Zookeeper 序列化机制
- 一、到底在哪些地方需要使用序列化技术呢?
- 二、Zookeeper(分布式协调服务组件+存储系统)
- Java 序列化机制
- Hadoop序列化机制
- Zookeeper序列化机制
一、到底在哪些地方需要使用序列化技术呢?
1、当在网络中需要进行消息、数据、等的传输,那么这些数据就需要进行序列化和反序列化。
2、当数据需要从内存被持久化到磁盘的时候。
二、Zookeeper(分布式协调服务组件+存储系统)
任何一个分布式系统的底层,都必然会有网络通信,这就必然要提供一个分布式通信框架和序列化机制。
Zookeeper网络通信和序列化。你知道有哪些序列化方式呢?
1、Java提供的序列化机制
2、Hadoop的序列化技术
3、Zookeeper的序列化
4、Spark提供的序列化等等
1、Java序列化机制
- class xxxx implements Serializable
- 序列化过程中:类型信息 + 对象实例的属性值
- 特点就是比较笨重:(除了实例的属性信息以外,还会序列化这个实例的类型信息)
- Spark默认使用的序列化机制就是Java原生序列化机制,也提供其他的序列化方式。
- 使用ObjectInputStream 和 ObjectOutputStream 来进行具体的序列化和反序列化。
2、Hadoop序列化机制
有两种方式:avro(implements Writable) protobuf
Hdfs中使用的序列化就是avro,Yarn使用的是Protobuf
Hadoop的序列化和反序列化中的字段的顺序和多少,一定要严格一样,否则序列化和反序列化就对不上了。
class Student implements Writable{
// 反序列化
void readFields(DataIn input);
// 序列化
void write(DataOut output);
}
3、Zookeeper序列化机制
zk中的序列化和反序列化,没有严格的顺序要求,因为使用tag标记,下面会有简单的demo示例:
class Student implements Record{
// 反序列化
void deserialize(InputArchive archive, String tag) {
archive.readBytes();
archive.readInt();
}
// 序列化
void serialize(OutputArchive archive, String tag)
}
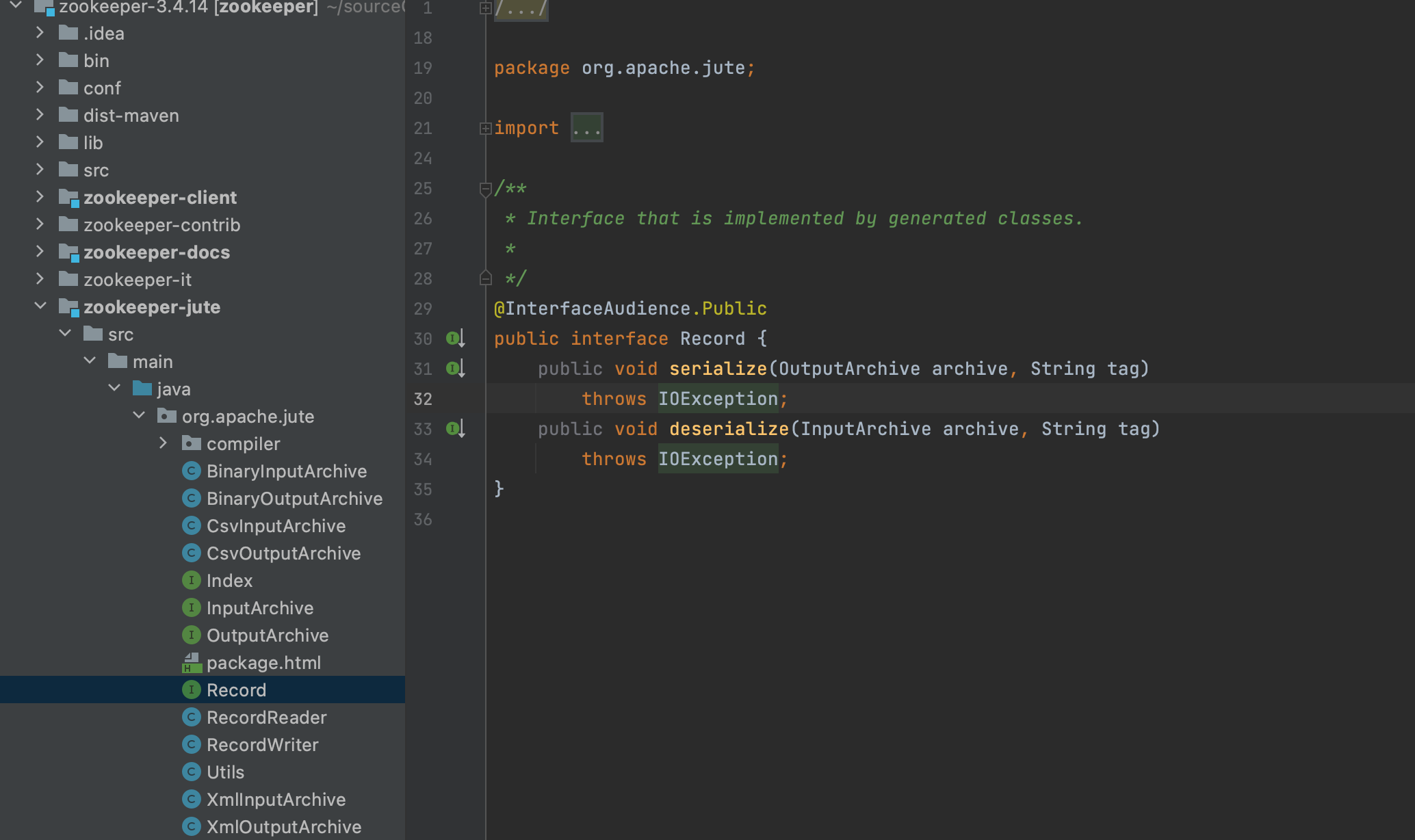
ZK中序列化就是Record,如果在源码中看到了一个类实现了Record接口,那么这个类必然将有数据从磁盘读取到内存和从内存序列化到磁盘的方法。
序列化的API主要在zookeeper-jute子项目中。
重点API:
org.apache.jute.InputArchive:反序列化需要实现的接口,其中各种read开头的方法,都是反序列化方法
实现类:在3.4.x之前有三种实现,见图:
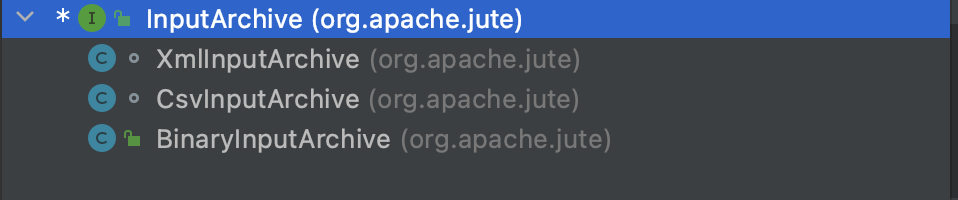
3.5之后的版本 就只有Binary这一种了,主要原因是CSV和XML这两种实现类没有人使用,如果需需呀使用这两种实现,直接从老版本中复制。
org.apache.jute.OutputArchive:所有进行序列化操作的都是实现这个接口,其中各种write开头的方法都是序列化方法。
org.apache.jute.Index:用于迭代数据进行反序列化的迭代器。见图:

org.apache.jute.Record:在Zookeeper要进行网络通信的对象,都需要实现这个接口。里面有序列化和反序列化两个重要的方法。
Zookeeper 序列化机制的更多相关文章
- 【分布式】Zookeeper序列化及通信协议
一.前言 前面介绍了Zookeeper的系统模型,下面进一步学习Zookeeper的底层序列化机制,Zookeeper的客户端与服务端之间会进行一系列的网络通信来实现数据传输,Zookeeper使用J ...
