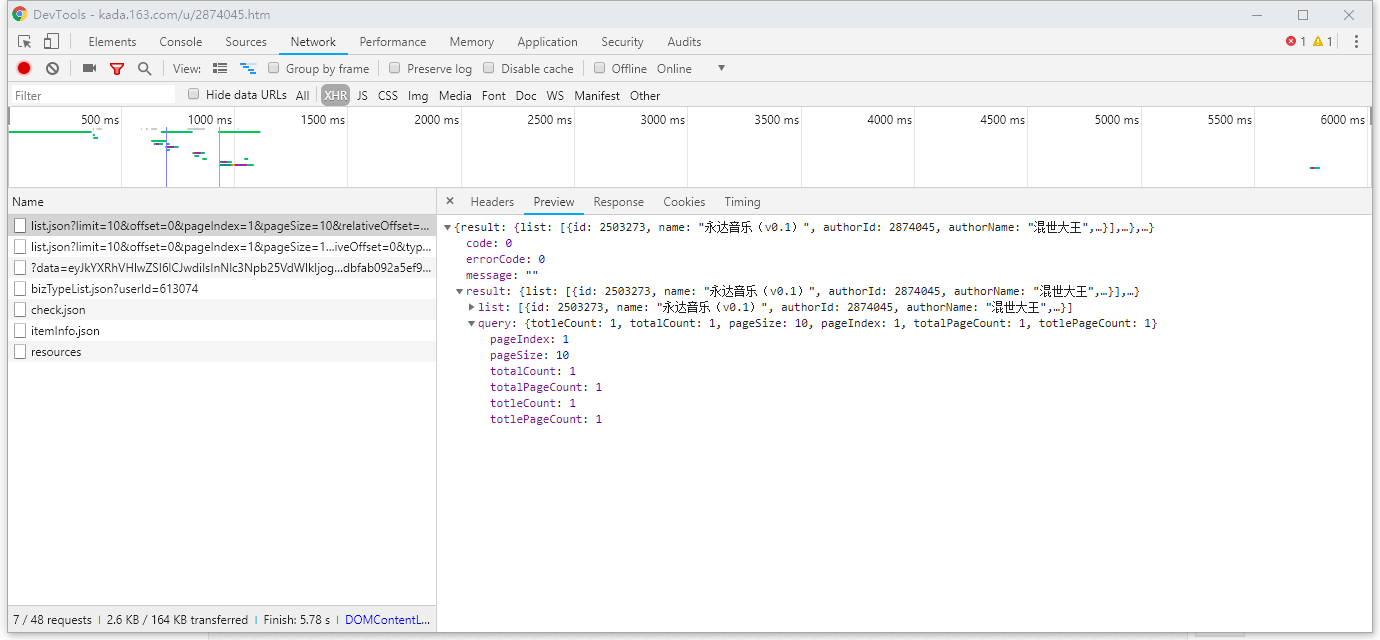
让我们仔细观察一下API返回的数据:
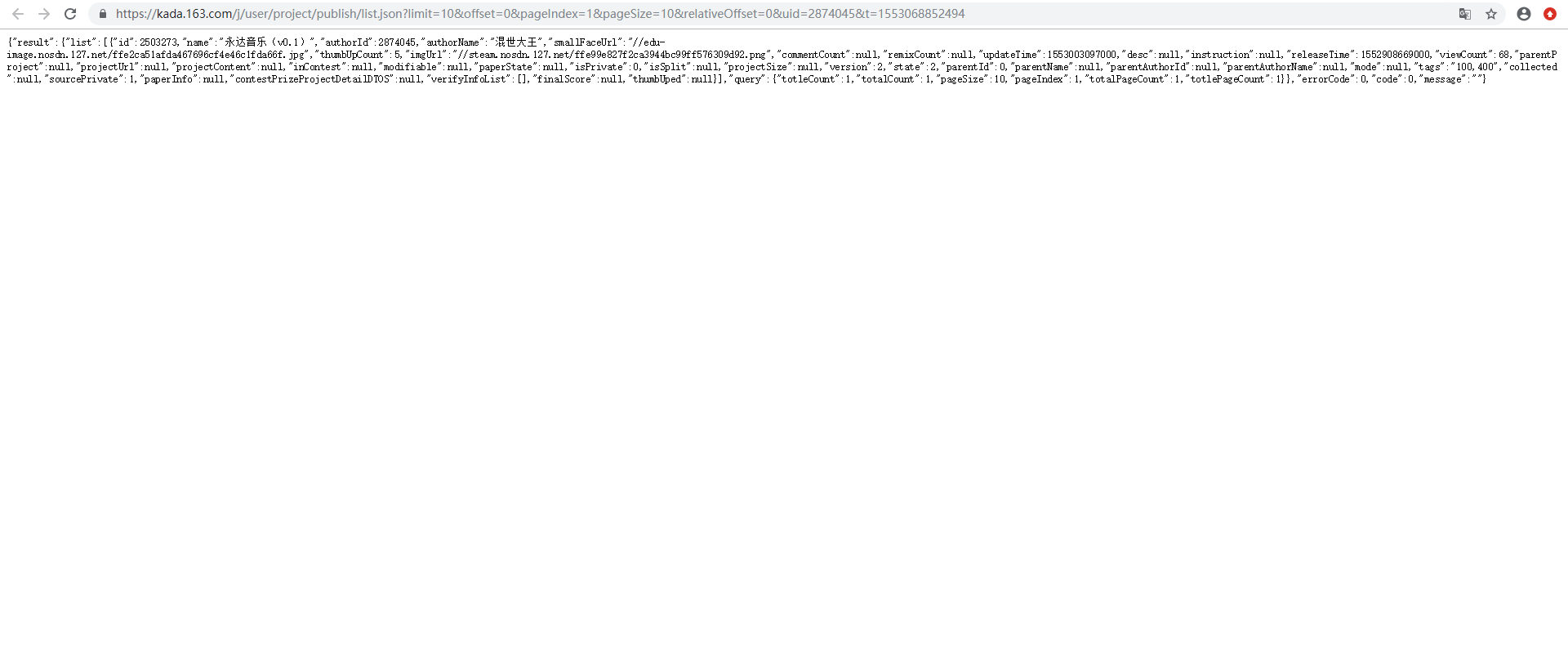
api返回的数据分为很多层,我们要找的就是"totalCount",作品总数。这项数据外面有两层:'result' 'query‘。
api找好了,把地址栏的地址复制下来,根据找到的api写代码吧!
import requests #笨猫出品,必属精品
def get_api():
# 请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Host": "kada.163.com",
"Referer": "https://kada.163.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
}
id = input("请输入id:"); # 输入id
api_url = "https://kada.163.com/j/user/project/publish/list.json?limit=10&offset=0&pageIndex=1&pageSize=10&relativeOffset=0&uid=" + id
# 开始请求
res = requests.get(api_url, headers=headers)
online_dic = res.json()
print(online_dic)
print("作品数:%d" % online_dic['result']['query']['totalCount']) #输出
if __name__ == '__main__':
get_api()
运行效果:输入uid,输出他的作品数量

python爬取+使用网易卡搭作品数量api的更多相关文章
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
随机推荐
- Table行合并操作
此方法不可取,但几天心血 保留,已有新想法,稍后会出一个完善的Table行列合并方法 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Tran ...
- plsql过期注册
