数据库原理 - 序列7 - Binlog与主从复制
本文节选自作者书籍《软件架构设计:大型网站技术架构与业务架构融合之道》。
作者微信公众号:架构之道与术。公众号底部菜单有书友群可以加入,与作者和其他读者进行深入讨论。也可以在京东、天猫上购买纸质书籍。6.7 Binlog与主从复制
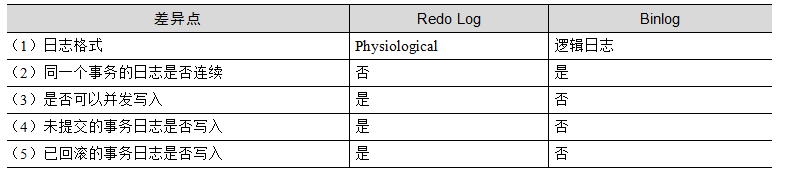
6.7.1 Binlog与Redo Log的主要差异
在MySQL中,Redo Log记录事务执行的日志,Binlog也记录日志,但两者有非常大的差别。首先,MySQL是一个能支持多种存储引擎的数据库,InnoDB只是其中一种(当然,也是最主要的一种)。Redo Log和Undo Log是InnoDB引擎里面的工具,但Binlog是MySQL层面的东西。
不同于Redo Log和Undo Log用来实现事务,Binlog的主要作用是做主从复制,如果是单机版的,没有主从复制,也可以不写Binlog。当然,在互联网应用中,Binlog有了第二个用途:一个应用进程把自己伪装成Slave,监听Master的Binlog,然后把数据库的变更以消息的形式抛出来,业务系统可以消费消息,执行对应的业务逻辑操作,比如更新缓存。大型互联网公司都有这方面的中间件,比如阿里开源的Canal,国外也有几种开源的,比如Databus。
同Redo Log一样,Binlog也存在一个刷盘策略问题,由参数sync_binlog控制,该参数有三个取值:
0:事务提交之后不主动刷盘,依靠操作系统自身的刷盘机制可能会丢失数据。
1:每提交一个事务,刷一次磁盘。
n: 每提交n个事务,刷一次磁盘。
显然,0和n都不安全。为了不丢失数据,一般都建议双1保证,即sync_binlog和innodb_flush_log_at_trx_commit的值都取为1。
知道Binlog的概况后,下面对Binlog 和Redo Log做一个详细的对比,如表6-17 所示。
表6-17 Binlog与Redo Log的详细对比
从表中可以看出,Binlog要比Redo Log简单得多,在不发生宕机的情况下,未提交的事务、回滚的事务,其日志都不会进入Binlog(对于Binlog写到一半时宕机的场景,下面再讨论)。
同时,事务的日志在Binlog中是连续排列的,等到事务提交的“一刹那”,把该事务的所有日志都写盘。连续排列会造成一个问题:Binlog全局只有一份,每个事务都要串行地写入,这意味着每个事务在写Binlog之前要拿一把全局的锁,才能保证每个事务的Binlog是连续写入的,这在效率上存在很大问题。因此,在MySQL 5.6的Group Commit出现之前,各种第三方在优化这类问题。Group Commit的思想也很简单,就是pipeline(HTTP 1.1是同样的思路;Kafka的主从复制也是同样的思路,后面讲高并发时,还会再专门讨论该问题)。虽然Binlog只能串行地写入,但不需要提交一个事务刷一次磁盘,而是把事务的提交和刷盘放到不同的线程里,刷盘时可以对多个提交的事务同时刷盘,虽然还是串行,但是批量化了。
6.7.2 内部XA – Binlog与Redo Log一致性问题
一个事务的提交既要写Binlog,也要写Redo Log,如何保证两份日志数据的原子性?一个写成功,写另外一个的时候发生宕机,重启如何处理?
