【机器学习】从SVM到SVR
注:最近在工作中,高频率的接触到了SVM模型,而且还有使用SVM模型做回归的情况,即SVR。另外考虑到自己从第一次知道这个模型到现在也差不多两年时间了,从最开始的腾云驾雾到现在有了一点直观的认识,花费了不少时间。因此在这里做个总结,比较一下使用同一个模型做分类和回归之间的差别,也纪念一下与SVM相遇的两周年!这篇总结,不会涉及太多公式,只是希望通过可视化的方法对SVM有一个比较直观的认识。
由于代码比较多,没有放到正文中,所有代码都可以在github中:link
0. 支持向量机(support vector machine, SVM)
原始SVM算法是由弗拉基米尔·万普尼克和亚历克塞·泽范兰杰斯于1963年发明的。1992年,Bernhard E. Boser、Isabelle M. Guyon和弗拉基米尔·万普尼克提出了一种通过将核技巧应用于最大间隔超平面来创建非线性分类器的方法。当前标准的前身(软间隔)由Corinna Cortes和Vapnik于1993年提出,并于1995年发表。
上个世纪90年代,由于人工神经网络(RNN)的衰落,SVM在很长一段时间里都是当时的明星算法。被认为是一种理论优美且非常实用的机器学习算法。
在理论方面,SVM算法涉及到了非常多的概念:间隔(margin)、支持向量(support vector)、核函数(kernel)、对偶(duality)、凸优化等。有些概念理解起来比较困难,例如kernel trick和对偶问题。在应用方法,SVM除了可以当做有监督的分类和回归模型来使用外,还可以用在无监督的聚类及异常检测。相对于现在比较流行的深度学习(适用于解决大规模非线性问题),SVM非常擅长解决复杂的具有中小规模训练集的非线性问题,甚至在特征多于训练样本时也能有非常好的表现(深度学习此时容易过拟合)。但是随着样本量$m$的增加,SVM模型的计算复杂度会呈$m^2$或$m^3$增加。
在下面的例子中,均使用上一篇博客中提到的鸢尾属植物数据集。
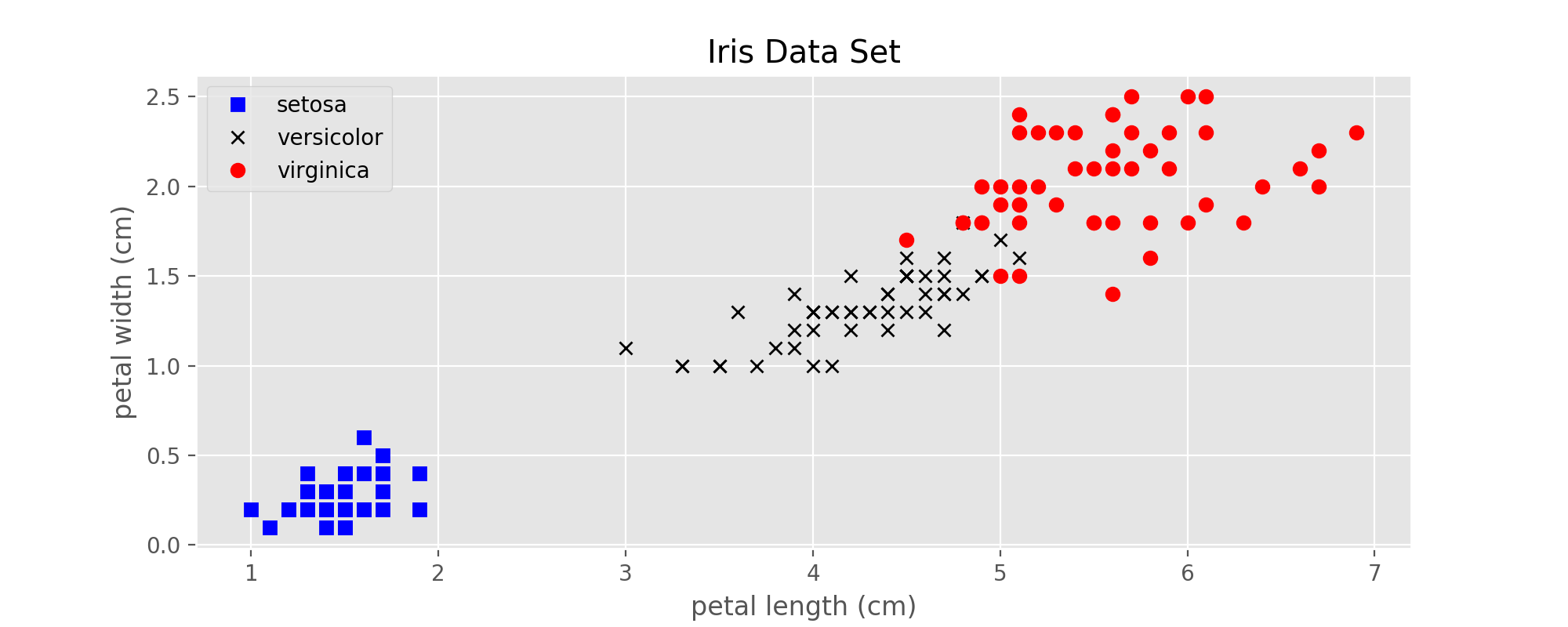
图1:Iris data set
1. SVM的前身:感知机(Perceptron)
感知机可以看做是低配版的线性SVM,从数学上可以证明:
在线性可分的两类数据中,感知机可以在有限步骤中计算出一条直线(或超平面)将这两类完全分开。
如果这两类距离越近,所需的步骤就越多。此时,感知机只保证给出一个解,但是解不唯一,如下图所示:
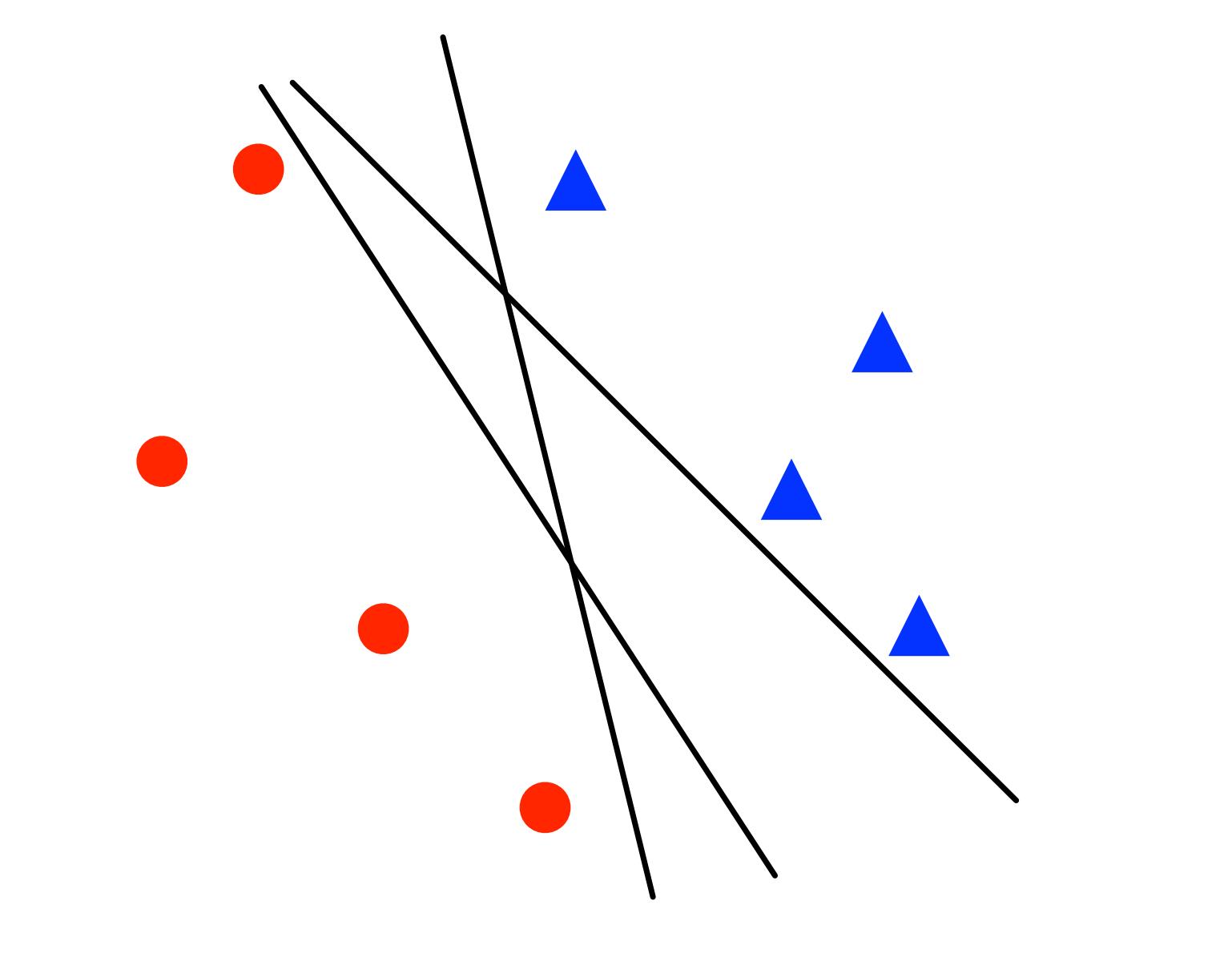
