hbase 预分区与自动分区
我们知道,HBASE在创建表的时候,会自动为表分配一个Region,
当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以此类推。
表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
所以,HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
假设我们初始给它10个Region,那么导入大量数据的时候,就会均衡到10个里面,显然比1个Region要好很多。
可是我们应该创建多少个Region呢?显然没有具体答案,要结合业务,根据表的rowkey进行设计。
一.强制拆分
预分区方法:
1.hbase shell 预分区
建立分区前,要先了解表的rowkey格式,rowkey为:两位随机数+时间戳+客户id
两位随机数的范围从00-99,划分范围:小于10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,90+
hbase(main):001:0> create 'log1', 'cf1', SPLITS => ['10','20','30','40','50','60','70','80','90']
启动webUI
vi hbase-site.xml
添加
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
浏览器中:
http://h201:60010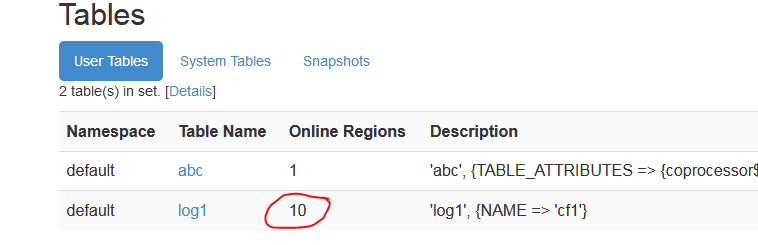
通过配置文件加载
[hadoop@h201 ~]$ cat rs.txt
10
20
30
40
50
60
70
80
90
hbase(main):003:0> create 'log2', 'cf1', SPLITS_FILE =>'/home/hadoop/rs.txt'
2.HBASE API 预分区
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.util.Bytes; public class Cp {
public static void main(String[] args) {
HBaseConfiguration config = new HBaseConfiguration();
config.set("hbase.zookeeper.quorum", "h201,h202,h203");
String tablename = new String("ctest1");
try{
HBaseAdmin admin = new HBaseAdmin(config);
if (admin.tableExists(tablename)) {
admin.disableTable(tablename);
admin.deleteTable(tablename);
} HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor("cf1")); byte[][] splitKeys = {
Bytes.toBytes("10"),
Bytes.toBytes("20"),
Bytes.toBytes("30")
}; admin.createTable(tableDesc, splitKeys);
admin.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
验证:
webUI查看
ctest1有4个 预分区
====================================================
二.自动拆分(Auto splitting)
1.
0.94 版本之前采用的是 ConstantSizeRegionSplitPolicy 策略。
这个策略非常简单,从名字上就可以看出这个策 略就是按照固定大小来拆分Region。它唯一用到的参数是: hbase.hregion.max.filesize, 默认值是 10G, 也就是当 Region 的大小达到 10G 的时候, 会自动拆分成两个 Region.
2.
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。并且默认使用的这种策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。
这种策略使用的最大store file size依据 Min(R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”),R代表同一台Region Server节点上的region的个数。比如,在默认memstore flush size为128MB且默认的max store size为10G时。(R为region的个数)
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
可以看到,只有在第四次之后的拆分大小才为10G
hbase 预分区与自动分区的更多相关文章
- Hive静态分区和动态分区
一.静态分区 1.创建分区表 hive (default)> create table order_mulit_partition( > order_number string, > ...
- Hbase预分区种子生成
提前生成Hbase预分区种子,在创建Hbase表时也进行相应的预分区,同时设置预分区的个数,预分区的范围对应Hbase监控页面的Region Server的start key与End key,从而使数 ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- storm自定义分组与Hbase预分区结合节省内存消耗
Hbas预分区 在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗. ...
- fedora22切换用户windows分区不能自动挂载
新建立一个用户后,然后登陆后,再次登出,登陆原来的账户windows分区不能自动挂载
- ubuntu server下建立分区表/分区/格式化/自动挂载(转)
link:http://www.thxopen.com/linux/2014/03/30/Linux_parted.html 流程为:新建分区-->格式化分区-->挂载分区 首先弄明白分区 ...
- MySql自动分区
自动分区需要开启MySql中的事件调度器,可以通过如下命令查看是否开启了调度器 show variables like '%scheduler%'; 如果没开启的话通过如下指令开启 ; 1.创建一个分 ...
- 为已有表快速创建自动分区和Long类型like 的方法-Oracle 11G
对上一篇文章进行实际的运用.在工作中遇到有一张大表(五千万条数据),在开始的时候忘记了创建自动分区,导致现在使用非常不方便,查询的速度非常的满,所以就准备重新的分区表,最原始方法是先创建新的分区表,然 ...
- Oracle12c:创建主分区、子分区,实现自动分区插入效果
单表自动单个分区字段使用方式,请参考:<Oracle12c:自动分区表> 两个分区字段时,必须一个主分区字段和一个子分区字段构成(以下代码测试是在oracle12.1版本): create ...
随机推荐
- ifrem上传文件后显示
ifrem上传文件后显示 1.上传文件按钮 <a class="btn btn-primary pull-right" id="data-upload&quo ...
- sun.misc jar包
一直以来Base64算法的加密解密都是使用sun.misc包下的BASE64Encoder及BASE64Decoder来进行的.但是这个类是sun公司的内部方法,并没有在Java API中公开过,不属 ...
- js动态数字时钟
js动态数字时钟 主要用到知识点: 主要是通过数组的一些方法,如:Array.from() Array.reduce() Array.find() 时间的处理和渲染 js用到面向对象的写法 实现的功能 ...
- cesium 之图层管理器篇(附源码下载)
前言 cesium 官网的api文档介绍地址cesium官网api,里面详细的介绍 cesium 各个类的介绍,还有就是在线例子:cesium 官网在线例子,这个也是学习 cesium 的好素材. 内 ...
- SQL Server 检测到基于一致性的逻辑 I/O 错误 pageid 不正确
最近在查询SQL时遇到SQL文件错误,可能是文件数据已损坏.解决过程分享给大家. 问题描述 消息 824,级别 24,状态 2,第 1 行SQL Server 检测到基于一致性的逻辑 I/O 错误 p ...
- 关于.Net mvc 项目在本地vs运行响应时间过长无法访问时,解决方法!
最近可能是刚升级了电脑使用了window10操作系统,总是遇到了一些以前没有遇到过的事情! 今早来到公司本来准备写bug的,但是当我打开vs运行的时候发现今天的电脑响应的时间明显的要比之前打开网页调试 ...
- #Java学习之路——基础阶段(第十一篇)
我的学习阶段是跟着CZBK黑马的双源课程,学习目标以及博客是为了审查自己的学习情况,毕竟看一遍,敲一遍,和自己归纳总结一遍有着很大的区别,在此期间我会参杂Java疯狂讲义(第四版)里面的内容. 前言: ...
- SignalR使用笔记
最近项目要求添加一个给用户发送消息的功能,就决定使用SignalR.翻到了以前学习SignalR的学习笔记,基本是官方文档的简版整理,便于快速阅览和实现. 1. nuget添加signalr引用: a ...
- hibernate出现QueryException: could not resolve property 查询异常
可能是你的属性名写错了, 因为hibernate是面向对象和属性的.
- springcloud之自定义简易消费服务组件
本次和大家分享的是怎么来消费服务,上篇文章讲了使用Feign来消费,本篇来使用rest+ribbon消费服务,并且通过轮询方式来自定义了个简易消费组件,本文分享的宗旨是:自定义消费服务的思路:思路如果 ...