Lucene创建索引流程

1.创建索引流程
原始文档:互联网上的网页(爬虫或蜘蛛)、数据库中的数据、磁盘上的文件
创建文档对象(非结构化数据)
文档对象中的属性不叫属性现在成为域。
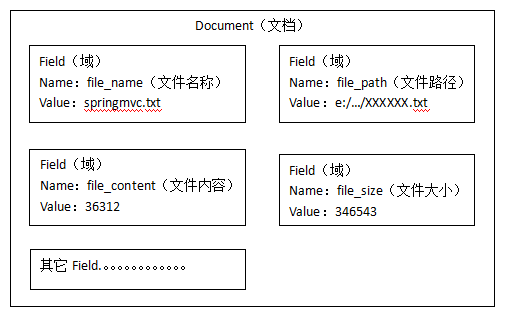
每个 Document 可以有多个 Field ,不同的 Document 可以有不同的 Field,同一个 Document 可以有相同的 Field(域名和域值都相同)。
每个文档都有一个唯一的编号,就是文档id
分析文档
将原始内容包含域的文档,需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的词汇单元,可以将词汇单元理解为一个个单词。
原文档内容:
Luncene is a Java full-text search engine.
分析后得到的语汇单元:
lucene、java、full、search、engine…
每个单词叫做一个 Term,不同的域中拆分出来相同的单词是不同的 Term。Term中包含两部分一部分是文档的域名,另一部分是单词的内容。 Term K 域(文件名称) V spring Term K 域(文件内容) V spring 刚才两个Tream不是一个
创建索引
对所有文档分析得出的语汇单元进行创建索引,创建索引的目地是为了搜索,最终要实现只搜索被搜索的语汇单元从而找到 Document(文档)
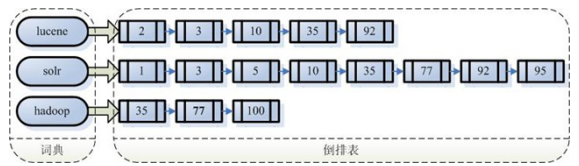
注意:创建索引是对语汇索引,通过词语找文档,这种索引的结构叫倒排索引结构。包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
传统方式是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描法,数据量大、搜索慢
// 创建索引
@Test
public void testIndex() throws Exception {
// 第一步创建一个indexwriter对象
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
// Directory directory2 = new RAMDirectory();//保存索引到内存中(内存索引库)
//Analyzer analyzer = new StandardAnalyzer();// 官方推荐
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 第三步创建Filed域,将field添加到document对象中
File f = new File("D:\\Lucent&solr\\searchsoure");
File[] listFiles = f.listFiles();
for (File file : listFiles) {
// 第二步创建Document对象
Document document = new Document();
// 文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
// 文件大小
long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize", file_size, Store.YES);
// 文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
// 文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent", file_content, Store.NO);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
// 第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库
indexWriter.addDocument(document);
}
// 第五步:关闭IndexWriter对象
indexWriter.close();
}
// 查询索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁盘硬盘库
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader = DirectoryReader.open(directory);// 流
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
Query query = new TermQuery(new Term("fileName", "java"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 2);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 文档id
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("-----------------");
}
// 第七步:关闭IndexReader对象
indexReader.close();
}
Lucene创建索引流程的更多相关文章
- lucene创建索引简单示例
利用空闲时间写了一个使用lucene创建索引简单示例, 1.使用maven创建的项目 2.需要用到的jar如下: 废话不多说,直接贴代码如下: 1.创建索引的类(HelloLucene): packa ...
- Lucene创建索引和索引的基本检索(Lucene 之 Hello World)
Author: 百知教育 gaozhy 注:演示代码所使用jar包版本为 lucene-xxx-5.2.0.jar 一.lucene索引操作 1.创建索引代码 try { // 1. 指定索引文件存 ...
- lucene创建索引
创建索引. 1.lucene下载. 下载地址:http://archive.apache.org/dist/lucene/java/. lucene不同版本之间有不小的差别,这里下载的是lucene ...
- lucene创建索引的几种方式(一)
什么是索引: 根据你输入的值去找,这个值就是索引 第一种创建索引的方式: 根据文件来生成索引,如后缀为.txt等的文件 步骤: 第一步:FSDirectory.open(Paths.get(url)) ...
- 搜索引擎学习(二)Lucene创建索引
PS:需要用到的jar包: 代码实现 1.工程结构 2.设置工程依赖的jar包 3.代码实现 /** * Lucene入门 * 创建索引 */ public class CreateIndex { / ...
- 第五步:Lucene创建索引
package cn.lucene; import java.io.IOException; import java.nio.file.Paths; import java.util.Date; im ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Lucene 4.7 --创建索引
Lucene的最新版本和以前的语法或者类名,类规定都相差甚远 0.准备工作: 1). Lucene官方API http://lucene.apache.org/core/4_7_0/index.htm ...
- Lucene.net 从创建索引到搜索的代码范例
关于Lucene.Net的介绍网上已经很多了在这里就不多介绍Lucene.Net主要分为建立索引,维护索引和搜索索引Field.Store的作用是通过全文检查就能返回对应的内容,而不必再通过id去DB ...
随机推荐
- OC学习4——OC新特性之块(Block)
文章主要参考 关于OC中的block自己的一些理解(一) 对块的深入理解 浅析ios开发中Block块语法的妙用 1.关于block block的作用:保存一段代码. 苹果官方推荐的一种语法,类似 ...
- [SDOI2006] 二进制方程
并查集水题.维护变量的对应位的相关关系,判断不确定点(自由元)的个数即可. 代码中的p数组:p[1] 值的id, p[2~k+1]每个变量的第一位的id. #include <bits/stdc ...
- C# 串口类SerialPort的使用方法
序言:最近做了一个智能体育项目——跆拳道积分系统,硬件部分会向软件传入振动值等数据,链接方式为串口,所以用到SerialPort类. 值得注意的是: DataReceived 方法,当串口缓冲区有数据 ...
- ABP实践(3)-ASP.NET Core 2.x版本(从创建实体到输出api)简单实现商品列表及增删改
项目基于前两篇文章. 本章创建一个简单版的商品管理后台api,用到EF Core用code fist迁移数据创建数据库. 创建Goods实体 在领域层xxx.Core项目[新建文件夹Goods;文件夹 ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(十四):项目打包部署
项目打包部署 安装MySQL镜像 注意:如果使用docker镜像安装MySQL,也需要在前端部署主机安装MySQL,因为备份还原功能是使用MySQL的本地命令进行操作的. 下载镜像 执行以下命令,拉取 ...
- paperpass
推荐大家一个靠谱的论文检测平台.重复的部分有详细出处以及具体修改意见,能直接在文章上做修改,全部改完一键下载就搞定了.怕麻烦的话,还能用它自带的降重功能.哦对了,他们现在正在做毕业季活动, 赠送很多免 ...
- pythonic(fork)
转载 https://wuzhiwei.net/be_pythonic/
- 搭建前端监控系统(四)Js截图上报篇
===================================================================== 前端监控系统: DEMO地址 GIT代码仓库地址 ==== ...
- VUE模仿百度搜索框,按上下方向键及回车键实现搜索选中效果
逻辑介绍: 1.表单获取焦点时,显示搜索建议框 2.输入内容时,请求后台接口,并将返回的数据展示在搜索建议框内 3.表单获取焦点情况下,按键盘上下箭头可实现搜索列表项的切换,按回车可以选择当前激活的选 ...
- C# 常用的加密代码参考
1.MD5加密 public static string EncryptString(string source) { string result; if (source == string.Empt ...