C++继承体系中的内存对齐
本篇随笔讨论一个比较冷门的知识,继承结构中内存对齐的问题,如今内存越来越大也越来越便宜,大部分人都已经不再关注内存对齐的问题了。但是作为一个有追求的技术人员,实现功能永远都是最基本的要求,把代码优化到自己想要的样子才能从中找到真正的愉悦感。这便是我们追求细节的意义。
声明:以下例子,以x86_64 64bit编译器编译的结果作为参考,32位编译器会有不同结果,这里不讨论。
| 目录 |
| 引子-内存对齐示例与规则 |
| 进阶-继承体系中的内存对齐 |
引子-内存对齐示例与规则:
讨论内存对齐,就要牵涉到#pragma pack(n)中定义n的大小。C语言中针对结构体提出了内存对齐的概念。下面请看代码:
#include <iostream>
using namespace std;
#pragma pack(8)
struct Ethanol{
char ch;
short sh;
int it;
};
struct Ether{
char ch;
int it;
short sh;
};
int main()
{
cout<<"Ethanol:"<<sizeof(Ethanol)<<endl;
cout<<"Ether :"<<sizeof(Ether)<<endl;
return 0;
}
运行结果:

如果不清楚上面的数据如何产生,请对照下面内村对齐的规则:
x86(linux 默认#pragma pack(4), window 默认#pragma pack(8))。linux 最大支持 4 字节对齐。
1 )取 pack(n)的值(n= 1 2 4 8--),取结构体中类型最大值 m。两者取小即为外对齐大小 Y= (m<n?m:n)。
2 )将每一个结构体的成员大小与 Y 比较取小者为 X,作为内对齐大小.
3 )所谓按 X 对齐,即为地址(设起始地址为 0)能被 x 整除的地方开始存放数据。
4 )外部对齐原则是依据 Y 的值(Y 的最小整数倍),进行补空操作。
原则:先内后外。
结构体内元素不同的排列组合方式大概可以用化学中的同分异构体来比喻,比如乙醇和甲醚,他们有着完全相同的成分,但是化学性质却不同。所以上面我用了Ethanol和Ether两个名字来命名结构体。
过渡到C++中,类与结构提不仅可以通过组合的方式构成新类型,还可以通过继承的方式来实现代码的重用
由结构体延伸到类看看包含关系中的类大小:
#include <iostream> using namespace std; #pragma pack(8) class P1
{
public:
P1(){}
virtual void printP1(){ }
protected:
int p1;
};class Son
{
public:
Son(){}
private:
int son;
P1 P1;
};
int main()
{
cout<<"P1_Size :"<<sizeof(P1)<<endl;
cout<<"Son_Size:"<<sizeof(Son)<<endl;
}
运行结果:
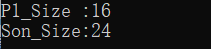
以上运行结果,如果对C++了解,那么应该知道含有虚函数的类,除了成员变量大小外,虚函数表指针排在最前面。所以虚函数表指针的大小也要算进去。对照上面的内存对齐规则,我们计算一下上面的结果是怎么来的:
#pragma pack(n) ,n = 8。系统和编译器均为为64位,所以指针的大小是8Byte。
1)取P1中的最大类型大小m(虚函数表指针大小)与n作比较,m==n,所以外对齐Y==8。
2)结构体内每一个元素与Y做比较,取小者做内对其。所以,排列为下图:
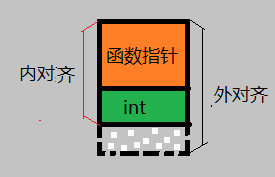
所谓对齐,就是以0为起始地址,对元素进行排列,使用一个来能够整除内对齐的地址来安放后一个数据元素。
内对齐8+4=12
3)但是12不是外对齐的倍数,要用外对齐的最小整数倍来补齐8X2=16正好是这个类的大小。
进阶-继承体系中的内存对齐
继承现象:
上面用足组合的关系来计算一个类的大小是符合内存对齐规则的,这种包含关系与内存结构体中的对齐没有任何区别,那如果改为继承关系呢?
#include <iostream> using namespace std; #pragma pack(8) class P1
{
public:
P1(){
cout<<"P1() :"<<(long long)this<<endl;
}
virtual void printP1(){ }
protected:
int p1;
}; class Son:public P1
{
public:
Son()
{
} private: int son;
// P1 P1;
};
int main()
{
cout<<"P1_Size :"<<sizeof(P1)<<endl;
cout<<"Son_Size:"<<sizeof(Son)<<endl;
}
运行结果:
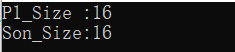
仿佛有4个字节丢失了。。。。。。
查看内存排列:
我们在派生类的构造函数看一下son元素的地址,此地址即使son类型的起始地址,也是基类类型P1的结束地址:
#include <iostream> using namespace std; #pragma pack(8) class P1
{
public:
P1()
{
cout<<"Base_addr:"<<(long long)this<<endl;
}
virtual void printP1(){ }
protected:
int p1;
}; class Son:public P1
{
public:
Son()
{
cout<<"son_addr:"<<(long long)&son<<endl;
cout<<"Base_inherit_size:"<<(long long)&son - (long long)this<<endl;
}
private: int son; // P1 P1;
};
int main()
{
cout<<"P1_Size :"<<sizeof(P1)<<endl;
cout<<"Son_Size:"<<sizeof(Son)<<endl;
Son son;
}
运行结果:

由此结果我们得到的结论是派生类继承并非完全继承了基类的大小,却继承了基类未作外对齐的大小,由此运行结果我们可以看出派生类(Son)类只继承了基类(P1)12个字节。对此感到疑惑的朋友可以继续使用其它示例来检验这个结果。
由此我们给出以下总结
继承体系中内存对齐的实质:
所谓继承关系实质上是派生类继承了基类中的元素(虚函数表和成员变量),而非继承已经内存对齐固化的基类结构,基类中的元素被继承到派生类中与派生类中新添加的元素需要重新按着元素的排列组合内存对齐。所以就有了上面包含关系与继承关系完全不一样的大小的现象。
C++继承体系中的内存对齐的更多相关文章
- C++继承体系中的内存分段
---------------综述与目录-------------- 讨论这个问题之前我们先明确类的结构,一个类的大概组成,下面的很多分类名词都是我个人杜撰,为的就是让读者看懂能够区分,下面分别分类: ...