在讨论这个问题之前,先说一下Binlog自身写入的原子性问题:Binlog刷盘到一半,出现宕机。这个问题和前面讲Redo Log的写入原子性是同样的问题,通过类似于Checksum的办法或者Binlog中有结束标记,来判断出这是部分的、不完整的Binlog,把最后一段截掉。对于客户端来说,此时宕机,事务肯定是没有成功提交的,所以截掉也没有问题。
下面来讲如何实现Binlog和Redo Log的数据一致性,即内部XA,或者叫内部的分布式事务问题。外部分布式事务是两个系统或者两个数据库之间的,这点在后面的事务一致性中会专门论述;内部分布式事务是Binlog和Redo Log之间的事务,使用的是经典的2阶段提交方案(2PC,2 Phase Commit)。
图6-19展示了一个事务的2阶段提交过程,下面详细分析整个提交过程。
阶段1:InnoDB的Prepare,是在把事务提交之前,对应的Redo Log和Undo Log全部都写入了。Binlog也已经写入到内存,只等刷盘。
图6-19 内部XA(事务的2阶段提交过程)
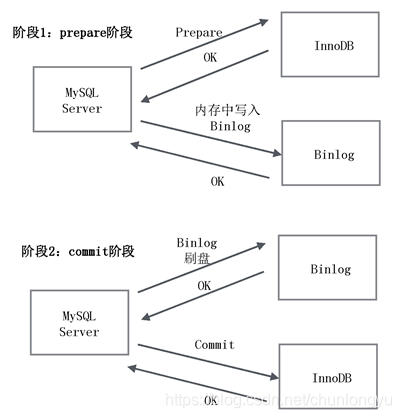
阶段2:收到客户端的Commit指令,先刷盘Binlog,然后让InnoDB执行Commit。
2PC的一个显著特点是,在阶段1就把90%以上的工作全部做完了,就等阶段2的收尾。所以在阶段2收到客户端的Commit指令后,只要不宕机,事务就能成功提交。但如果发生宕机,如何恢复?
首先,整个过程以Binlog的刷盘来判定一个事务是否被成功提交,即以Binlog为准,让Redo Log向Binlog“靠齐”。具体分为下面几种场景:
场景(1):在阶段1宕机,此时Binlog全在内存中,宕机消失。Redo Log记录了未提交的日志。不需要依赖Binlog,Redo Log自己可以回滚未提交的日志。这点前面已介绍过。
场景(2):阶段2宕机,Binlog写了一半,InnoDB Commit还未执行。对Binlog做截断,对Redo log做回滚,处理方法与场景(1)一样。
场景(3):Binlog写入成功,InnoDB未提交。此时遍历Binlog,Binlog中存在、InnoDB中不存在的事务,发起Commit操作。
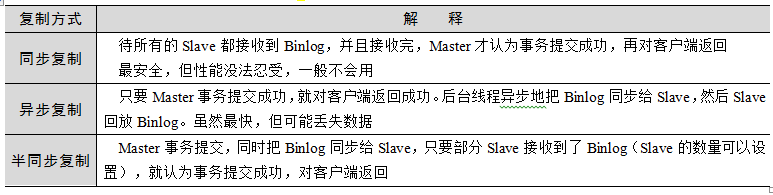
6.7.3 三种主从复制方式
表6-18 列举了MySQL的三种主从复制方式。对于异步复制,可能会丢数据,Master宕机了,切换到Slave,此时Slave上没有最新的数据。所以很多时候大家用的是半同步复制。
不是半同步复制就不会丢数据呢?不是的。半同步复制可能退化为异步复制。因为Master不可能无限期地等Slave,当超过某个时间,Slave还没有回复ACK时,Master就会切换为异步复制模式。
另外,还有一个参数rpl_semi_sync_master_wait_slave_count,可以设置在半同步复制模式下,需要等待几个Slave的ACK,才认为事务提交成功。默认是1,即多个Slave中只要有其中一个返回了,Master就会向客户端返回事务提交成功。
表6-18 MySQL的三种主从复制方式
从上面的介绍可以看出,无论异步复制,还是半异步复制(可能退化为异步复制),都可能在主从切换的时候丢数据。业务一般的做法是牺牲一致性来换取高可用性,即在Master宕机后切换到Slave,忍受少量的数据丢失,后续再人工修复。
但如果主从复制的延迟太大,切换到Slave,丢失数据太多,也难以接受。为了降低主从复制的延迟,业界的前辈们想了很多的办法,这就是下面要讲的并行复制,在跨机房的情况下,尤其必要。