图2:感知机训练出来的3个不同的线性分类器
1.1 对二分类问题的具体描述
训练样本$x \in \mathbb{ R }^{n}$,标签$y \in {-1, 1}$,对于线性分类器来说:
- 参数: $w \in \mathbb{ R }^n$ and $b \in \mathbb{ R }$
- 决策边界(Decision boundary):$w \cdot x + b = 0$
- 对于一个新的点$x$做分类时,预测标签为$sign(w \cdot x + b)$
参考上面的描述,在分类正确的情况下,如果一个点$x$的标签为$y = 1$,预测值$w \cdot x + b > 0$,分类为1;标签为-1,预测值小于0,分类为-1. 那么可以使用$y (w \cdot x + b) > 0 $来统一表示分类正确的情况,反之可以使用$y(w \cdot x + b) < 0$来表示分类错误的情况。
1.2 代价函数
在分类正确时,即$y (w \cdot x + b) > 0$,$loss = 0$;
在分类错误时,即$y (w \cdot x + b) \leq 0$,$loss = -y (w \cdot x + b)$.
1.3 算法的流程
利用随机梯度下降的方式训练模型,每次只使用一个样本,根据代价函数的梯度更新参数,
step1: 初始化$w = 0, b = 0$;
step2: 循环从训练集取样本,每次一个
if $y (w \cdot x + b) \leq 0$(该样本分类错误):
w = w + yx
b = b + y
从流程上来看,每次取出一个样本点训练模型,而且只在分错的情况下更新参数,最终所有样本都分类正确时,模型训练过程结束。
2. SVM - 线性可分
在两类样本线性可分的情况下,感知机可以保证找到一个解,完全正确的区分这两类样本。但是解不唯一,而且这些决策边界的质量也不相同,直观上来看这条线两边的间隔越大越好。那么有没有一种方法可以直接找到这个最优解呢?这就是线性SVM所做的事情。
从直观上来看,约束条件越多对模型的限制也就越大,因此解的个数也就越少。感知机的解不唯一,那么给感知机的代价函数加上更强的约束条件好像就可以减少解的个数。事实上也是这样的。
2.1 SVM的代价函数
在分类正确时,即$y (w \cdot x + b) > 1$,$loss = 0$;
在分类错误时,即$y (w \cdot x + b) \leq 1$,$loss = -y (w \cdot x + b)$.