Product Code:4t46t6vydkvsxekkvf3fjnpzy5wbuhphqzserial Number:601769password:xs374ca 打开plsql工具 点击注册即可
- c# 字符串的首字母大写转换 方法
方法1: s.Substring(0,1).ToUpper()+s.Substring(1); 方法2: s = System.Threading.Thread.CurrentThread.Curr ...
- webpack相关插件
webpack-merge:开发环境和生产环节的webpaak配置文件的配置合并 file-loader:编译写入文件,默认情况下生成文件的文件名是文件名与MD5哈希值的组合 vue-laoder:编 ...
- 环境变量—《linux命令行与shell脚本编程大全》
环境变量部分: 1.查看全局变量:printenv/env 2.显示单个环境变量的值:echo 如echo $HOME 3.显示为某个特定进程设置的所有环境变量:set 4.设置全局变量:创建局部环境 ...
- Delphi7使用二维码
参考:http://jingyan.baidu.com/article/e75057f2ad6481ebc81a897b.html 首先下载对应的 dll (已经上传到博客园文件) 然后就是Delph ...
- UVA11090 Going in Cycle (二分+判负环)
二分法+spfa判负环.如果存在一个环sum(wi)<k*x,i=0,1,2...,k,那么每条边减去x以后会形成负环.因此可用spfa来判负环. 一般spfa判负环dfs最快,用stack次之 ...
- java sql database相关收集
1 java prepareStatement http://www.importnew.com/5006.html 2 java ENGINE=InnoDB的使用 http://www.cnblog ...
- 01_12_Struts2_访问Web元素
01_12_Struts2_访问Web元素 1. 配置struts.xml文件 <package name="login" namespace="/login&qu ...
- cocos2dx 单张图片加密
cocos2dx 已经封装好读取加密的prv文件的方法,打开texturepacker,导入一张图片,在content protection中写入密钥,在texture format中选择prv格式 ...