6.7.4 并行复制
图6-20展示了原生的MySQL主从复制的原理,分为两个阶段:
阶段1:把Master中的Binlog搬运到Slave上面,形成RelayLog。在这个搬运过程中,Master和Slave两边各有一个线程,Master上面的叫dump thread,Slave上面的叫I/O thread。
阶段2:Slave把RelayLog回放到数据库,通过一个叫作SQL thread的线程执行。
图6-20 原生的MySQL主从复制的原理
可见,整个复制过程无论Log的传输过程,还是回放过程,都是单线程的。而并行复制,就是把回放环节并行化了,如图6-21所示。

图6-21 并行复制
所谓的并行复制,准确说是并行回放,因为传输环节还是单线程的。之所以传输环节没有用多线程,主要是因为没有必要。一个原因是在回放环节,而不在传输环节;另外一个原因是Binlog本身是全局有序的,如果用多线程传输,还要重新排序和重组,可能得不偿失。
而并行回放的难点在于事务的并行提交。Binlog本身是全局只有一份,同一个MySQL的实例,不同库、不同表的事务Binlog都串行地排列。所谓并行回放,就是一次性从RelayLog中拿出多个事务,并行地执行。这就涉及什么样的事务能并行,什么样的事务不能并行。大的来说,有两类并发策略:
第一类:按数据维度并行。
从粗到细,三个粒度:不同库的事务可以并行,不同表的事务可以并行,不同行的事务可以并行。当然实际没有那么简单,因为一个事务可能修改多个库的多个表的多条记录,以表的粒度为例,事务1修改了记录1、2,事务2修改了记录2、3,则两个事务就无法并行了,但如果事务1修改的是记录1、2,事务2修改的是记录3、4,就可以并行。
第二类:按事务的提交顺序并行。
MySQL中有commit_id的概念,表示哪些事务是同时提交的。什么意思呢?如果在一个事务还没有结束之前,另外一个事务也开始进入提交阶段,说明这两个事务是在并行的,它们操作的是肯定是不同的数据记录。所以,在回放的时候具有同样commit_id的事务可以并行。
当然,两个事务的commit_id不一样,不代表不能并行。commit_id不一样,可能仅仅是因为一个事务是在另外一个事务结束之后才开始的,它们在时间上有先后顺序,但操作的数据完全不同,用第一类并发策略仍然可以并行。
基于commit_id的并行提交策略,在MySQL的版本迭代中也一直在不断优化,这涉及InnoDB的底层实现细节。此处只是介绍一个大概思路,如要深入研究,建议查看InnoDB实现源码。
数据库原理 - 序列7 - Binlog与主从复制的更多相关文章
- 数据库原理 - 序列3 - 事务是如何实现的? - Redo Log解析
6.5 事务实现原理之1:Redo Log 介绍事务怎么用后,下面探讨事务的实现原理.事务有ACID四个核心属性:A:原子性.事务要么不执行,要么完全执行.如果执行到一半,宕机重启,已执行的一半要回滚 ...
- 数据库原理 - 序列5 - 事务是如何实现的? - Undo Log解析
本文节选自作者书籍<软件架构设计:大型网站技术架构与业务架构融合之道>.作者微信公众号:架构之道与术.公众号底部菜单有书友群可以加入,与作者和其他读者进行深入讨论.也可以在京东.天猫上购买 ...
- 数据库原理 - 序列4 - 事务是如何实现的? - Redo Log解析(续)
> 本文节选自<软件架构设计:大型网站技术架构与业务架构融合之道>第6.4章节. 作者微信公众号:> 架构之道与术.进入后,可以加入书友群,与作者和其他读者进行深入讨论.也可以 ...
