python中文编码&json中文输出问题
python2.x版本的字符编码有时让人很头疼,遇到问题,网上方法可以解决错误,但对原理还是一知半解,本文主要介绍 python 中字符串处理的原理,附带解决 json 文件输出时,显示中文而非 unicode 问题。首先简要介绍字符串编码的历史,其次,讲解 python 对于字符串的处理,及编码的检测与转换,最后,介绍 python 爬虫采取的 json 数据存入文件时中文输出的问题。
参考书籍:Python网络爬虫从入门到实践 by唐松
在python 2或者3 ,字符串编码只有两类 :
(1)通用的Unicode编码;
(2)将Unicode转化为某种类型的编码,如UTF-8,GBK;
1、计算机历史:
计算机只处理数字,因此处理文本时,必须转换成数字才行。
8位(bit)=1字节(byte)=256种不同状态=从000000到111111;
1GB=1024M=1024(1024kb)=1024(1024(1024b));
ASCII编码 是对应英文字符与二进制数字之间的关系;ASCII一共规定了128种,如大写字母A是65,即01000001;可见一字母一字节;
GB2312编码 简体中文常见的编码,两个字节代表一个中文汉字 ,理论上256*256个编码,即可表示65536种中文字;
各国编码不同,为了各国能扩平台进行文本的转换与处理,Unicode就被作为统一码或者单一码。Unicode编码通常是两个字节,unicode与ASCII编码的区别,在于unicode在ASCII编码前加了一个0,即字母A的ASCII编码为01000001,unicode编码即为0000000001000001;但英文字母其实只用一个字节就够了,unicode编码写英文时多了一个字节,浪费存储空间。因而unicode开发了通用转换格式(Unicode Transformation Format(UTF)),常见的有utf-8或者utf-16;
2、python字符编码
参考地址:https://www.jb51.net/article/139878.htm