比较一下可以发现,原来$w \cdot x + b$只需要大于0或小于0就可以了,但是现在需要大于1或小于1. 在这里为什么选择1我还没有很直观的解释,但是有一点非常重要:原来的决策边界只是一条直线,现在则变成了一条有宽度的条带。原来差异非常小的两个点(例如$w \cdot x + b = 0$附近的两个点)就可以被分成不同的两类,但是现在至少要相差$\frac{2}{||w||}$才可以,如下图所示。
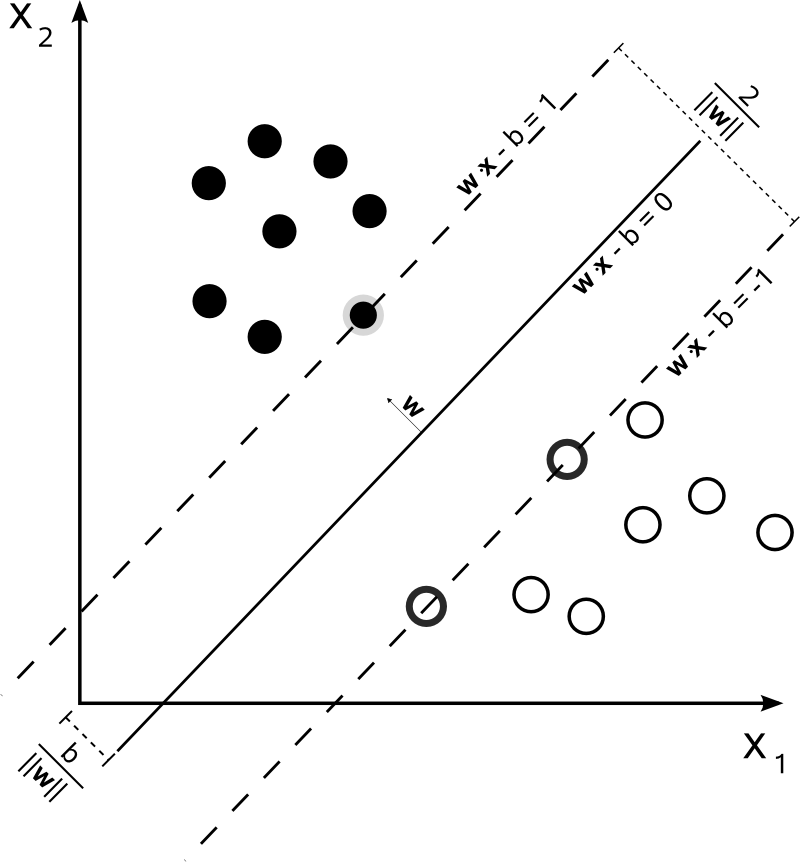
图3:设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在超平面上的样本点也称为支持向量。
2.2 决策边界以及间隔
图3来自wiki,为了统一起见,下面还是将决策边界定义为$w \cdot x + b = 0$,两边的边界(两条虚线)分别为$w \cdot x + b = 1$和$w \cdot x + b = 1$,此时只是b的符号不同其他性质都相同. 其中$w, b$就是模型训练时需要优化的参数。由上面的示意图可以得到以下信息:
- 两条虚线之间的距离为$\frac{2}{||w||}$;
- 待优化参数$w$的方向就是决策边界的法向量方向($w$与决策边界垂直);
- 此时边界上一共有3个点,这三个点也就是此时的支持向量。
下面是计算两条虚线之间距离的过程:
将决策边界的向量表示$w·x + b = 0$展开后可以得到,$w1*x1 + w2*x2 + b = 0$.
转化成截距式可以得到,$x2 = - w1/w2 * x1 - b/w2$,因此其斜率为$-w1/w2$, 截距为$-b/w2$
直线的方向向量为,$(1, -w1/w2)$(可以取x=1, b=0时,得到y的值)
直线的法向量为$w = (w1, w2)$
因此,对于直线$w \cdot x + b = 1$来说,截距式为$x2 = - w1/w2 * x1 + (1 - b)/w2$,相当于沿着$x2$轴向上平移了$\frac{1}{w_2}$,计算可得该直线与$w \cdot x + b = 0$沿法向量方向的距离为$\gamma = \sqrt{\frac{1}{w_1^2 + w_2^2}} = \frac{1}{||w||}$,参考图4.
