Lucene创建索引流程

1.创建索引流程
原始文档:互联网上的网页(爬虫或蜘蛛)、数据库中的数据、磁盘上的文件
创建文档对象(非结构化数据)
文档对象中的属性不叫属性现在成为域。
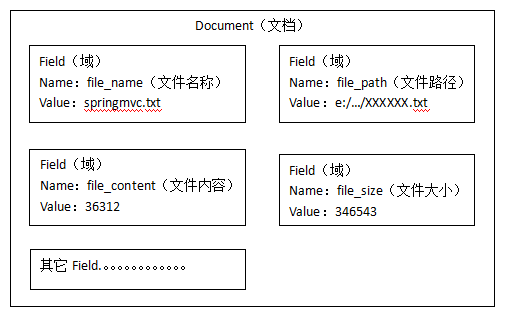
每个 Document 可以有多个 Field ,不同的 Document 可以有不同的 Field,同一个 Document 可以有相同的 Field(域名和域值都相同)。
每个文档都有一个唯一的编号,就是文档id
分析文档
将原始内容包含域的文档,需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的词汇单元,可以将词汇单元理解为一个个单词。
原文档内容:
Luncene is a Java full-text search engine.
分析后得到的语汇单元:
lucene、java、full、search、engine…
每个单词叫做一个 Term,不同的域中拆分出来相同的单词是不同的 Term。Term中包含两部分一部分是文档的域名,另一部分是单词的内容。 Term K 域(文件名称) V spring Term K 域(文件内容) V spring 刚才两个Tream不是一个
创建索引
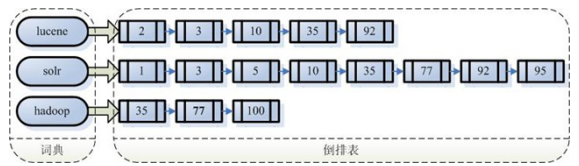
对所有文档分析得出的语汇单元进行创建索引,创建索引的目地是为了搜索,最终要实现只搜索被搜索的语汇单元从而找到 Document(文档)
注意:创建索引是对语汇索引,通过词语找文档,这种索引的结构叫倒排索引结构。包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
传统方式是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描法,数据量大、搜索慢
// 创建索引
@Test
public void testIndex() throws Exception {
// 第一步创建一个indexwriter对象
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
// Directory directory2 = new RAMDirectory();//保存索引到内存中(内存索引库)
//Analyzer analyzer = new StandardAnalyzer();// 官方推荐
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 第三步创建Filed域,将field添加到document对象中
File f = new File("D:\\Lucent&solr\\searchsoure");
File[] listFiles = f.listFiles();
for (File file : listFiles) {
// 第二步创建Document对象
Document document = new Document();
// 文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
// 文件大小
long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize", file_size, Store.YES);
// 文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
// 文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent", file_content, Store.NO);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
// 第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库
indexWriter.addDocument(document);
}
// 第五步:关闭IndexWriter对象
indexWriter.close();
}
// 查询索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁盘硬盘库
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader = DirectoryReader.open(directory);// 流
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
Query query = new TermQuery(new Term("fileName", "java"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 2);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 文档id
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("-----------------");
}
// 第七步:关闭IndexReader对象
indexReader.close();
}
Lucene创建索引流程的更多相关文章
- lucene创建索引简单示例
利用空闲时间写了一个使用lucene创建索引简单示例, 1.使用maven创建的项目 2.需要用到的jar如下: 废话不多说,直接贴代码如下: 1.创建索引的类(HelloLucene): packa ...
- Lucene创建索引和索引的基本检索(Lucene 之 Hello World)
Author: 百知教育 gaozhy 注:演示代码所使用jar包版本为 lucene-xxx-5.2.0.jar 一.lucene索引操作 1.创建索引代码 try { // 1. 指定索引文件存 ...
- lucene创建索引
创建索引. 1.lucene下载. 下载地址:http://archive.apache.org/dist/lucene/java/. lucene不同版本之间有不小的差别,这里下载的是lucene ...
- lucene创建索引的几种方式(一)
什么是索引: 根据你输入的值去找,这个值就是索引 第一种创建索引的方式: 根据文件来生成索引,如后缀为.txt等的文件 步骤: 第一步:FSDirectory.open(Paths.get(url)) ...
- 搜索引擎学习(二)Lucene创建索引
PS:需要用到的jar包: 代码实现 1.工程结构 2.设置工程依赖的jar包 3.代码实现 /** * Lucene入门 * 创建索引 */ public class CreateIndex { / ...
- 第五步:Lucene创建索引
package cn.lucene; import java.io.IOException; import java.nio.file.Paths; import java.util.Date; im ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Lucene 4.7 --创建索引
Lucene的最新版本和以前的语法或者类名,类规定都相差甚远 0.准备工作: 1). Lucene官方API http://lucene.apache.org/core/4_7_0/index.htm ...
- Lucene.net 从创建索引到搜索的代码范例
关于Lucene.Net的介绍网上已经很多了在这里就不多介绍Lucene.Net主要分为建立索引,维护索引和搜索索引Field.Store的作用是通过全文检查就能返回对应的内容,而不必再通过id去DB ...
随机推荐
- 转载 Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- RawConfigParser 与 ConfigParser ——Python的配件文件读取模块
一般情况都是使用ConfigParser这个方法,但是当我们配置中有%(filename)s这种格式的配置的时候,可能会出现以下问题: configparser.InterpolationMissin ...
- (转)内核模块操作命令-lsmod+rmmod+modinfo+modprobe
原文:http://watchmen.xin/2018/07/13/IT%E7%A7%91%E5%AD%A6%E6%8A%80%E6%9C%AF%E7%9F%A5%E8%AF%86%E4%BD%93% ...
- [教程向]__在IDEA中使用git+github实现代码的版本控制
前言 在前面,我们对git与github有了一个简单的了解,了解到版本控制的必要性,和github远程代码仓库的一些作用.那么我们如何在IDEA重实现代码的版本控制呢. 前提 首先你要安装有git,注 ...
- 从零开始学 Web 之 ES6(三)ES6基础语法一
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- FC游戏 《三国志2-霸王的大陆》攻略
<三国志2-霸王的大陆>是日本南梦宫公司研发的一款历史战略模拟游戏,于1992年06月10日在红白机平台上发行. 在开始游戏选择君主时(一定要在君主未出现前的画面时进行第二步),按住1P的 ...
- dfs问题总结
组合总和——给定元素不重复 需求:给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candida ...
- php 常用$_SERVER变量列表
$_SERVER['HTTP_ACCEPT_LANGUAGE'] //浏览器语言 $_SERVER['REMOTE_ADDR'] //当前用户 IP . $_SERVER['REMOTE_HOST'] ...
- c# UTF-16转UTF-8 互转
/// <summary> /// UTF-16转UTF-8 /// </summary> /// <param name="str">< ...
- Java学习笔记之——静态方法
1.方法的定义 定义在类中,方法是独立的 2.语法: public static 返回值类型 方法名(形参列表){ 方法中的具体代码: } 1)方法名:在同一个类中方法名不能重复 命名规则:驼峰 ...