(1)encode的作用是,将unicode对象编码成其他编码的字符串,str.encode('utf-8'),编码成UTF-8;(2)decode的作用是将其他编码的字符串转换成Unicode编码,str.decode('UTF-8');
- import chardet 查阅具体的编码类型,
chardet.detect(str),但是str不能是unicode编码类型,但是该方法 不接受 本来已经是unicode的编码的 参数,会有TypeError: Expected object of type bytes or bytearray, got: <type 'unicode'>错误; - 作为统一标准,unicode不能再被解码,如果UTF-8想转至其他非unicode,则必须(2)先decode 到unicode,在encode到其他非unicode的编码。
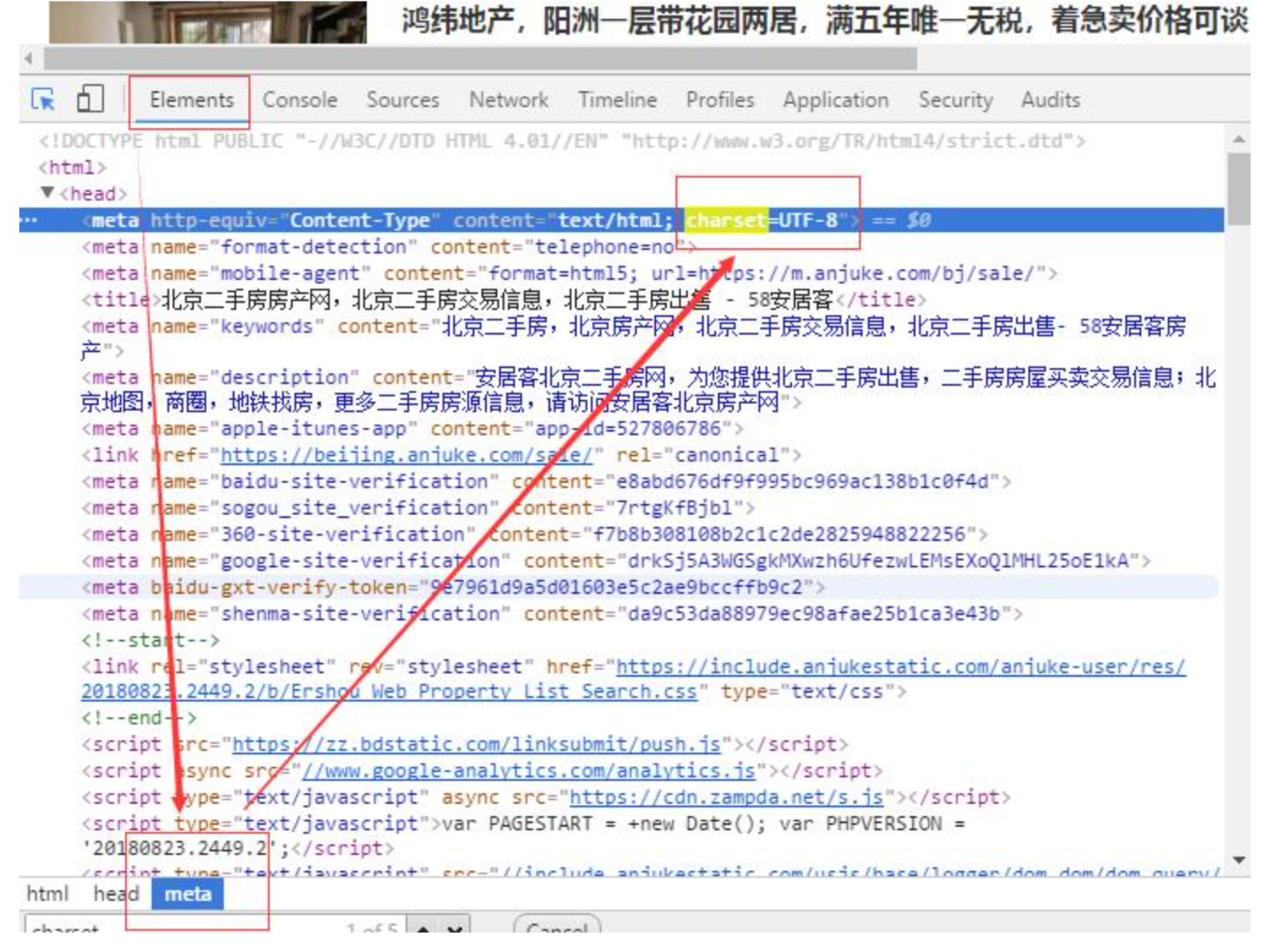
爬取网页时,可在F12 elements meta中查看网页编码方式,如图:
(2)中文,Python中的字典能够被序列化到json文件中存入json
with open("anjuke_salehouse.json","w",encoding='utf-8') as f:
json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4);
print(u'加载入文件完成...');
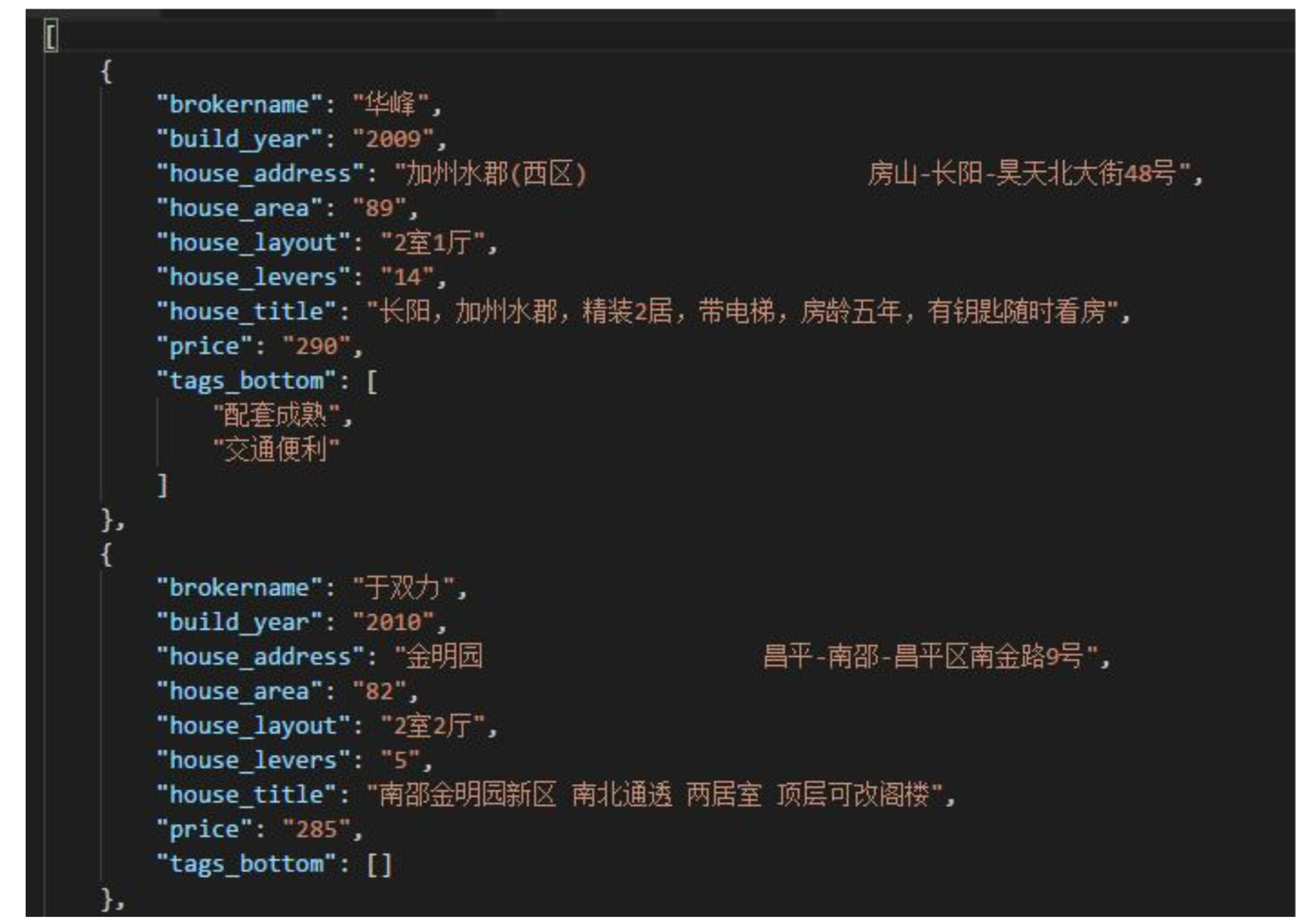
存储数据如图:
- dump()的第一个参数是要序列化的对象,第二个参数是打开的文件句柄,注意文件打开
open()时加上以UTF-8编码打开,在dump()的时候也加上ensure_ascii=False,不然会变成ascii码写到json文件中json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)
json.dumps()/json.loads()等用法
json_str = json.dumps(all_house,ensure_ascii=False); #all——books 为列表、字典等python自带的数据结构,将其写成json
