Linux下配置Redis集群模式
Redis 集群是一个分布式(distributed)、容错(fault-tolerant)的 Redis 实现, 集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集(subset)。
Redis 集群中不存在中心(central)节点或者代理(proxy)节点, 集群的其中一个主要设计目标是达到线性可扩展性(linear scalability)。
Redis 集群为了保证一致性(consistency)而牺牲了一部分容错性: 系统会在保证对网络断线(net split)和节点失效(node failure)具有有限(limited)抵抗力的前提下, 尽可能地保持数据的一致性。
集群将节点失效视为网络断线的其中一种特殊情况。
集群的容错功能是通过使用主节点(master)和从节点(slave)两种角色(role)的节点(node)来实现的:
- 主节点和从节点使用完全相同的服务器实现, 它们的功能(functionally)也完全一样, 但从节点通常仅用于替换失效的主节点。
- 不过, 如果不需要保证“先写入,后读取”操作的一致性(read-after-write consistency), 那么可以使用从节点来执行只读查询。
配置机器1
- 在演示中,172.16.179.130为当前ubuntu机器的ip
- 在172.16.179.130上进⼊Desktop⽬录,创建conf⽬录
在conf⽬录下创建⽂件7000.conf,编辑内容如下
port 7000
bind 172.16.179.130
daemonize yes
pidfile 7000.pid
cluster-enabled yes
cluster-config-file 7000_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7001.conf,编辑内容如下
port 7001
bind 172.16.179.130
daemonize yes
pidfile 7001.pid
cluster-enabled yes
cluster-config-file 7001_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7002.conf,编辑内容如下
port 7002
bind 172.16.179.130
daemonize yes
pidfile 7002.pid
cluster-enabled yes
cluster-config-file 7002_node.conf
cluster-node-timeout 15000
appendonly yes
总结:三个⽂件的配置区别在port、pidfile、cluster-config-file三项
使⽤配置⽂件启动redis服务
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf
查看进程如下图

配置机器2
- 在演示中,172.16.179.131为当前ubuntu机器的ip
- 在172.16.179.131上进⼊Desktop⽬录,创建conf⽬录
在conf⽬录下创建⽂件7003.conf,编辑内容如下
port 7003
bind 172.16.179.131
daemonize yes
pidfile 7003.pid
cluster-enabled yes
cluster-config-file 7003_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7004.conf,编辑内容如下
port 7004
bind 172.16.179.131
daemonize yes
pidfile 7004.pid
cluster-enabled yes
cluster-config-file 7004_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7005.conf,编辑内容如下
port 7005
bind 172.16.179.131
daemonize yes
pidfile 7005.pid
cluster-enabled yes
cluster-config-file 7005_node.conf
cluster-node-timeout 15000
appendonly yes
总结:三个⽂件的配置区别在port、pidfile、cluster-config-file三项
使⽤配置⽂件启动redis服务
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf
查看进程如下图

创建集群
- redis的安装包中包含了redis-trib.rb,⽤于创建集群
- 接下来的操作在172.16.179.130机器上进⾏
将命令复制,这样可以在任何⽬录下调⽤此命令
sudo cp /usr/share/doc/redis-tools/examples/redis-trib.rb /usr/local/bin/
安装ruby环境,因为redis-trib.rb是⽤ruby开发的
sudo apt-get install ruby
在提示信息处输⼊y,然后回⻋继续安装

