SQL Server数据归档的解决方案
最近新接到的一项工作是把SQL Server中保存了四五年的陈年数据(合同,付款,报销等等单据)进行归档,原因是每天的数据增量很大,而历史数据又不经常使用,影响生产环境的数据查询等操作。要求是:
1 归档的数据与生产环境数据分开保存,以便提高查询效率和服务器性能。
2 前端用户能够查询已归档的数据,即系统提供的功能不能发生改变
看起来要求不是很高,我自然会联想到两种方法,第一种新建一个与生产环境一样的数据库,把归档数据保存到这个数据库中;第二种在生产环境为每个表创建一个后缀为_Archive的表,例如Invoice, 那么就要创建一个Invoice_Archive表示存放归档的数据表。这两种方法可以用跨数据库访问或视图的方式,解决数据查询等需求。仔细分析后,弊端是需要对现行系统进行改造,即需要修改代码,以便适应对归档数据的访问,实际也把数据访问和业务操作给藕荷了,是一个费力又不讨好的解决方法。
有没有一种方法可以不修改系统能够透明的访问生产数据和归档数据呢?当然是有的,就是SQL Server提供的分区表。
在这里就不累赘复述分区表的定义和作用了,要想精通就要认真读微软官方文档:SQL Server 2005 中的分区表和索引。我浓缩的作用就是,通过使用分区表可以将数据表分割到不用的磁盘文件中,不同的磁盘就意味着性能的提升,因为两个磁头读取数据当然要比一个磁头读取数据快了,然后用户可以透明地根据不同的访问方式选取数据。举个例子:一个合同表,有个字段Archived标识是否归档(0代表未归档,1代表已归档),我们可以用分区表的方式,将合同表分成两个表分别保存在不同的磁盘,例如c和d, 当我们将一个合同设置为已归档,这条记录就会从c盘转到d盘,平时我们只查询未归档的记录,如果要查已归档的记录,也只需要select * from Contracts where Archived = 1这么简单,即透明的查询,具体的实现我们不用关心。
好了,不能光说不练,就验证一下。创建两个文件目录
创建一个测试数据库
USE Master;
GO
IF EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TestDB')
DROP DATABASE TestDB;
GO
CREATE DATABASE TestDB
ON PRIMARY
(NAME='TestDB_Part1',
FILENAME=
'D:\TestData\Primary\TestDB_Part1.mdf',
SIZE=,
MAXSIZE=,
FILEGROWTH= ),
FILEGROUP TestDB_Part2
(NAME = 'TestDB_Part2',
FILENAME =
'D:\TestData\Secondary\TestDB_Part2.ndf',
SIZE = ,
MAXSIZE=,
FILEGROWTH= );
GO
查看数据属性,有点不一样
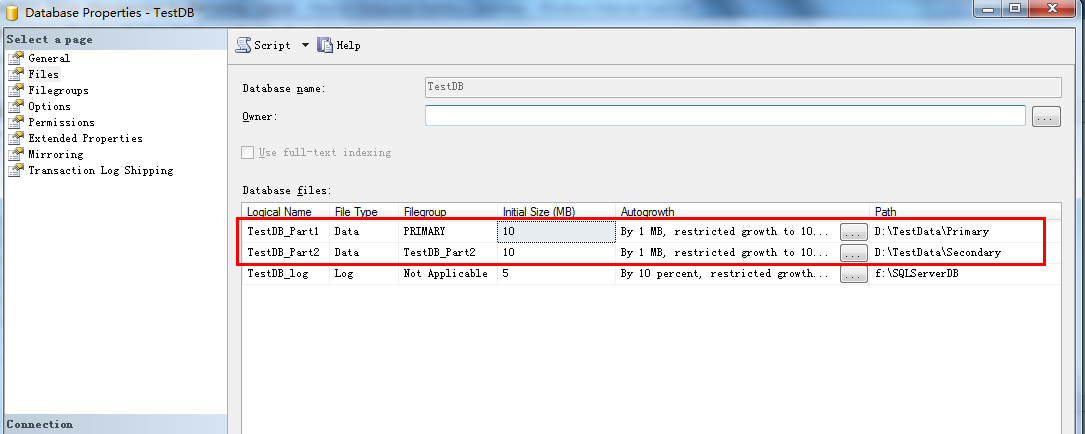
打开数据:
新建分区函数,参数类型是bit,即已归档的数据
新建一个分区方案,即已经归档的数据保存到TestDB_Part2分区文件上
创建一个测试数据表,绑定一个分区方案
插入一些新的数据,已供测试
先来一个普通查询