#print json_str; #[{"brokername": "王东宇"},{},{}]
new_dict = json.loads(json_str);#主要是读json文件时,需要用到
#print new_dict; #{u'house_area': u'95', u'build_year': u'2005'}
- json.dumps() 是将一个Python数据结构转换为一个JSON编码的字符串,
{"name": "xiaoming"}
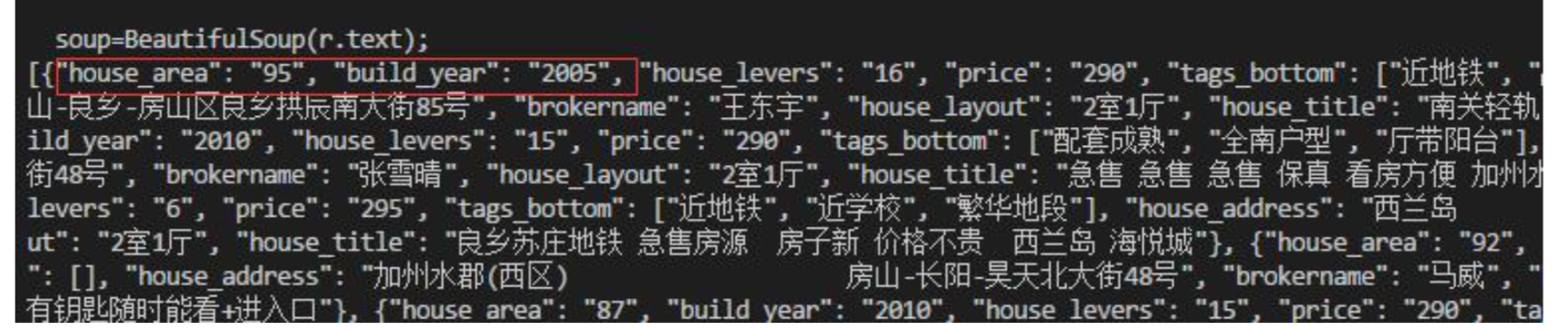
json.loads() 是将一个JSON编码的字符串(字典形式)转换为一个Python数据结构,{u'name': u'xiaoming'}

dumps转化后键与值都变成了双引号,而在loads后变成python变量时,元素都变成了单引号,并且字符串前加多了个u。
一般要求当要字符串通过loads转为python数据类型时,得外层用单引号,里面元素key和value用双引号。
- sort_keys:根据key排序
dump与dumps的区别
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);dump将一个对象序列化存入文件,dump需要一个类似于文件指针的参数(并不是真的指针,可称之为类文件对象),可以与文件操作结合,也就是说可以将dict转成str存入文件中,如json.dump(all_house,f,ensure_ascii=False,sort_keys=True, indent=4)中的f表示一个数据待写入的json文件句柄;dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw);而dumps(str)直接给的是str,也就是直接将字典转成str,无需写入文件,类似一个数据格式的转换方法,将python字符串转成json字典。- 所以dumps是将dict转化成str格式,loads是将str转化成dict格式。
