Deep Upsupervised Cardinality Estimation 解读(2019 VLDB)
Deep Upsupervised Cardinality Estimation
- 本篇博客是对Deep Upsupervised Cardinality Estimation的解读,原文连接为:https://dl.acm.org/doi/pdf/10.14778/3368289.3368294
- 本文介绍了如何使用深度自回归模型(如:MADE、transformer)来进行基数估计的任务(利用模型训练拟合数据分布)
- 特点:
- 使用autoregressive model,无监督学习
- 没有做任何独立性假设
- 支持范围查询
选择度(基数)估计问题定义
- selectivity——选择度。本文针对的是给定谓词,估计其可以估计数据表中满足该谓词的元组的比例,有如下定义:$$sel(\theta):=|{\ x \in T :\theta (x)=1}|/|T|$$
其中分母T就是表的总行数,分子是满足选择谓词的行数。
选择度和数据联合分布的关系
- 文中给出联合分布(joint distribution)的定义:
\]
其中分母T仍表示表行数,f为满足a1,a2...an条件的行数。因此实际上联合分布和选择度有着十分紧密的联系(基本一致)。同时联合分布还可以通过因式分解(factorization)写成:
\]
该式没有进行任何独立性假设,而且保留了属性之间的相互联系,因此想获得相对准确的选择度,实际上就是要构建能计算上式的模型。
深度自回归模型如何计算joint distribution
- 作者选用Autoregressive Model进行对数据联合分布的拟合。以某一列为例。对于一列数据的分布,模型的input为前几列值的组合(因为是条件概率),输出的是在前几列的条件下,改列的分布概率。例如一张表travel_checkins含有三个属性:city、year、stars。给定一行作为输入:<Portland;2017;10>:
- \[0\rightarrow M(city)
\]\[E_{city}(Portland)\rightarrow M(year)
\]\[(E_{city}(Portland)\oplus E_{year}(2017)) \rightarrow M_{star}
\]
上式三个输出依次是条件概率:$$\hat{P}(city),\hat{P}(year|city),\hat{P}(star|city,year)$$
- 下图简略展示了模型的工作流
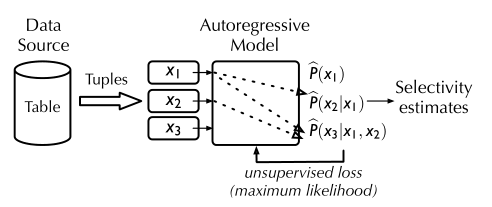
编码解码策略
在训练模型时,我们必须将数据表中的各个元素编码成机器能够看懂的语言,模型输出时我们要将编码进行解码得到各种概率,下面介绍作者提出的编码解码策略。
small-domain:
- encodding:one-hot
- decoding:一个全连接层FC(F,|Ai|),其中F为隐藏层大小,|Ai|第i列的值域大小。输出一个长度|Ai|的向量,每个元素表示位于该值的概率。
large-domain:
- encodding:Embedding,通过词嵌入将各值映射为一个固定长度h的向量
- decoding:Embedding reuse。当属性值域太大时,向上面一样使用一个全连接层产生一个非常长的向量,这在空间上和计算复杂度上都十分低效。在这里作者提出Embedding reuse,同样使用一个全连接层FC(F,h),其中F还是隐藏层的大小,h为Embedding规定的向量长度,这样神经网络就会生成一个长度为h的向量H,接着通过计算\(HE_i^T\)并对其进行标准化处理,我们就能得到一个代表选择度的度量值。
具体执行
本文提供的方法支持点查询和范围查询,一般来说\(sel=P(X_1\in R_1,X_2\in R_2,...X_n\in R_3)\)
- 点查询,即等值查询,将上式转换为:\(sel=P(X_1=x_1,X_2=x_2,...X_n=x_3)\)
- 范围查询:对于范围查询,本文采用渐进采样的方法对数据表进行采样进行概率的估计
- wildcard-skipping:这里提到的通配符不是指like查询,而是指age = any,也就是age可以为任何值,即范围查询age = [0, Di]。所以这里提到的通配符是为了满足有些条件没有filter的处理。