看看每个分区表存放数据的情况,分区一有3条记录,分区2没有记录,即没有归档数据

好了,我们归档一条记录看看

结果就是我们想要的。
总结:利用分区表不仅能大幅提升数据访问性能,而且可以根据需要分别存储数据到不同的文件,方便我们有效地利用数据,简化系统开发的复杂性。
SQL Server数据归档的解决方案的更多相关文章
- C#向sql server数据表添加数据源代码
HoverTree解决方案 学习C#.NET,Sql Server,WinForm等的解决方案. 本文链接http://hovertree.com/h/bjaf/0jteg8cv.htm 使用的技术. ...
- 推荐图书-《SQL Server 2008商业智能完美解决方案》
内容简介 <SQL Server 2008商业智能完美解决方案>介绍如何使用Microsoft SQL Server 2008开发商业智能(BI)解决方案.<SQL Server 2 ...
- SQL Server 2008R2 18456错误解决方案
SQL Server 2008R2 18456错误解决方案 微软解释说,因密码或用户名错误而使身份验证失败并导致连接尝试被拒时,类似下面的消息将返回到客户端:“用户 '<user_name> ...
- Docker-compose搭建ELK环境并同步MS SQL Server数据
前言 本文作为学习记录,供大家参考:一次使用阿里云(Aliyun)1核2G centos7.5 云主机搭建Docker下的ELK环境,并导入MS SQL Server的商品数据以供Kibana展示的配 ...
- SQL server数据缓存依赖
SQL server数据缓存依赖有两种实现模式,轮询模式,通知模式. 1 轮询模式实现步骤 此模式需要SQL SERVER 7.0/2000/2005版本以上版本都支持 主要包含以下几 ...
- [SQL]SQL Server数据表的基础知识与增查删改
SQL Server数据表的基础知识与增查删改 由张晨辉(学生) 于19天 前发表 | 阅读94次 一.常用数据类型 .整型:bigint.int.smallint.tinyint .小数:decim ...
- Sql Server数据的加密与解密
Sql Server数据的加密与解密 在sql server中,我们如何为数据进行加密与解密,避免使用者窃取机密数据? 对于一些敏感数据,如密码.卡号,一般不能使用正常数值来存储.否则会有安全隐患.以 ...
- delphi 2010 导出sql server 数据到DBF乱码问题
近日,由于业务需要导出sql server 数据到DBF文件,要查询多表记录,并适当处理后生成导出DBF文件,系统使用delphi2010平台开发. 首先按要求在VFP里创建DBF表,字段数有240个 ...
- SQL server数据库内置账户SA登录设置
SQL server数据库内置账户SA登录不了 设置SQL Server数据库给sa设置密码的时候 提示18456 解决步骤: 第二步:右击sa,选择属性: 第三步:点击状态选项卡:勾选授予 ...
随机推荐
- [No000018D]Vim快速注释/取消注释多行的几种方法-Vim使用技巧(2)
在使用Vim进行编程时,经常遇到需要快速注释或取消注释多行代码的场景,Vim教程网根据已有的教程介绍,总结了三种快速注释/取消注释多行代码的方法. 一.使用Vim可视化模式快速注释/取消注释多行 在V ...
- PTA 复数四则运算
本题要求编写程序,计算2个复数的和.差.积.商. 输入格式: 输入在一行中按照a1 b1 a2 b2的格式给出2个复数C1=a1+b1i和C2=a2+b2i的实部和虚部.题目保证C2不为0. 输出格式 ...
- qemu对虚拟机的内存管理(二)
上篇文章主要分析了qemu中对虚拟机内存管理的关键数据结构及他们之间的联系,这篇文章则主要分析在地址空间发生变化时,如何将其更新至KVM中,保持用户空间与内核空间的同步. 这一系列操作与之前说的Add ...
- Centos7.1环境下搭建SVN
环境准备: 系统 配置 IP Centos7.1 1核2G+60GB硬盘 10.10.28.204 1.安装 sudo yum install subversion 查看版本 svnserve –-v ...
- linux 防火墙 iptables 目录
linux iptables 防火墙简介 Linux 防火墙:Netfilter iptables 自动化部署iptables防火墙脚本
- airsim 无法打开包括文件corecrt.h
原因: 显示无法打开包括文件corecrt.h.在网上找了很多方法,最后综合起来发现,这个问题网上很多人反映,应该是vs2015的一个BUG,如果是选择"从父级或项目默认设置继承" ...
- RabbitMQ:Docker环境下搭建rabbitmq集群
RabbitMQ作为专业级消息队列:如何在微服务框架下搭建 使用组件 文档: https://github.com/bijukunjummen/docker-rabbitmq-cluster 下载镜像 ...
- 解决bootstrap 模态框 数据清除 验证清空
$("#switchModel").on("hidden.bs.modal", function () { $('#ware-form')[0].reset() ...
- linux下git服务器安装
git服务器配置http://www.cnblogs.com/dee0912/p/5815267.html git教程https://www.liaoxuefeng.com/wiki/00137395 ...
- wrap
import 'package:flutter/material.dart'; void main() { runApp(MaterialApp(home: new MyApp())); } clas ...