dump和load也是类似的功能,只是与文件操作结合起来了。
(3)中文存入txt
f=open('net_saving_data.txt','w',encoding='utf-8');
for item in all_house:
# house_area=item['house_area'];
# price=item['price'];
output='\t'.join([str(item['house_area']),str(item['price']),str(item['build_year']),str(item['house_title'])]);
f.write(output);
f.write('\n');
f.close();

- 在2.7.15版本的python中,提示错误
TypeError: 'encoding' is an invalid keyword argument for this function,无法传入encoding的参数,但是在3.7版本可传入encoding='utf-8'参数,即可对 txt进行中文写入。
!!NOTE
- 中文写入txt、json文件是无非就是open()文件时,需要添加utf-8,dump()时,需要添加ensure_ascii=False,防止ascii编码,但是刚开始因为python版本是2.7.15,不是3.7,导致存储不成功的时候,一直以为是代码的问题。所以最后发现就是版本的问题,也挺伤的。网上关于中文这个编码问题有很多,但是他们都没有强调python版本的问题!!!其他3.xx的版本没有试过。
- 读取网页数据的时候,查看网页的charset,及chardet库对编码类型的查询,及时进行decode和encode的编码转化,应该就能避免很多编码问题了。其他的坑以后踩了再补吧。
python中文编码&json中文输出问题的更多相关文章
- Python进行JSON格式化输出,以及汉字显示问题
格式化输出 转载地址 https://blog.csdn.net/real_tino/article/details/76422634 问题分析: Python下json手法的json在打印查看时, ...