- C语言中的内存对齐
最近看了好多,也编了好多C语言的浩强哥书后的题,总觉的很不爽,真的真的好怀念linux驱动的代码,好怀念那下划线,那结构体,虽然自己还很菜. 同时看了一遍陈正冲老师的C语言深度剖析,收益很多,又把唐老 ...
- C++ 继承体系中的名称覆盖
首先一个简单的样例: int x; int f() { double x; cin >> x; return x; } 在上述代码中.函数f的局部变量x掩盖了全局变量x.这得从 " ...
- 关于Java继承体系中this的表示关系
Java的继承体系中,因为有重写的概念,所以说this在子父类之间的调用到底是谁的方法,或者成员属性,的问题是一个值得思考的问题; 先说结论:如果在测试类中调用的是子父类同名的成员属性,这个this. ...
- C/C++中的内存对齐 C/C++中的内存对齐
一.什么是内存对齐.为什么需要内存对齐? 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址 ...
- C++中的内存对齐
在我们的程序中,数据结构还有变量等等都需要占有内存,在很多系统中,它都要求内存分配的时候要对齐,这样做的好处就是可以提高访问内存的速度. 我们还是先来看一段简单的程序: 程序一 1 #include ...
- Delphi中的内存对齐 与 Packed关键字
以delphi为例:TTest = recordc1: char;i1: Integer;c2: char;c3: Char;end;这个结构如果用sizeof取其占用的内存大小,是多少呢,是1+4+ ...
- C/C++中的内存对齐问题和pragma pack命令详解
这个内存对齐问题,居然影响到了sizeof(struct)的结果值.突然想到了之前写的一个API库里,有个API是向后台服务程序发送socket请求.其中的socket数据包是一个结构体.在发送soc ...
- C语言中的内存对齐问题
问题 突然收到了一个问题: #include<stdio.h> #include <math.h> struct icd { int a; //4 char b; //1 do ...
随机推荐
- C语言:预处理 自定义头文件
DEV-C++包含文件搜索路径C:\Program Files\Dev-Cpp\MinGW64\x86_64-w64-mingw32\includeC:\Program Files\Dev-Cpp\M ...
- 初探SpringRetry机制
重试是在网络通讯中非常重要的概念,尤其是在微服务体系内重试显得格外重要.常见的场景是当遇到网络抖动造成的请求失败时,可以按照业务的补偿需求来制定重试策略.Spring框架提供了SpringRetry能 ...
- python -- 面向对象编程(属性、方法)
一.属性 对象的属性(attribute)也叫做数据成员(data member). 如果想指向某个对象的属性,可以使用格式: object.attribute 属性又分为:私有属性和公有属性. 私有 ...
- Requests方法 --- json模块
1.Json 简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式,常用于 http 请求中 2.可以用 help(json),查看对应的源码注释内容 ...
- uni-app&H5&Android混合开发三 || uni-app调用Android原生方法的三种方式
前言: 关于H5的调用Android原生方法的方式有很多,在该片文章中我主要简单介绍三种与Android原生方法交互的方式. 一.H5+方法调用android原生方法 H5+ Android开发规范官 ...
- 配置软ISCSI存储
说明:这里是Linux服务综合搭建文章的一部分,本文可以作为单独使用RedHat Enterprise Linux 7搭建软ISCSI的参考. 注意:这里所有的标题都是根据主要的文章(Linux基础服 ...
- [HNOI]2011卡农
这是一道很好的组合数学题. 对于和我一样五音里面有六音不全的人来说,我们就应该转换一下题目的意思: 一句话题意: 题目的意思就是说要从一个有 n 个元素的集合当中选出一个长度为m的集合,然后满足: 1 ...
- 一台电脑安装两个不同版本的MySQL
背景: 本人电脑上已有mysql-8.0.12-winx64,并且可以使用.但由于工作需要,得使用mysql-5.5.59-winx64,已有mysql-5.5.59-winx64的解压好的安装包 参 ...
- pip批量安装库
将需要安装的库名和版本号都写在一个txt文档中,每个库名占一行,例如requests==2.24.0. 然后在用pip install -r命令去找到这个txt文档批量安装里面填写的库,如果嫌速度太慢 ...
- element UI table 状态显示:禁用-启用 上架-下架
vue2.0+elementUI 解决表单上架下架状态的切换 https://blog.csdn.net/weixin_42507803/article/details/81910297 <el ...