- JAVA-Unit01: 数据库原理 、 SQL(DDL、DML)
Unit01: 数据库原理 . SQL(DDL.DML) SQL语句是不区分大小写的,但是行业里习惯将关键字与分关键字用大小写岔开以提高可读性. SELECT SYSDATE FROM dual DD ...
- 【转】MySQL数据库原理
原文地址:http://www.cnblogs.com/qiuyi116/p/4349233.html 我们知道,数据是信息的载体——一种我们约定了如何解释的符号.在计算机系统中,最常见的应该是文本数 ...
- MySQL数据库原理
我们知道,数据是信息的载体——一种我们约定了如何解释的符号.在计算机系统中,最常见的应该是文本数据.我们用它记录配置信息,写日志,等等.而在应用程序中,按一定的数据结构来组织数据的方式叫做数据库管理系 ...
- Oracle数据库之序列
Oracle数据库之序列(sequence) 序列是一个计数器,它并不会与特定的表关联.我们可以通过创建Oracle序列和触发器实现表的主键自增.序列的用途一般用来填充主键和计数. 一.创建序列 语法 ...
- Oracle数据库中序列(SEQUENCE)的用法详解
Oracle数据库中序列(SEQUENCE)的用法详解 在Oracle数据库中,序列的用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值.本文我们主要介绍了 ...
- 数据库原理剖析 - 序列1 - B+树
本文节选自<软件架构设计:大型网站技术架构与业务架构融合之道>第6.3章节. 作者微信公众号: 架构之道与术.进入后,可以加入书友群,与作者和其他读者进行深入讨论.也可以在京东.天猫上购买 ...
随机推荐
- .NET(C#、VB)APP开发——Smobiler平台控件介绍:SignatureButton控件
SignatureButton控件 一. 样式一 我们要实现上图中的效果,需要如下的操作: 从工具栏上的"Smobiler Components"拖动一个Sign ...
- 设计模式 | 策略模式(strategy)
参考:https://www.cnblogs.com/lewis0077/p/5133812.html(深入解析策略模式) 定义: 策略模式定义了一系列的算法,并将每一个算法封装起来,使每个算法可以相 ...
- ArcGIS JS 3.x使用webgl绘制热力图
ArcGIS Js Api 3.x 热力图在数据量达到三万左右的时候,绘制速度不尽人意,数据量再大些,缩放时候就会很卡,非常影响客户体验. 参考了一下网上webgl热力图,能达到更流畅 ...
- PowerDesigner如何连接数据库--odbc连接数据库用法
先下载msi https://dev.mysql.com/downloads/connector/odbc/ 注:如果不成功,有可能msi版本问题,可以更换一下msi 前期准备 双击odbc的ms ...
- Android进阶之光-第1章-Android新特性-读书笔记
第 1 章 Android 新特性 1.1 Android 5.0 新特性 1.1.1 Android 5.0 主要新特性 1. 全新的 Material Design 新风格 Material De ...
- 理解ASP.NET Core验证模型(Claim, ClaimsIdentity, ClaimsPrincipal)不得不读的英文博文
这篇英文博文是 Andrew Lock 写的 Introduction to Authentication with ASP.NET Core . 以下是简单的阅读笔记: -------------- ...
- mybatis自动填充时间字段
对于实体中的created_on和updated_on来说,它没有必要被开发人员去干预,因为它已经足够说明使用场景了,即在插入数据和更新数据时,记录当前时间,这对于mybatis来说,通过拦截器是可以 ...
- matlab常用目录操作
总结matlab下常用到的目录操作 添加当前文件夹及其子文件夹至搜索路径 % add path rootDir = fileparts(mfilename('fullpath')); addpath( ...
- C++求集合的交集差集
标准库的<algorithm>头文件中提供了std::set_difference,std::set_intersection和std::set_union用来求两个集合的差集,交集和并集 ...
- Docker进阶之七:管理应用程序数据
管理应用程序数据:Volume Docker提供三种不同的方式将数据从宿主机挂载到容器中:volumes,bind mounts和tmpfs. volumes:Docker管理宿主机文件系统的一部分( ...