运⾏如下命令创建集群
redis-trib.rb create --replicas 1 172.16.179.130:7000 172.16.179.130:7001 172.16.179.130:7002 172.16.179.131:7003 172.16.179.131:7004 172.16.179.131:7005
执⾏上⾯这个指令在某些机器上可能会报错,主要原因是由于安装的 ruby 不是最 新版本!
天朝的防⽕墙导致⽆法下载最新版本,所以需要设置 gem 的源
解决办法如下
-- 先查看⾃⼰的 gem 源是什么地址
gem source -l -- 如果是https://rubygems.org/ 就需要更换
-- 更换指令为
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
-- 通过 gem 安装 redis 的相关依赖
sudo gem install redis
-- 然后重新执⾏指令
redis-trib.rb create --replicas 1 172.16.179.130:7000 172.16.179.130:7001 172.16.179.130:7002 172.16.179.131:7003 172.16.179.131:7004 172.16.179.131:7005- 提示如下主从信息,输⼊yes后回⻋
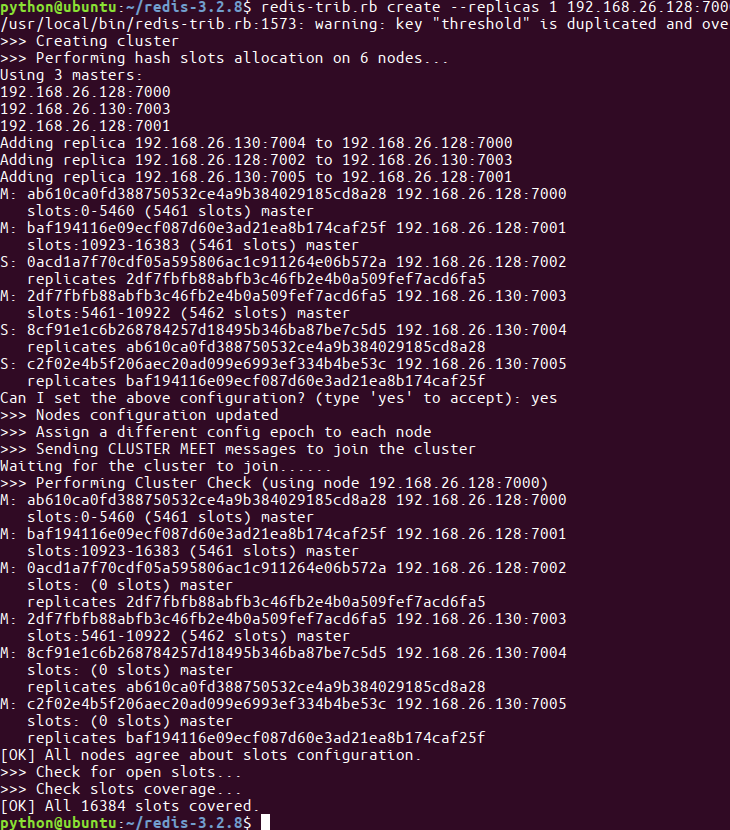
- 提示完成,集群搭建成功
数据验证
- 根据上图可以看出,当前搭建的主服务器为7000、7001、7003,对应的从服务器是7004、7005、7002
在172.16.179.131机器上连接7002,加参数-c表示连接到集群
redis-cli -h 172.16.179.131 -c -p 7002
写⼊数据
set name itheima
⾃动跳到了7003服务器,并写⼊数据成功

- 在7003可以获取数据,如果写入数据又重定向到7000(负载均衡)

