【MRR】转-MySQL 的 MRR 优化
MRR,全称「Multi-Range Read Optimization」。
简单说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
至于:
为什么要把随机读转化为顺序读?
怎么转化的?
为什么顺序读就能提升读取性能?
咱们开始吧。
磁盘:苦逼的底层劳动人民
执行一个范围查询:
mysql > explain select * from stu where age between 10 and 20;
+----+-------------+-------+-------+------+---------+------+------+-----------------------+
| id | select_type | table | type | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+------+------+-----------------------+
| 1 | SIMPLE | stu | range | age | 5 | NULL | 960 | Using index condition |
+----+-------------+-------+-------+----------------+------+------+-----------------------+
当这个 sql 被执行时,MySQL 会按照下图的方式,去磁盘读取数据(假设数据不在数据缓冲池里):
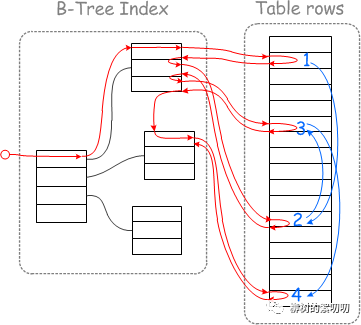
图中红色线就是整个的查询过程,蓝色线则是磁盘的运动路线。
这张图是按照 Myisam 的索引结构画的,不过对于 Innodb 也同样适用。
对于 Myisam,左边就是字段 age 的二级索引,右边是存储完整行数据的地方。
先到左边的二级索引找,找到第一条符合条件的记录(实际上每个节点是一个页,一个页可以有很多条记录,这里我们假设每个页只有一条),接着到右边去读取这条数据的完整记录。
读取完后,回到左边,继续找下一条符合条件的记录,找到后,再到右边读取,这时发现这条数据跟上一条数据,在物理存储位置上,离的贼远!
咋办,没办法,只能让磁盘和磁头一起做机械运动,去给你读取这条数据。
第三条、第四条,都是一样,每次读取数据,磁盘和磁头都得跑好远一段路。
磁盘的简化结构可以看成这样:

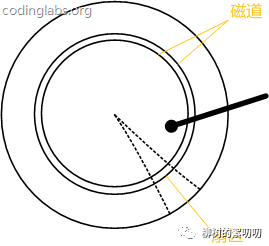
可以想象一下,为了执行你这条 sql 语句,磁盘要不停的旋转,磁头要不停的移动,这些机械运动,都是很费时的。
10,000 RPM(Revolutions Per Minute,即转每分) 的机械硬盘,每秒大概可以执行 167 次磁盘读取,所以在极端情况下,MySQL 每秒只能给你返回 167 条数据,这还不算上 CPU 排队时间。
对于 Innodb,也是一样的。 Innodb 是聚簇索引(cluster index),所以只需要把右边也换成一颗叶子节点带有完整数据的 B+ tree 就可以了。
顺序读:一场狂风暴雨般的革命
到这里你知道了磁盘随机访问是多么奢侈的事了,所以,很明显,要把随机访问转化成顺序访问:
mysql > set optimizer_switch='mrr=on';
Query OK, 0 rows affected (0.06 sec) mysql > explain select * from stu where age between 10 and 20;
+----+-------------+-------+-------+------+---------+------+------+----------------+
| id | select_type | table | type | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+------+---------+------+------+----------------+
| 1 | SIMPLE | tbl | range | age | 5 | NULL | 960 | ...; Using MRR |