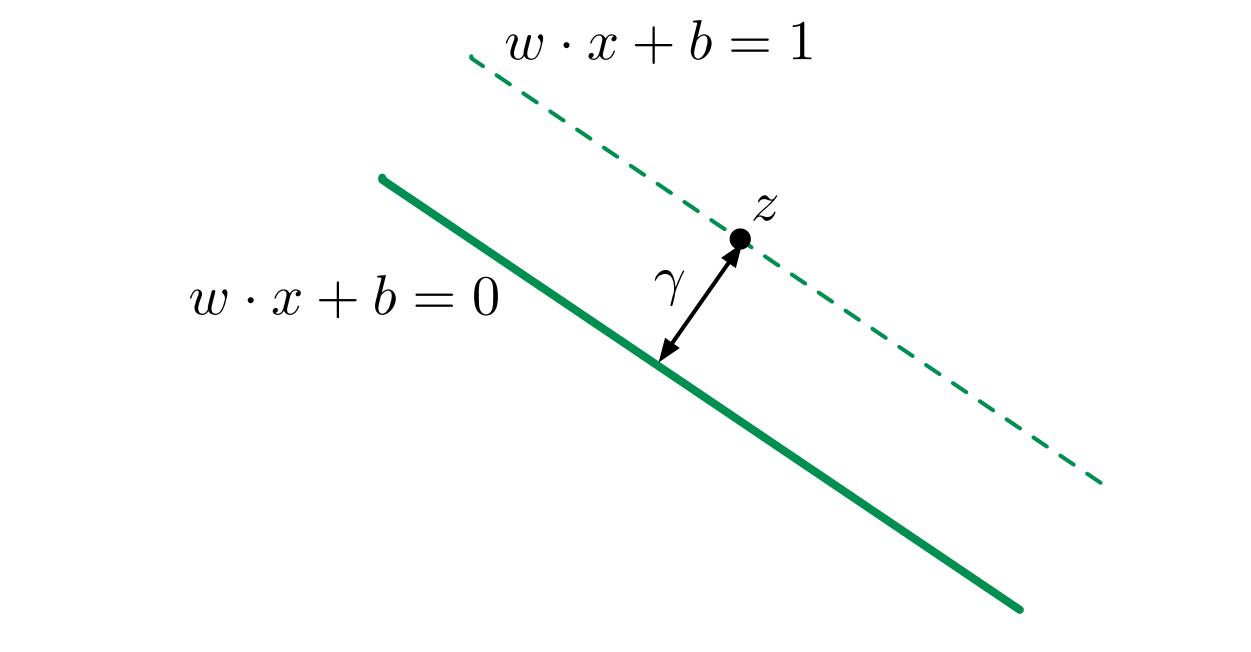
图4:margin的宽度$\gamma$
2.3 优化目标
在SVM中,优化的目标就是最大化margin的宽度$\gamma$,因为$\gamma = \frac{1}{||w||}$,其中$||w||$是待优化参数$w$的模长。因此优化目标等价于最小化$||w||$,可以表示为为:
对于$(x^{(1)}, y^{(1)}), \ ..., \ (x^{(m)}, y^{(m)}) \in \mathbb{R^d} \times \{-1, 1\}$,$\min_{w \in \mathbb{R}^d, b \in \mathbb{R}}||w||^2$
s.t. $y^{(i)}(w \cdot x^{(i)} + b) ≥ 1$对于所有的$i = 1, 2, ..., m$成立
下面是分别使用感知机和SVM对鸢尾属数据集中setosa这一类和非setosa进行分类的效果比较:
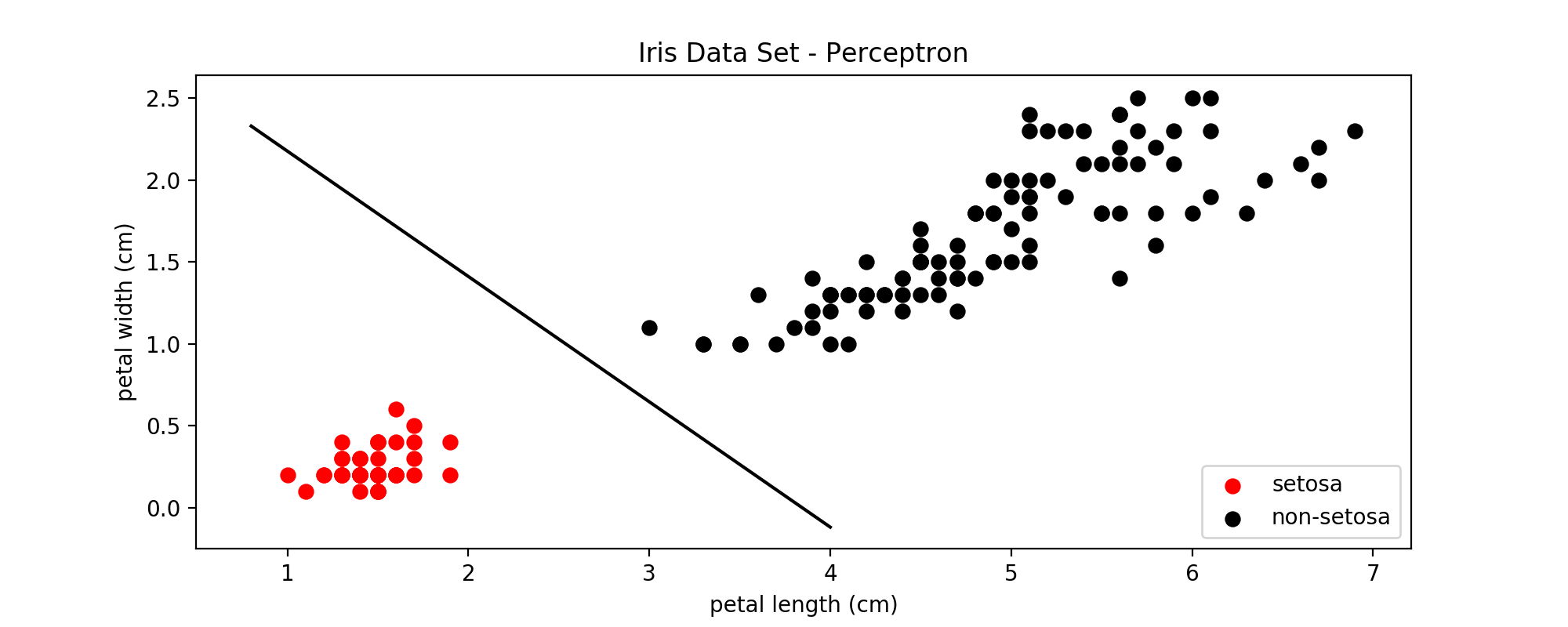
图5:感知机线性分类器
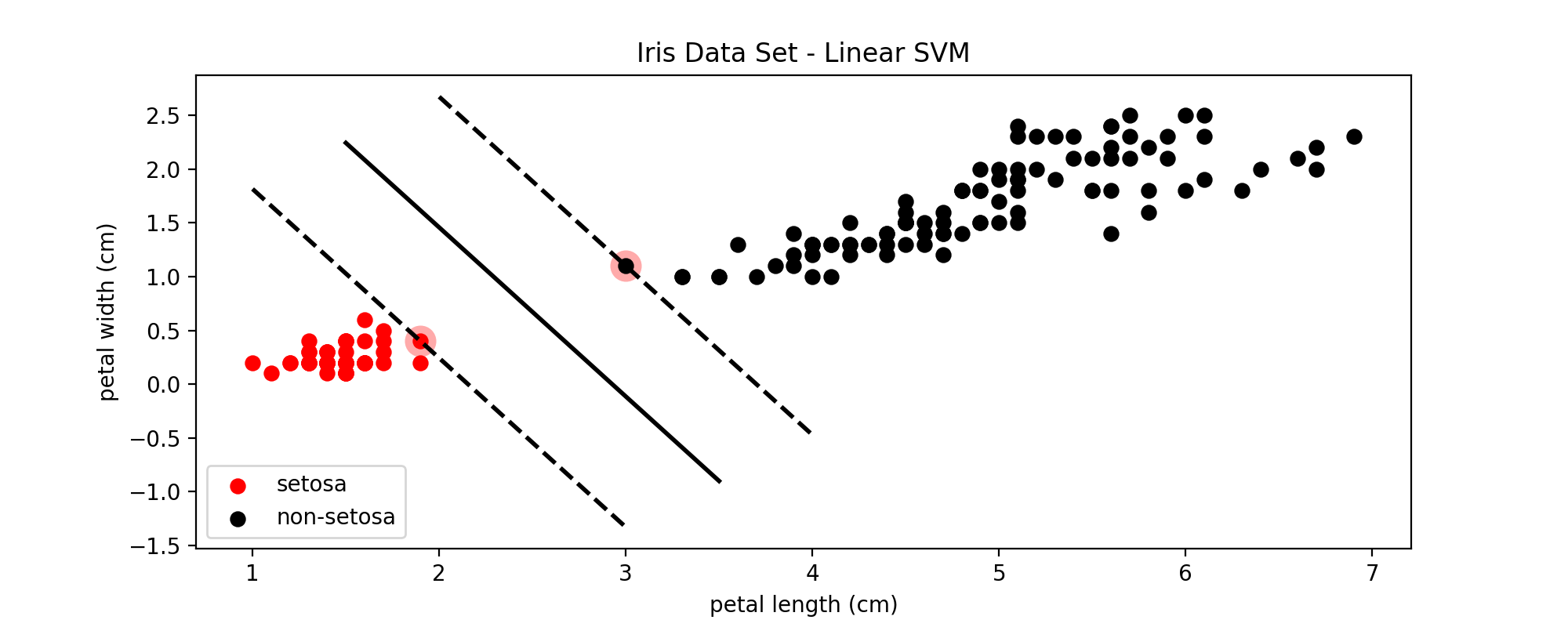
图6:线性SVM的分类效果
比较图5和图6可以看到,SVM确定的决策边界周围的margin更大一些,因此对更多未知的样本进行分类时,在边界上的一些点可以得到更准确的分类结果。
3. SVM - 线性不可分
在图1中可以看到,setosa这一类与其他两类是线性可分的,但是virginica这一类与与之相邻的versicolor有一些点是重合的,也就是说是线性不可分的。此时仍然可以使用SVM来进行分类,原理是在代价函数中加入了一个松弛变量(slack) $\xi$,
对于$(x^{(1)}, y^{(1)}), \ ..., \ (x^{(m)}, y^{(m)}) \in \mathbb{R^d} \times \{-1, 1\}$,$\min_{w \in \mathbb{R}^d, b \in \mathbb{R}}||w||^2 + C\sum_{i=1}^{m}{\xi^i} $
s.t. $y^{(i)}(w \cdot x^{(i)} + b) ≥ 1 - \xi_i$对于所有的$i = 1, 2, ..., m$成立