为了达到这个目的,作者设计了特殊的token,Xi = MASKi,如age这一列的token为MASK_age。训练的时候,会把每一列用这个token替换掉,进行训练(这样就需要训练n次?n为列的个数,相当于数据被复制了n份,每一份把一列的值替换为token)。
实际操作的时候,会随机sample一个tuple,age对应的值换成MASK_age,表明age取所有值,其他值的条件概率就是当age取所有值的情况下,其条件概率为多少,作为label。至于sample多少条数据,这个要看具体效果了。
另外要根据实际的query确定哪些列需要有这个通配符。再举个具体的例子,一个表有三列a b c,查询为a=1,那么模型训练的时候必须要有b=MASK_b,c=MASK_c,查询的输入为a=1, b=MASK_b,c=MASK_c。再如a<10,一种方法是sampling,还有一种方法是模型训练的时候要有a=MASK_a, 这样查询的时候输入是a=MASK_a, b=MASK_b,c=MASK_c,a的输出会得到所有的值,再把<10对应的值的概率加起来。
所以,这个通配符是非常有用的,因为在真实查询中,不可能保证所有列上都有条件,那么没有条件的列就用通配符替代。当然也可以用sampling的方式,但是通配符的查询效率更高。
属性的顺序
从上面的分析中可以看到每列实际上是有顺序的,比如模型的输入是列a b c,输出是条件概率,既然是条件概率,那么b的概率是给定a得到,c的概率是给定a和b得到。所以这个顺序要提前定好,如果查询是b=1 a=2,需要把顺序调整成a=2 b=1输入到模型。
均匀采样和渐进采样
两种sampling策略是为了解决范围查询的选择度估计问题。
假定一个范围查询域\(R=R_1\times R_2 \times ... \times R_n\),如果用等值的方法处理这种问题,在某种比较坏的情况下,查询域可能会非常大(比如可能为\(|A_1|\times |A_2| ... |A_n|\)),此时非常耗费时间和空间。为了解决这种问题,本文尝试了两种解决方案:
uniformly sampling
- 从R(查询域)中均匀随机抽样出\(x^{(i)}\),接着将该\(x^{(i)}\)输入模型,计算出该样本在数据表中的概率:\(\hat{p_i}=\hat{P}(x^{(i)})\),基于朴素蒙特卡洛,对于S个样本,我们可以将\(\frac{|R|}{S}\sum_{i=1}^{S}\hat{p_i}\)作为期望密度的无偏估计。简单来说,该方案是将点随机扔到目标区域R中,以探测其平均密度。
- 均匀采样的缺点:考虑这样一个情况,数据表T有n个属性列,但每一列的数据都非常倾斜,有99%的数据只集中在前1%的值域中,剩下1%的数据分散到后99%的值域内。在这种情况下,如果我们想进行值域前50%的范围查询。通过随机抽样我们大概率只能抽到1%-50%内的数据,计算出的结果会严重失真。如果要保持准确性,我们必须抽\(1/(0.01/0.5)^n=1/0.02^n\)个样本才能都取到数据高密度区域。真实的数据集中,这样倾斜的数据常有出现,当均匀抽样遇到这样的数据会很快崩溃,产生非常大的误差如下图左,这里我们使用下文提出的渐进采样来决绝该问题。
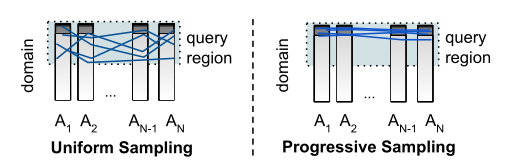
progressive sampling
- 渐进采样。在均匀采样中,我们是随机的在查询域中选择了一组样本。但实际上,我们可以更有选择性的挑选样本。具体来说我们可以利用模型一边生成各个属性的概率分布,一边按照生成的概率分布进行采样,因为是逐步进行采样的所以叫渐进采样。通过渐进采样,我们能很容易的采样到高数据密度的区域,如上图右。步骤如下:
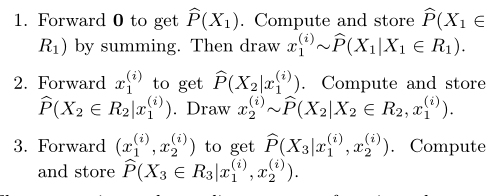
- 渐进采样。在均匀采样中,我们是随机的在查询域中选择了一组样本。但实际上,我们可以更有选择性的挑选样本。具体来说我们可以利用模型一边生成各个属性的概率分布,一边按照生成的概率分布进行采样,因为是逐步进行采样的所以叫渐进采样。通过渐进采样,我们能很容易的采样到高数据密度的区域,如上图右。步骤如下:
(*^▽^*)
(*^▽^*)
(*^▽^*)
(*^▽^*)
(*^▽^*)
笔者解读不易,若是有所帮助,给笔者点个赞吧(*^▽^*)
欢迎来与笔者交流相关问题!