在哪个服务器上写数据:CRC16
- redis cluster在设计的时候,就考虑到了去中⼼化,去中间件,也就是说,集群中 的每个节点都是平等的关系,都是对等的,每个节点都保存各⾃的数据和整个集 群的状态。每个节点都和其他所有节点连接,⽽且这些连接保持活跃,这样就保 证了我们只需要连接集群中的任意⼀个节点,就可以获取到其他节点的数据
- Redis集群没有并使⽤传统的⼀致性哈希来分配数据,⽽是采⽤另外⼀种叫做哈希 槽 (hash slot)的⽅式来分配的。redis cluster 默认分配了 16384 个slot,当我们 set⼀个key 时,会⽤CRC16算法来取模得到所属的slot,然后将这个key 分到哈 希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的 时候看到set 和 get 的时候,直接跳转到了7000端⼝的节点
- Redis 集群会把数据存在⼀个 master 节点,然后在这个 master 和其对应的salve 之间进⾏数据同步。当读取数据时,也根据⼀致性哈希算法到对应的 master 节 点获取数据。只有当⼀个master 挂掉之后,才会启动⼀个对应的 salve 节点,充 当 master
- 需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存 活的主节点数⼩于总节点数的⼀半时,整个集群就⽆法提供服务了
Linux下配置Redis集群模式的更多相关文章
- linux下配置tomcat集群的负载均衡
linux下配置tomcat集群的负载均衡 一.首先了解下与集群相关的几个概念集群:集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台.在客户端看来,一个集群就象是一个服 ...
- windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error
windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error 学习了:https ...
- centos7下的redis集群模式
1.先安装好单机版的redis 2.Reids安装包里有个集群工具,要复制到/usr/local/bin里去 cd /home/redis/redis-4.0./src ls - cp redis-t ...
- Linux 下配置zookeeper集群
我们首先准备三台服务器,IP地址分别如下(前提是要先安装JDK) 192.168.100.101 192.168.100.102 192.168.100.103 1.配置主机名到IP地址的映射(此步骤 ...
- 在windows下面配置redis集群遇到的一些坑
最近工作不忙,就决定学习一下redis.因为一直在windows下工作,不会linux,没办法就选择在windows下配置redis. windows下配置redis集群的文章有很多,比如:http: ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- Linux配置Redis集群 和 缓存介绍。
// 一.什么是缓存? mybatis一级缓存和二级缓存 mybatis的一级缓存存在哪? SqlSession,就不会再走数据库 什么情况下一级缓存会失效? 当被更新,删除的时候sqlsession ...
- Redis集群模式配置
redis集群部署安装: https://blog.csdn.net/huwh_/article/details/79242625 https://www.cnblogs.com/mafly/p/re ...
- Linux离线安装redis集群
一.应用场景介绍 本文主要是介绍Redis集群在Linux环境下的安装讲解,联网环境安装较为简单,这里只说脱机的Linux环境下是如何安装的.因为大多数时候,公司的生产环境是在内网环境下,无外网,服务 ...
随机推荐
- 【python】Python的安装和配置
Python是一种计算机程序设计语言.是一种动态的.面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的.大型项目的开发. Pyt ...
- 面经 cisco 2
1. cpu中的cache结构及cache一致性 一. 引子 在多线程环境中,经常会有一些计数操作,用来统计线上服务的一些qps.平均延时.error等.为了完成这些统计,可以实现一个多线程环境下的计 ...
- PHP-问题处理Fatal error: Uncaught Error: Call to undefined function simplexml_load_file()
1.问题 今天重新安装了ubuntu,PHP,MySQL,Apache,到测试CMS项目时发生一个错误: Fatal error: Uncaught Error: Call to undefined ...
- vim资源
1.http://vimcasts.org vim技巧,还有一个高达120美元的课程 目前,正在看http://vimcasts.org/blog/2013/02/habit-breaking-hab ...
- 应用间共享文件 FileProvider
应用间共享文件 FileProvider 7.0及以上版本,分析文件给其他进程访问的时候,需要使用FileProvider,否则会出现崩溃: 例如:用系统下载器下载apk,然后通过Intent安装. ...
- 【Spark深入学习 -13】Spark计算引擎剖析
----本节内容------- 1.遗留问题解答 2.Spark核心概念 2.1 RDD及RDD操作 2.2 Transformation和Action 2.3 Spark程序架构 2.4 Spark ...
- js cookie跨域设置
/** * 设置cookie方法 * @param {string} c_name cookie键值 * @param {string} value cookie值 * @param {Boolean ...
- 我的2018:OCR、实习和秋招
真的是光阴似箭,好像昨天还沉浸在考研成功的喜悦,今天却要即将步入2019年,即将硕士毕业.老规矩,还是在每一年的最后一天总结今年以及展望明年.回首2018,经历的东西特别多,视野也开阔了不少,可以说, ...
- git常见用法介绍
1. git help:帮助 git help xxx git xxx --help 2. git init:初始化 git init 3. git config:配置 常见用法 git config ...
- msm audio machine 代码跟踪
sound/soc/msm/msm8952.c // 注册平台设备 static int __init msm8952_machine_init(void) { return platform_dri ...