上面的优化目标加入松弛变量后,就可以允许一定程度的违反两边的边界(由上式中的C来控制),允许一定的错误分类,从而将两类原来线性不可分的两类数据分开。
下面是$C=1000$时,对virginica和非virginica的分类效果:
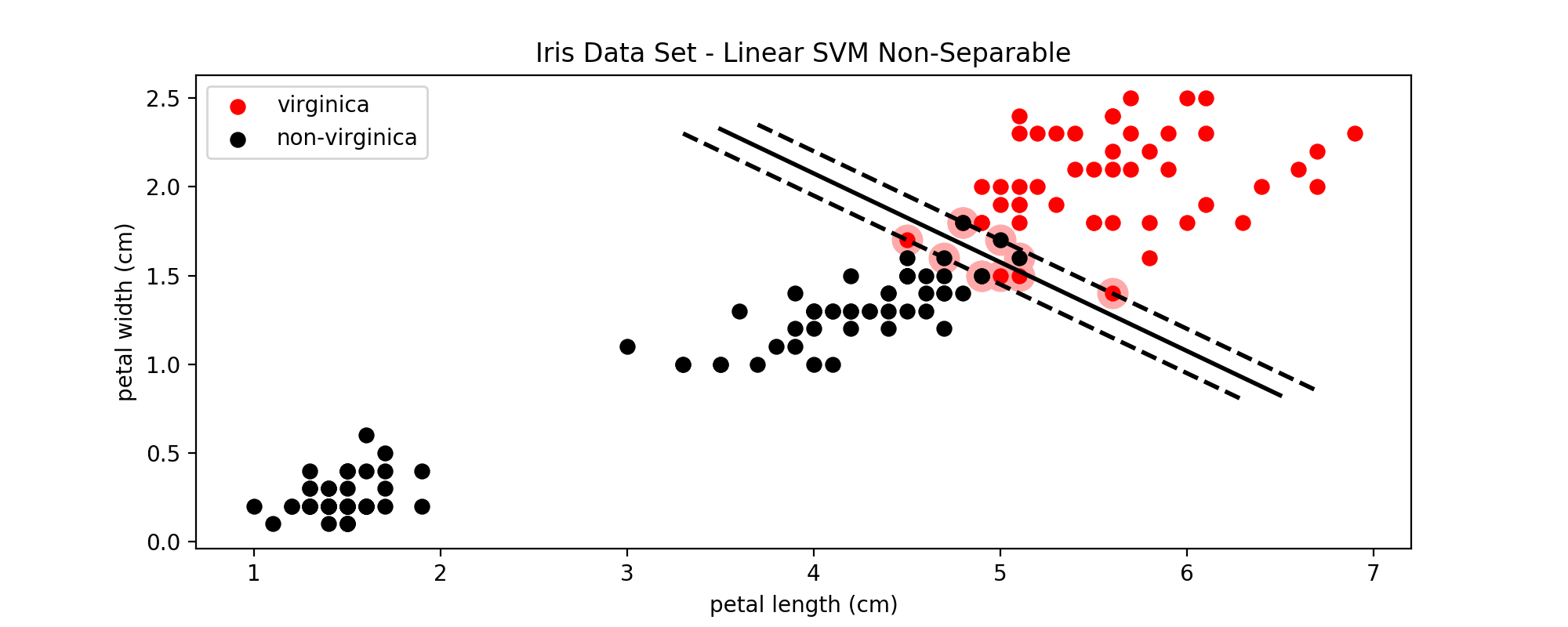
图8:加入松弛变量后的SVM分类效果
C作为SVM模型的超参数之一,需要从一个较大的范围中一步一步的筛选,直到找到最适合的C。C值越大,表示错误分类的代价越大,就越趋于拒绝错误分类,即hard margin;C值越小,表示错误分类的代价越小,就越能容忍错误分类,即soft margin。即使是在线性可分的情况下,如果C设置的非常小,也可能导致错误分类的出现;在线性不可分的情况下,设置过大的C值会导致训练无法收敛。
4. SVR - 利用SVM做回归分析
支持向量回归模型(Support Vector Regression, SVR)是使用SVM来拟合曲线,做回归分析。分类和回归问题是有监督机器学习中最重要的两类任务。与分类的输出是有限个离散的值(例如上面的$\{-1, 1\}$)不同的是,回归模型的输出在一定范围内是连续的。下面不再考虑不同鸢尾花的类型,而是使用花瓣的长度(相当于自变量x)来预测花瓣的宽度(相当于因变量y)。
下图中从所有150个样本中,随机取出了80%作为训练集:
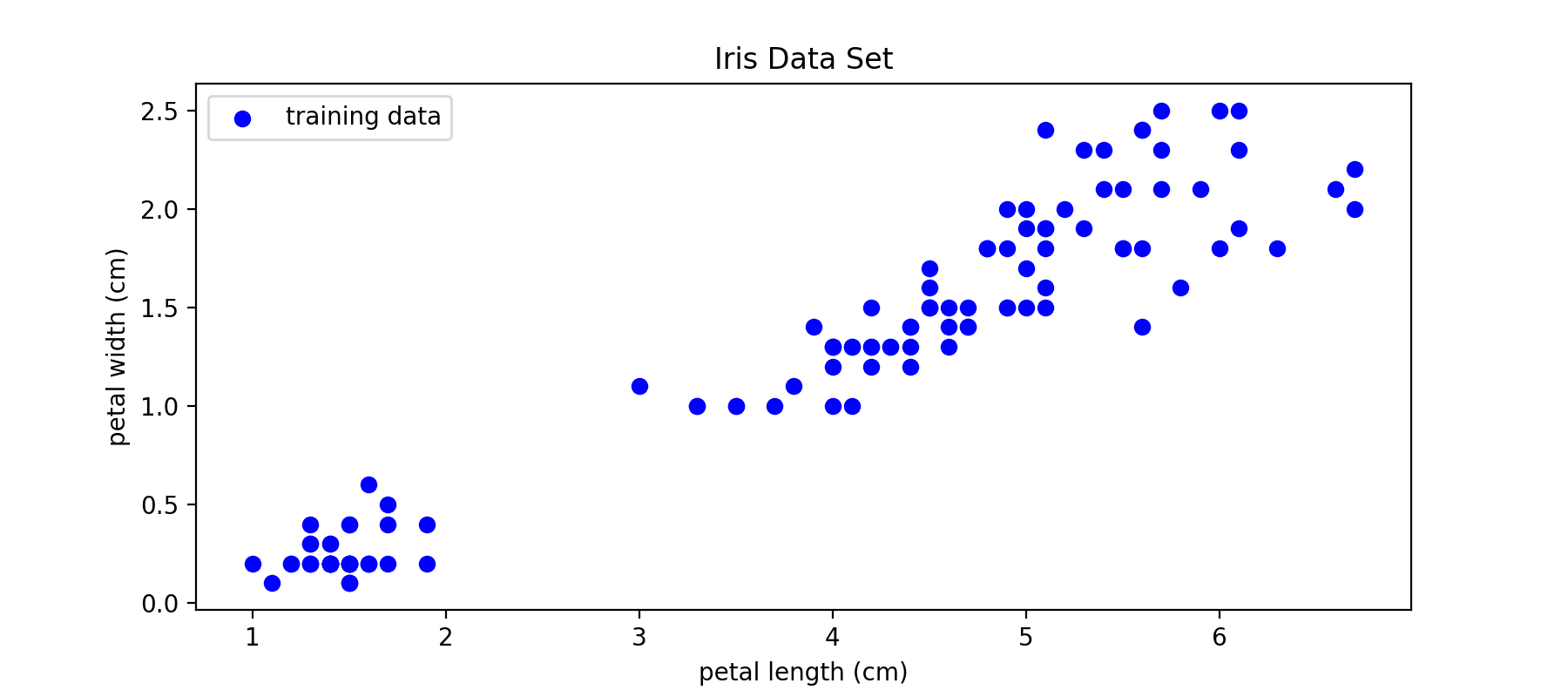
图9:训练SVR模型的训练样本
下面是使用线性SVR训练出来的回归线:
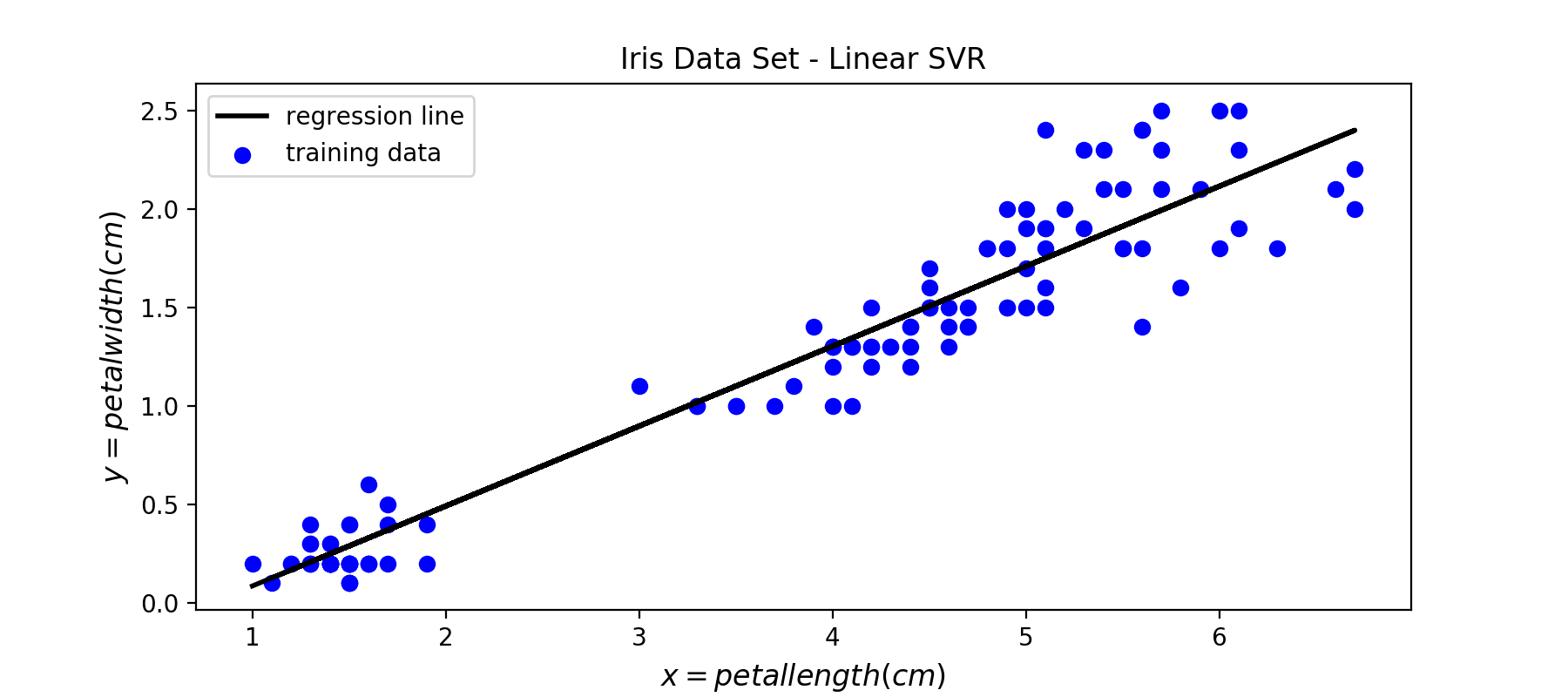
图10:SVR模型训练出来的回归线
与SVM是使用一个条带来进行分类一样,SVR也是使用一个条带来拟合数据。这个条带的宽度可以自己设置,利用参数$epsilon$来控制:
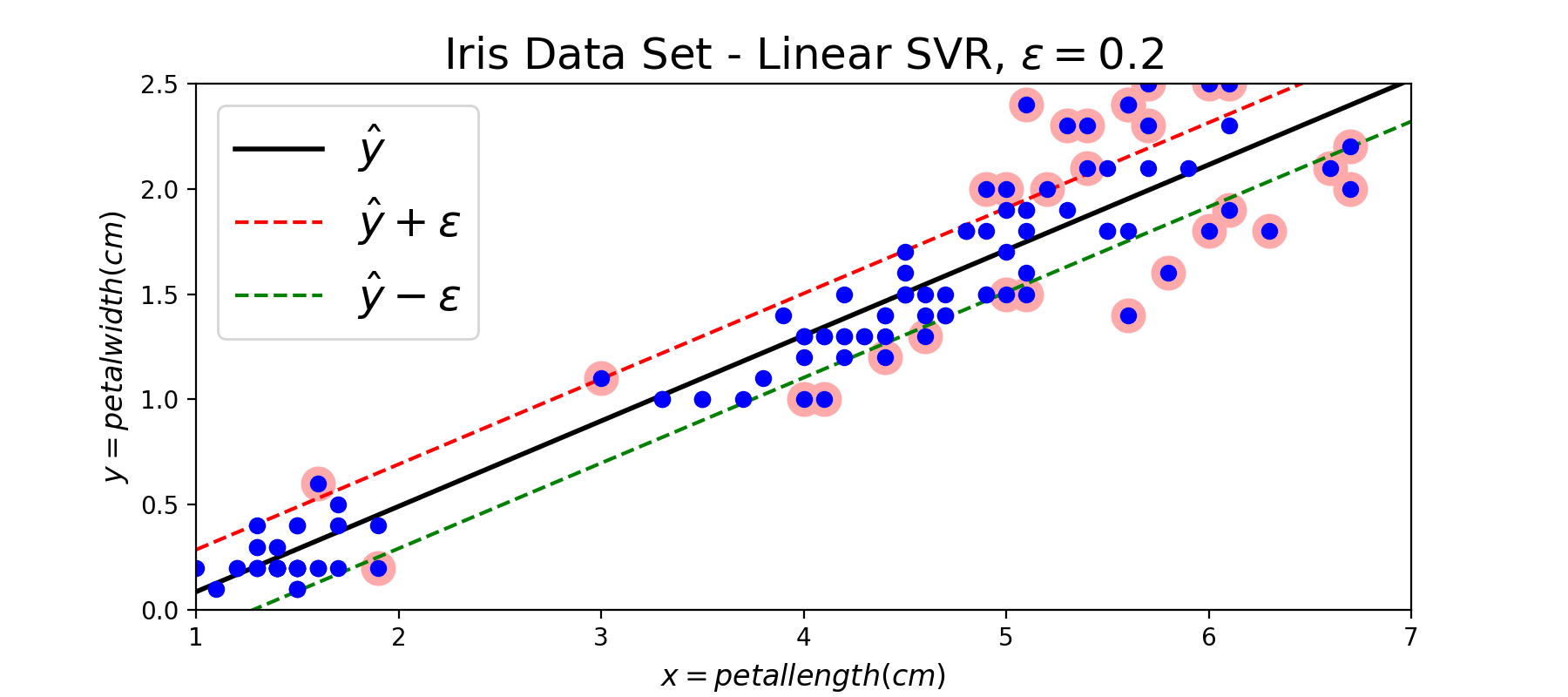
图11:SVR模型回归效果示意图,其中带红色环的点表示支持向量
在SVM模型中边界上的点以及两条边界内部违反margin的点被当做支持向量,并且在后续的预测中起作用;在SVR模型中边界上的点以及两条边界以外的点被当做支持向量,在预测中起作用。按照对偶形式的表示,最终的模型是所有训练样本的线性组合,其他不是支持向量的点的权重为0. 下面补充SVR模型的代价函数的图形:
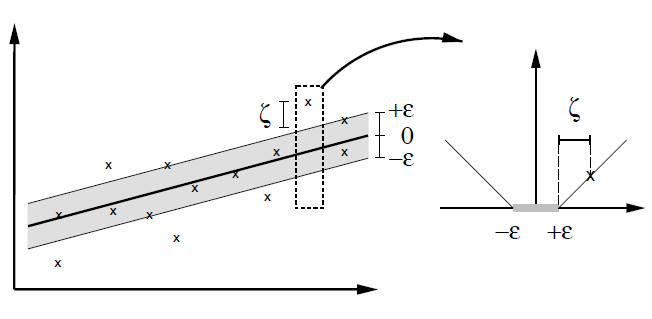
图12:soft margin SVR的代价函数
从图12中可以看到,在margin内部的这些点的error都为0,只有超出了margin的点才回计算error。因此SVR的任务就是找到一条尽可能窄的条带覆盖所有的样本点。
Reference
https://zh.wikipedia.org/wiki/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA
https://zhuanlan.zhihu.com/p/26263309, 直线方程的各种形式
https://github.com/ageron/handson-ml/blob/master/05_support_vector_machines.ipynb
http://www.svms.org/regression/SmSc98.pdf
http://www.robots.ox.ac.uk/~az/lectures/ml/
edx: UCSanDiegoX - DSE220x Machine Learning Fundamentals
https://github.com/OnlyBelter/jupyter-note/blob/master/machine_learning/SVM/04_how%20SVM%20becomes%20to%20SVR.ipynb, 文中代码
【机器学习】从SVM到SVR的更多相关文章
- 机器学习算法--svm实战
1.不平衡数据分类问题 对于非平衡级分类超平面,使用不平衡SVC找出最优分类超平面,基本的思想是,我们先找到一个普通的分类超平面,自动进行校正,求出最优的分类超平面 测试代码如下: import nu ...
- 转:SVM与SVR支持向量机原理学习与思考(一)
SVM与SVR支持向量机原理学习与思考(一) 转:http://tonysh-thu.blogspot.com/2009/07/svmsvr.html 弱弱的看了看老掉牙的支持向量机(Support ...
- 机器学习:SVM(SVM 思想解决回归问题)