- Python下json中文乱码解决办法
json.dumps在默认情况下,对于非ascii字符生成的是相对应的字符编码,而非原始字符,只需要 #coding=utf8 import json js = json.loads('{" ...
- python 写入JSON中文乱码解决方法
在将一个字典添加入json中时多加入一个参数就可以了 json.dumps(dict(item), ensure_ascii=False) 例子 with open('zh-cn.json','w', ...
- python 格式化 json输出
利用python格式化json 字符串输出. $ echo '{"json":"obj"}' | python -m json.tool 利用python -m ...
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码 python的json.dumps方法默认会输出成这种格式"\u535a\u ...
- python json.dumps输出中文问题
json.dumps 输出的中文是"\u6211\u662f"格式的,输出中文需要指定ensure_ascii=False. json.dumps(actual,ensure_as ...
- python的 json.dumps 中文编码
python的 json.dumps 中文编码 # -- coding: utf-8 -- 的作用:文件内容以utf-8编码 json.dumps 序列化时对中文默认使用的ascii编码, print ...
- python 把数据 json格式输出
有个要求需要在python的标准输出时候显示json格式数据,如果缩进显示查看数据效果会很好,这里使用json的包会有很多操作 import json date = {u'versions': [{u ...
- Windows下Python中的中文路径和中文输出问题
这几天有个项目需要写一点类似于脚本的小程序,就用Python写了,涉及到中文路径和中文输出的问题,整理一下. 有一个问题我觉得需要先强调一下,在写Python程序的时候,一定保证编码是utf-8,然后 ...
随机推荐
- Mac 下 软件安装路径查看 命令: Which, 估计Linux 也是
✘ marikobayashi@juk ~ which git /usr/bin/git marikobayashi@juk ~ which maven maven not found ...
- iostat 命令详解
前言 话说搞运维的人没有两把"刷子",都不好意思上服务器操作.还好,我还不是搞运维的,我一直都自诩是开发人员,奈何现在的东家运维人员"水"的一比,还要我这个自诩 ...
- 背水一战 Windows 10 (85) - 文件系统: 获取文件夹和文件, 分组文件夹, 排序过滤文件夹和文件, 搜索文件
[源码下载] 背水一战 Windows 10 (85) - 文件系统: 获取文件夹和文件, 分组文件夹, 排序过滤文件夹和文件, 搜索文件 作者:webabcd 介绍背水一战 Windows 10 之 ...
- 47_并发编程-线程python实现
一.Threading模块 1.线程的创建 - 方式一 from threading import Thread import time def sayhi(name): time.sleep(2 ...
- jdk8新特性---list.stream
项目中用到了该api ,记录下来 具有get set 构造方法的实体类 开始使用: 结果为: 更多可以参考: https://blog.csdn.net/justloveyou_/article/de ...
- 数据库之SqlDataAdapter
SqlDataAdapter 类 表示用于填充 DataSet 和更新 SQL Server 数据库的一组数据命令和一个数据库连接.无法继承此类. 命名空间:System.Data.SqlClient ...
- Python:标准库(包含下载地址及书本目录)
下载地址 英文版(文字版) 官方文档 The Python Standard Library <Python标准库>一书的目录 <python标准库> 译者序 序 前言 第1章 ...
- 配置 Nginx 的目录浏览功能
Nginx 默认是不允许列出整个目录的,需要配置 Nginx 自带的 ngx_http_autoindex_module 模块实现目录浏览功能 . location / { alias /opt/fi ...
- MD5加密之加密字符串
public static String encode(String str) { String encodeString = ""; try { MessageDigest md ...
- docker push 出现:x509: certificate signed by unknown authority
今天,部署生产的程序的时候,出现一个问题:编译正常,但是,docker 把编译好的image 推送到生产环境上去的时候,出现:x509: certificate signed by unknown a ...