Deep Upsupervised Cardinality Estimation 解读(2019 VLDB)的更多相关文章
- A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2021)
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2 ...
- Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)
Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021) 本 ...
- 解读Cardinality Estimation<基数估计>算法(第一部分:基本概念)
基数计数(cardinality counting)是实际应用中一种常见的计算场景,在数据分析.网络监控及数据库优化等领域都有相关需求.精确的基数计数算法由于种种原因,在面对大数据场景时往往力不从心, ...
- 萌新笔记——Cardinality Estimation算法学习(一)(了解基数计算的基本概念及回顾求字符串中不重复元素的个数的问题)
最近在菜鸟教程上自学redis.看到Redis HyperLogLog的时候,对"基数"以及其它一些没接触过(或者是忘了)的东西产生了好奇. 于是就去搜了"HyperLo ...
- SQL Server 2014里的针对基数估计的新设计(New Design for Cardinality Estimation)
对于SQL Server数据库来说,性能一直是一个绕不开的话题.而当我们去分析和研究性能问题时,执行计划又是一个我们一直关注的重点之一. 我们知道,在进行编译时,SQL Server会根据当前的数据库 ...
- HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm
HyperLogLog参考下面这篇blog, http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-par ...
- Cardinality Estimation算法学习(一)(了解基数计算的基本概念及回顾求字符串中不重复元素的个数的问题)
最近在菜鸟教程上自学redis.看到Redis HyperLogLog的时候,对“基数”以及其它一些没接触过(或者是忘了)的东西产生了好奇. 于是就去搜了“HyperLogLog”,从而引出了Card ...
- Are we ready for learned cardinality estimation?
Are we ready for learned Cardinality Estimation 摘要 文章包括三大部分: 对于一个静态的数据库,本文将五种基于学习的基数估计方法与九中传统的基数估计方法 ...
- Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021) ...
随机推荐
- macos下命令行通过ndk编译android下可以执行的ELF程序(并验证opencl的调用)
源码如下,实现把一个JPG保存成灰度图格式的BMP 1 //jpg2bmp.cpp 2 #include <stdio.h> 3 #include <inttypes.h> 4 ...
- Python SQL execute加参数的原理
在Python中,当用pymysql库,或者MySQLdb库进行数据库查询时,为了防止sql注入,可以在execute的时候,把参数单独带进去,例如: def execute_v1(): config ...
- (转引)数据库索引(MySQL)
数据结构和算法基础 索引的本质:数据结构,帮助高效获取数据 数据库的查询:最基本的查询算法当然是顺序查找(linear search).二分查找(binary search).二叉树查找(binary ...
- Simulink S-Function的使用(以串口接收MPU6050六轴陀螺仪参数为实例)
S-Function 允许使用自定义C/C++函数作为传递函数,具有可移植性.也可以同样利用MATLAB函数进行相同的运算,看开发者熟悉程度而定. 项目流程 由系统串口接收数据包. 通过S-Funct ...
- 这个命令行HTTP客户端工具真不错
程序员专属微信红包封面1000个,兑换码:dWK7fUs2WQG cURL相信很多做开发的.运维的都不陌生,是非常有用的一个终端请求工具,借助于它可以在命令行中进行HTTP.FTP等请求,在Linux ...
- django 验证和授权
User模型 一. User模型简介 1. 是验证和授权框架的核心模型,完整路径为:django.contrib.auth.models.User 2. 模型中拥有的字段: 1. username:用 ...
- java中的泛型,简单介绍。 修饰方法的用法
一.<R> ( R r ) 默认object 可以存所有类型. R 这个是随便定义的大写字母,前后要保持一致性! package com.aaa.test; /* * 演示 泛型 ...
- 业务4P分析实践
原创不易,求分享.求一键三连 前言 假期继续思考BI未来的方向,其实常规的BI规划也不是不能出,比如公司BI看板建设.数据指标体系建设.业务线UE模型数据监控等,但这种不会超出预期的东西自然也能算技术 ...
- 使用 Frp 和 Docker 通过远程桌面和 SSH 来远程控制 Windows(反向代理)
最新博客文章链接 大体思路 使用 Docker 容器,在云服务器上部署 Frps 容器来中转流量,在被控制的 Windows 上部署 Frpc 容器来暴露内网的服务,在主控制端的 Windows 上直 ...
- golang 获取当月最后一天日期
now := time.Now() year, month, day := now.Date() //fmt.Println(year, month, day) //2021 September 1 ...