一.SVM 思想在解决回归问题上的体现 回归问题的本质:找到一条直线或者曲线,最大程度的拟合数据点: 怎么定义拟合,是不同回归算法的关键差异: 线性回归定义拟合方式:让所有数据点到直线的 MSE 的值 ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
- 【机器学习】svm
机器学习算法--SVM 目录 机器学习算法--SVM 1. 背景 2. SVM推导 2.1 几何间隔和函数间隔 2.2 SVM原问题 2.3 SVM对偶问题 2.4 SMO算法 2.4.1 更新公式 ...
- [matlab]机器学习及SVM工具箱学习笔记
机器学习与神经网络的关系: 机器学习是目的,神经网络是算法.神经网络是实现机器学习的一种方法,平行于SVM. 常用的两种工具:svm tool.libsvm SVM分为SVC和SVR,svc是专门用来 ...
- 机器学习:SVM
SVM 前言:支持向量机(Support Vector Machine, SVM),作为最富盛名的机器学习算法之一,其本身是一个二元分类算法,为了更好的了解SVM,首先需要一些前提知识,例如:梯度下降 ...
- 机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析
SVM有很多实现,现在只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使用一种核函数(kernel)的方式将SVM ...
- coursera机器学习-支持向量机SVM
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
随机推荐
- Docker Win 10 安装
最近了解了一下Docker,不看不知道,一了解就完全被它给吸引住了.以往要装个环境,除了要准备一个Linux系统,然后在安装各种版本的类库,再安装我们需要各种应用服务(如Redis,Ngix,Mong ...
- @Select注解的情况下,重载的报错
在编写代码的时候,我对查询这个方法进行了重载,这样调用的时候会根据参数的不同,进而去执行不同的操作,但是......问题来了.想法都是美好的,实际情况却不是我理想的状态.运行代码的时候他动了几下,然后 ...
