mysql使用自增Id为什么存储比较快
转自:https://blog.csdn.net/bigtree_3721/article/details/73151028
InnoDB引擎表的特点
1、InnoDB引擎表是基于B+树的索引组织表(IOT)
关于B+树
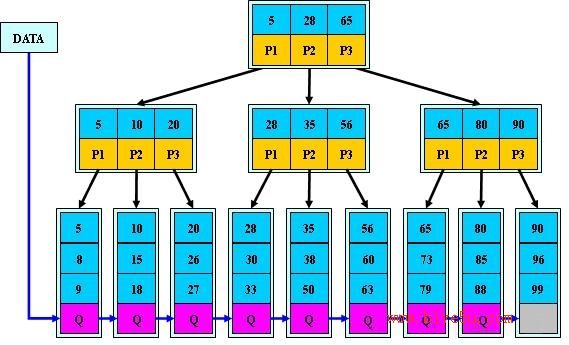
(图片来源于网上)
B+ 树的特点:
(1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2)不可能在非叶子结点命中;
(3)非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
2、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
3、数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
4、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
5、如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
1、使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
2、该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
《高性能MySQL》中的原话

欢迎关注
mysql使用自增Id为什么存储比较快的更多相关文章
- mysql 数据库自增id 的总结
有一个表StuInfo,里面只有两列 StuID,StuName其中StuID是int型,主键,自增列.现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,Stu ...
- MySQL 使用自增ID主键和UUID 作为主键的优劣比较详细过程(从百万到千万表记录测试)
测试缘由 一个开发同事做了一个框架,里面主键是uuid,我跟他建议说mysql不要用uuid用自增主键,自增主键效率高,他说不一定高,我说innodb的索引特性导致了自增id做主键是效率最好的,为了拿 ...
- MYSQL获取自增ID的四种方法
MYSQL获取自增ID的四种方法 1. select max(id) from tablename 2.SELECT LAST_INSERT_ID() 函数 LAST_INSERT_ID 是与tabl ...
- mysql数据库自增id重新从1排序的两种方法
mysql默认自增ID是从1开始了,但当我们如果有插入表或使用delete删除id之后ID就会不会从1开始了哦. 使用mysql时,通常表中会有一个自增的id字段,但当我们想将表中的数据清空重新添 ...
- DBS-MySQL:MYSQL获取自增ID的四种方法
ylbtech-DBS-MySQL:MYSQL获取自增ID的四种方法 1.返回顶部 1. 1. select max(id) from tablename 2.SELECT LAST_INSERT_I ...
- mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0
mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0 #将数据库表自增ID批量清零 SELECT CONCAT( 'ALTER TABLE ', TABLE_NAME, ' AUT ...
- mysql 返回自增id
String dateNow= DateTime.Now.ToString("yyyyMMddhhmmss"+ new Random().Next(1, 99)); //随机数 ...
- MySQL 使用自增ID主键和UUID 作为主键的优劣比較具体过程(从百万到千万表记录測试)
主键类型 SQL语句 运行时间 (秒) (1)模糊范围查询1000条数据,自增ID性能要好于UUID 自增ID SELECT SQL_NO_CACHE t.* FROM test.`UC_US ...
- MySQL中自增ID起始值修改方法
在实际测试工作过程中,有时因为生产环境已有历史数据原因,需要测试环境数据id从某个值开始递增,此时,我们需要修改数据库中自增ID起始值,下面以MySQL为例: 表名:users; 建表时添加: ); ...
随机推荐
- js和jquery获取当前元素的内容
html代码 <div>测试文本</div>js:div.innerHTMLjQuery:div.html()
- Python一行代码处理地理围栏
最近在工作中遇到了这个一个需求,用户设定地理围栏,后台获取到实时位置信息后通过与围栏比较,判断是否越界等. 这个过程需要用到数据协议为GEOjson,通过查阅资料后,发现python的shapely库 ...
- tornado websocket聊天室
1.app.py #!/usr/bin/env python # -*- coding:utf-8 -*- import uuid import json import tornado.ioloop ...
- 阿里云EDAS在本地CentOS7.5 系统搭建测试环境,部署配置中心以及部署多个war包
参考阿里云的EDAS开发文档: 使用 Ali-Tomcat 开发应用 我们自己在内网搭建CentOS7 的测试环境,需要的资源如下: Ali-Tomcat Pandora 容器 EDAS 配置中心安装 ...
- css3 学习 重点 常用
1 -webkit- -moz- -o-浏览器兼容 2 box-sizing:border-box; 两个近乎一样的div一样的样式 平分一个div 定义:属性允许您以确切的方式定义适 ...
- 安装 VS2017 的正确姿势
自从装了长城带宽,我的肠子就变成青色的了. 国内的网络环境,真的是有很大的不同,有的人装 VS 的时候,号称满速,有的人(其实就是我)要等它下载很久,还告诉我有个组件没有安装成功.很久很久以前,VS ...
- angularJs中怎么模拟jQuery中的this?
最近自己正在学习angularJs,在学到ng-click时,由于想获取当前点击元素的自身,开始想到了用$index来获取当前元素的索引同样能实现我想要的效果,但是在有些特殊的情况下,使用$index ...
- ubuntu17.04 调试系统工具bcc,systamtap安装
发行版 ubuntu17.04 cat lsb-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=17.04 DISTRIB_CODENAME=zesty DISTR ...
- Eclipse中jsp和html格式化自动排版问题
删除inline Elements 中所有的元素 http://m.codes51.com/article/detail_197472.html
- iOS:类似于网易云音乐的刷新条目显示弹框
一.介绍 在app中使用刷新控件或者第三方刷新库是最常见的功能,在请求服务器时,获取数据的过程是处于不可见状态的,那么通过这个刷新状态可以给用户以直观的感受,这是增强用户体验的一个相当好的方法.我个人 ...