+----+-------------+-------+-------+------+---------+------+------+----------------+
我们开启了 MRR,重新执行 sql 语句,发现 Extra 里多了一个「Using MRR」。
这下 MySQL 的查询过程会变成这样:
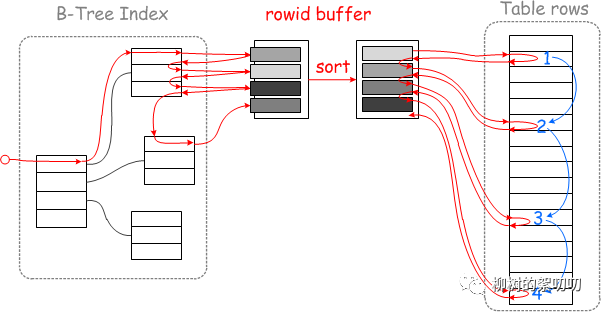
对于 Myisam,在去磁盘获取完整数据之前,会先按照 rowid 排好序,再去顺序的读取磁盘。
对于 Innodb,则会按照聚簇索引键值排好序,再顺序的读取聚簇索引。
顺序读带来了几个好处:
1、磁盘和磁头不再需要来回做机械运动;
2、可以充分利用磁盘预读
比如在客户端请求一页的数据时,可以把后面几页的数据也一起返回,放到数据缓冲池中,这样如果下次刚好需要下一页的数据,就不再需要到磁盘读取。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
3、在一次查询中,每一页的数据只会从磁盘读取一次
MySQL 从磁盘读取页的数据后,会把数据放到数据缓冲池,下次如果还用到这个页,就不需要去磁盘读取,直接从内存读。
但是如果不排序,可能你在读取了第 1 页的数据后,会去读取第2、3、4页数据,接着你又要去读取第 1 页的数据,这时你发现第 1 页的数据,已经从缓存中被剔除了,于是又得再去磁盘读取第 1 页的数据。
而转化为顺序读后,你会连续的使用第 1 页的数据,这时候按照 MySQL 的缓存剔除机制,这一页的缓存是不会失效的,直到你利用完这一页的数据,由于是顺序读,在这次查询的余下过程中,你确信不会再用到这一页的数据,可以和这一页数据说告辞了。
顺序读就是通过这三个方面,最大的优化了索引的读取。
别忘了,索引本身就是为了减少磁盘 IO,加快查询,而 MRR,则是把索引减少磁盘 IO 的作用,进一步放大。
一些关于这场革命的配置
和 MRR 相关的配置有两个:
mrr: on/off
mrr_cost_based: on/off
第一个就是上面演示时用到的,用来打开 MRR 的开关:
mysql > set optimizer_switch='mrr=on';
如果你不打开,是一定不会用到 MRR 的。
另一个,则是用来告诉优化器,要不要基于使用 MRR 的成本,考虑使用 MRR 是否值得(cost-based choice),来决定具体的 sql 语句里要不要使用 MRR。
很明显,对于只返回一行数据的查询,是没有必要 MRR 的,而如果你把 mrr_cost_based 设为 off,那优化器就会通通使用 MRR,这在有些情况下是很 stupid 的,所以建议这个配置还是设为 on,毕竟优化器在绝大多数情况下都是正确的。
另外还有一个配置 read_rnd_buffer_size ,是用来设置用于给 rowid 排序的内存的大小。
显然,MRR 在本质上是一种用空间换时间的算法。MySQL 不可能给你无限的内存来进行排序,如果 read_rnd_buffer 满了,就会先把满了的 rowid 排好序去磁盘读取,接着清空,然后再往里面继续放 rowid,直到 read_rnd_buffer 又达到 read_rnd_buffe 配置的上限,如此循环。
尾声
你也看出来了,MRR 跟索引有很大的关系。
索引是 MySQL 对查询做的一个优化,把原本杂乱无章的数据,用有序的结构组织起来,让全表扫描变成有章可循的查询。
而我们讲的 MRR,则是 MySQL 对基于索引的查询做的一个的优化,可以说是对优化的优化了。
要优化 MySQL 的查询,就得先知道 MySQL 的查询过程;而要优化索引的查询,则要知道 MySQL 索引的原理。
就像之前在「如何学习 MySQL」里说的,要优化一项技术、学会调优,首先得先弄懂它的原理,这两者是不同的 Level。
转自-https://mp.weixin.qq.com/s/1duffrGhNq_DzMSYrbCdhw
【MRR】转-MySQL 的 MRR 优化的更多相关文章
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- MYSQL数据库的优化
我们究竟应该如何对MySQL数据库进行优化?下面我就从MySQL对硬件的选择.MySQL的安装.my.cnf的优化.MySQL如何进行架构设计及数据切分等方面来说明这个问题. 服务器物理硬件的优化 在 ...