- 深入挖掘.NET序列化机制——实现更易用的序列化方案
.NET框架为程序员提供了“序列化和反序列化”这一有力的工具,使用它,我们能很容易的将内存中的对象图转化为字节流,并在需要的时候再将其恢复.这一技术的典型应用场景包括[1] : 应用程序运行状态的持久 ...
- zookeeper心跳机制流程梳理
zookeeper心跳机制流程梳理 Processor链Chain protected void setupRequestProcessors() { RequestProcessor finalPr ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Java序列化机制
java的序列化机制支持将对象序列化为本地文件或者通过网络传输至别处, 而反序列化则可以读取流中的数据, 并将其转换为java对象. 被序列化的类需要实现Serializable接口, 使用Objec ...
- Thrift 个人实战--Thrift 的序列化机制
前言: Thrift作为Facebook开源的RPC框架, 通过IDL中间语言, 并借助代码生成引擎生成各种主流语言的rpc框架服务端/客户端代码. 不过Thrift的实现, 简单使用离实际生产环境还 ...
- 由浅入深了解Thrift之服务模型和序列化机制
一.Thrift介绍 Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎.其允许你定义一个简单的定义文件中的数据类型和服务接口.以作为输入文件,编 ...
- 1 weekend110的复习 + hadoop中的序列化机制 + 流量求和mr程序开发
以上是,weekend110的yarn的job提交流程源码分析的复习总结 下面呢,来讲weekend110的hadoop中的序列化机制 1363157985066 13726230503 ...
- hadoop序列化机制与java序列化机制对比
1.采用的方法: java序列化机制采用的ObjectOutputStream 对象上调用writeObject() 方法: Hadoop 序列化机制调用对象的write() 方法,带一个DataOu ...
随机推荐
- Spark—local模式环境搭建
Spark--local模式环境搭建 一.Spark运行模式介绍 1.本地模式(loca模式):spark单机运行,一般用户测试和开发使用 2.Standalone模式:构建一个主从结构(Master ...
- browse下载插件DownThemAll!
DownThemAll!是一个不错的下载插件,它安装在各类browse上.
- 秒懂 Java 的三种代理模式
前言 代理(Proxy)模式是一种结构型设计模式,提供了对目标对象另外的访问方式:即通过代理对象访问目标对象. 这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. ...
- CSS 四种样式表 六种规则选择器 五种常用样式属性
新的html程序要在VS中编写了,在vs中安装ASP.NET和Web开发,并用ASP.NET Web 应用程序(.NETFramework)创建一个网页程序.添加一个html页 后面的代码都是在htm ...
- fiddler抓取手机模拟器数据
引自:https://blog.csdn.net/lengdaochuqiao/article/details/88170522 1.下载最新版fiddler ,强烈建议在官网下载:https://w ...
- GoAhead 远程命令执行漏洞(CVE-2017-17562)
poc地址 https://github.com/ivanitlearning/CVE-2017-17562 执行 msfvenom -a x64 --platform Linux -p linux/ ...
- Pytorch指定GPU的方法总结
Pytorch指定GPU的方法 改变系统变量 改变系统环境变量仅使目标显卡,编辑 .bashrc文件,添加系统变量 export CUDA_VISIBLE_DEVICES=0 #这里是要使用的GPU编 ...
- 零基础涂鸦智能面板SDK开发记录(一)
前言 本人基础背景:在学校学了点JS,在blbl上看过几节node.js视频,现在是一名Android开发工程师,因公司需要学习涂鸦面板SDK开发.说真的除了官方的一些文档外,我真的找不到其他的资料. ...
- anyRTC iOS端屏幕录制开发指南
一. 概述 实现直播过程中共享屏幕分为两个步骤:屏幕数据采集和流媒体数据推送.前对于 iOS 来说,屏幕采集需要系统的权限,受制于iOS系统的限制,第三方 app 并没有直接录制屏幕的权限,必须通过系 ...
- MySQL Shell import_table数据导入
目录 1. import_table介绍 2. Load Data 与 import table功能示例 2.1 用Load Data方式导入数据 2.2 用import_table方式导入数据 3. ...