- 如何把百度统计代码放入JS文件中?百度统计的JS脚本原理分析
<script> var _hmt = _hmt || []; (function() { var hm = document.createElement("script&quo ...
- TCP/IP学习笔记:TCP传输控制协议(一)
1 TCP的服务 尽管TCP和UDP都使用相同的网络层(IP),TCP却向用户提供一种面向连接的,可靠地字节流服务.两个使用TCP的应用,在彼此交换数据之前必须先建立一个TCP连接,在一个TCP连接中 ...
- C# GetValueList 获得字符串中开始和结束字符串中间得值列表
/// <summary> /// 获得字符串中开始和结束字符串中间得值列表 /// </summary> /// <param name="styleCont ...
- ognl版本错误
错误信息: 2014-2-6 21:20:10 org.apache.catalina.core.StandardWrapperValve invoke严重: Servlet.service() fo ...
- 使用U盘安装 OS X 的坑
以前在电脑上将 OS X 降回Yosemite旧版本时,使用U盘进行安装时会出现 :"这个 OS X Yosemite"应用程序副本不能验证.它在下载过程中可能已遭破坏或篡改. 其 ...
- [BZOJ 4919]大根堆
Description 题库链接 给定一棵 \(n\) 个节点的有根树,每个点有一个权值 \(val_i\) .你需要选择尽可能多的节点,使得:对于任意两个点 \(i,j\) ,如果 \(i\) 在树 ...
- [Codeforces 448C]Painting Fence
Description Bizon the Champion isn't just attentive, he also is very hardworking. Bizon the Champion ...
- BZOJ 4260 Codechef REBXOR
Description Input 输入数据的第一行包含一个整数N,表示数组中的元素个数. 第二行包含N个整数A1,A2,…,AN. Output 输出一行包含给定表达式可能的最大值. Sample ...