- 1229【MySQL】性能优化之 Index Condition Pushdown
转自http://blog.itpub.net/22664653/viewspace-1210844/ [MySQL]性能优化之 Index Condition Pushdown2014-07-06 ...
- mysql中的优化, 简单的说了一下垂直分表, 水平分表(有几种模运算),读写分离.
一.mysql中的优化 where语句的优化 1.尽量避免在 where 子句中对字段进行表达式操作select id from uinfo_jifen where jifen/60 > 100 ...
- MySQL 调优/优化的 100 个建议
MySQL 调优/优化的 100 个建议 MySQL是一个强大的开源数据库.随着MySQL上的应用越来越多,MySQL逐渐遇到了瓶颈.这里提供 101 条优化 MySQL 的建议.有些技巧适合特定 ...
- 理解MySQL——索引与优化
转自:理解MySQL——索引与优化 写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存 ...
- MySQL数据库的优化(下)MySQL数据库的高可用架构方案
MySQL数据库的优化(下)MySQL数据库的高可用架构方案 2011-03-09 08:53 抚琴煮酒 51CTO 字号:T | T 在上一篇MySQL数据库的优化中,我们跟随笔者学习了单机MySQ ...
- MySQL数据库的优化(上)单机MySQL数据库的优化
MySQL数据库的优化(上)单机MySQL数据库的优化 2011-03-08 08:49 抚琴煮酒 51CTO 字号:T | T 公司网站访问量越来越大,导致MySQL的压力越来越大,让我们自然想到的 ...
随机推荐
- HDOJ-3065(AC自动机+每个模板串的出现次数)
病毒侵袭持续中 HDOJ-3065 第一个需要注意的是树节点的个数也就是tree的第一维需要的空间是多少:模板串的个数*最长模板串的长度 一开始我的答案总时WA,原因是我的方法一开始不是这样做的,我是 ...
- FreeBSD 12.2 发布
FreeBSD 团队宣布 FreeBSD 12.2 正式发布,这是 FreeBSD 12 的第三个稳定版本. 本次更新的一些亮点: 引入了对无线网络堆栈的更新和各种驱动程序,以提供更好的 802.11 ...
- BZOJ_2115 [Wc2011] Xor 【图上线性基】
一.题目 [Wc2011] Xor 二.分析 比较有意思的一题,这里也学到一个结论:$1$到$N$的任意一条路径异或和,可以是一个任意一条$1$到$N$的异或和与图中一些环的异或和组合得到.因为一个数 ...
- KMP字符串匹配学习笔记
部分内容引自皎月半洒花的博客 模式串匹配问题模型给定一个需要处理的文本串和一个需要在文本串中搜索的模式串,查询在该文本串中,给出的模式串的出现有无.次数.位置等.算法思想每次失配之后不会从头开始枚举, ...
- [SIGIR2020] Sequential Recommendation with Self-Attentive Multi-Adversarial Network
这篇论文主要提出了一个网络,成为Multi-Factor Generative Adversarial Network,直接翻译过来的话就是多因子生成对抗网络.主要是期望能够探究影响推荐的其他因子(因 ...
- 深入Spring Security魔幻山谷-获取认证机制核心原理讲解(新版)
文/朱季谦 本文基于Springboot+Vue+Spring Security框架而写的原创学习笔记,demo代码参考<Spring Boot+Spring Cloud+Vue+Element ...
- Go语言操作数据库及其常规操作
Go操作MySQL 安装: go get -u github.com/go-sql-driver/mysql GO语言的操作数据库的驱动原生支持连接池, 并且是并发安全的 标准库没有具体的实现 只是列 ...
- 2.EL表达式&JSTL标签库常用方法
1.EL表达式 Expression Language表达式语言,主要是代替jsp页面中的表达式脚本在jsp页面中进行数据的输出. 格式为${表达式} EL表达式输出Bean的普通属性.数组属性.Li ...
- @Transactional+@Autowired出现的lateinit property xx has not been initialized错误
1 问题描述 用Kotlin编写Spring Boot,在业务层中使用@Transactional+@Autowired时出现如下错误: lateinit property dao has not b ...
- kubernetes CRD
官方文档:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions ...