大数据学习——sparkSql
官网http://spark.apache.org/docs/1.6.2/sql-programming-guide.html
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("hdfs://mini1:9000/person.json")
1.在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.json / 2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://mini1:9000/person.json").map(_.split(" ")) 3.定义case class(相当于表的schema) case class Person(id:Int, name:String, age:Int) 4.将RDD和case class关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) 5.将RDD转换成DataFrame val personDF = personRDD.toDF 6.对DataFrame进行处理 personDF.show
DSL风格语法



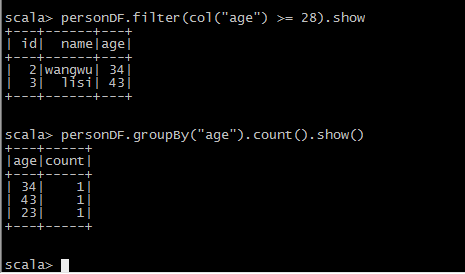
SQL风格语法
scala> val dataRDD=sc.textFile("hdfs://mini1:9000/person.json")
dataRDD: org.apache.spark.rdd.RDD[String] = hdfs://mini1:9000/person.json MapPartitionsRDD[] at textFile at <console>:27
scala> case class Person(id:Int ,name: String, age: Int)
defined class Person
scala> val personDF=dataRDD.map(_.split(" ")).map(x=> Person(x(0).toInt,x(1),x(2).toInt)).toDF()
scala> personDF.registerTempTable("t_person")

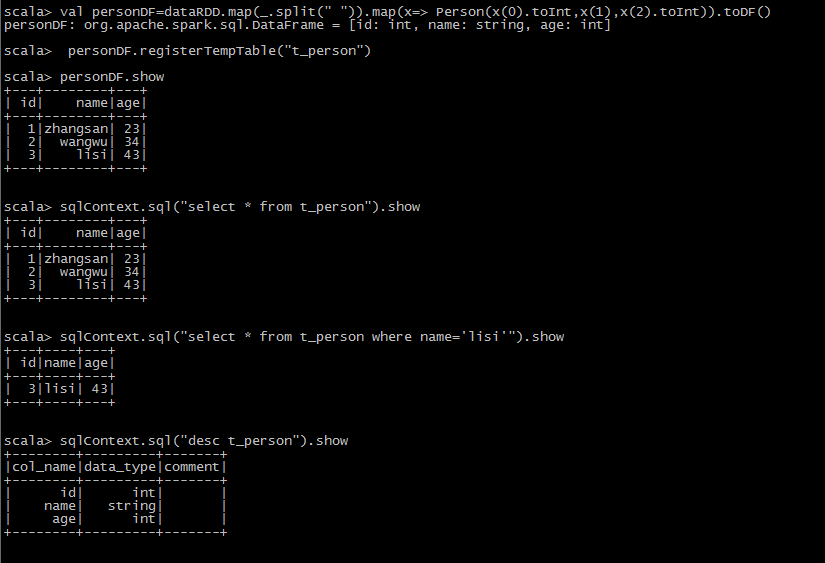
SparkSqlTest
package org.apache.spark import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext} /**
* Created by Administrator on 2019/6/12.
*/
object SparkSqlTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("sparksql").setMaster("local[1]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val file: RDD[String] = sc.textFile("hdfs://mini1:9000/person.json")
val personRDD = file.map(_.split(" ")).map(x => Person(x(0).toInt, x(1), x(2).toInt))
import sqlContext.implicits._
val personDF: DataFrame = personRDD.toDF()
personDF.registerTempTable("t_person")
sqlContext.sql("select * from t_person").show }
} case class Person(id: Int, name: String, age: Int)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| wangwu| 34|
| 3| lisi| 43|
+---+--------+---+
大数据学习——sparkSql的更多相关文章
- 大数据学习——sparkSql对接mysql
1上传jar 2 加载驱动包 [root@mini1 bin]# ./spark-shell --master spark://mini1:7077 --jars mysql-connector-j ...
- 大数据学习——sparkSql对接hive
1. 安装mysql 2. 上传.解压.重命名 2.1. 上传 在随便一台有hadoop环境的机器上上传安装文件 su - hadoop rz –y 2.2. 解压 解压缩:apache- ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
随机推荐
- 公司项目git开发流程规范
手动修改冲突之后,git add . git commit ,git push
- Json字符串与js数组互相转换
1.Json数据格式的字符串转换成js数组: JSON.parse(str); // str 字符串格式 2.js数组转换成Json数据格式字符串: var myJSONText = JSON.s ...
- unity热更新方案对比
Unity应用的iOS热更新 • 什么是热更新 • 为何要热更新 • 怎样在iOS 上对Unity 应用进行热更新 • 支持Unity iOS 热更新的各种Lua 插件的对照 什么是热更新 • ...
- Oracle 11g 新特性 – HM(Hang Manager)简介
在这篇文章中我们会对oracle 11g 新特性—hang 管理器(Hang Manager) 进行介绍.我们需要说明,HM 只在RAC 数据库中存在. 在我们诊断数据库问题的时候,经常会遇到一些数据 ...
- [学习笔记] C++ 历年试题解析(三)--小补充
小小的补充一下吧,因为李老师又把直招的卷子发出来了.. 题目 1.有指针变量定义及初始化int *p=new int[10];执行delete [] p;操作将结束指针变量p的生命期.(×) 解释:试 ...
- guruguru
6576: guruguru 时间限制: 1 Sec 内存限制: 128 MB提交: 28 解决: 12[提交] [状态] [讨论版] [命题人:admin] 题目描述 Snuke is buyi ...
- xshell5 上传下载命令
借助XShell,使用linux命令sz可以很方便的将服务器上的文件下载到本地,使用rz命令则是把本地文件上传到服务器. yum -y install lrzsz 其中,对于sz和rz的理解与记忆我用 ...
- PSNR
PSNR,峰值信噪比,通常用来评价一幅图像压缩后和原图像相比质量的好坏,当然,压缩后图像一定会比原图像质量差的,所以就用这样一个评价指标来规定标准了.PSNR越高,压缩后失真越小.这里主要定义了两个值 ...
- OC和C++的混用2
苹果的Objective-C编译器允许用户在同一个源文件里自由地混合使用C++和Objective-C,混编后的语言叫Objective-C++.有了它,你就可以在Objective-C应用程序中使用 ...
- HTTP无状态协议和session原理(access_token原理)
无状态协议是指协议对务处理没有记忆能力.缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大.另一方面,在服务器不需要先前信息时它的应答就较快. Http协议不 ...