MongoDB学习(使用分组、聚合和映射-归并)
使用分组、聚合和映射-归并
MongoDB的强大功能之一,是直接在服务器对文档的值进行复杂的操作,而不用先发文档发送到客户端在进行处理。
结果分组
对大型数据集进行查询操作时,通常会根据文档的字段值对其进行分组。这可以在取回文档后通过代码来完成,但在服务器端查找的同时进行分组效率跟高。
要将查询结果分组,可使用Collection对象的方法 group()。该语法为:
db.collection_name.group({key, reduce, initial, [keyf], [cond], finalize})
参数列表:
- key:指定要根据哪些健进行分组。其属性为要用于分组的字段,值为 1。
- reduce:一个接受参数 obj 和 prev 的函数( function(obj,prev))。对于每个与查询匹配的文档,都执行这个参数。其中参数 obj 为当前文档,而 prev 是根据参数 initial 创建的对象。(可以通过obj来更新prev,如计数或累计)。
- initial:可以创建一个group分组字段,并包含初始值,用于在分组期间聚合数据。(常见的是使用一个计数器来跟踪匹配的文档数。{ initial : {"count" : 0 } } )。
- keyf:可选。指定一个函数,这个函数返回一个用于分组的key对象,用于替代参key。这样可以使用函数动态地指定根据哪些字段分组。
- cond:可选。查找条件,表示从哪些结果集中进行分组。
- finalize:可选。在reduce执行之后,结果集返回之前,对结果集进行的最终操作。可以精简数据。
示例:
数据集:

执行分组命令:
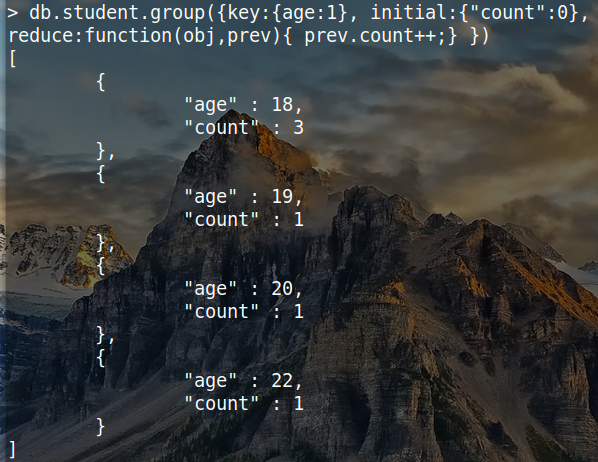
db.student.group({
key:{age:1},
initial:{"count":0},
reduce:function(obj,prev) {
prev.count++;
}
})
MongoDB聚合
理解 aggregate() 方法
Collection对象提供了对数据执行聚合操作的方法 aggregate()。该方法主要用于数据处理(诸如统计平均值,求和等),并返回计算的结果。
db.collection_name.aggregate( operator, [ operator ,...] )
参数 operator 是一系列聚合运算符,让您指定要在流水线的各个阶段对数据执行哪种聚合操作。执行的一个运算符后,将结果传给下一个运算符继续运算。
该方法直接返回一个包含聚合结果的迭代器。

使用聚合框架运算符
MongoDB提供的聚合框架非常强大,通过 aggrgate() 方法可以反复将一个聚合运算符的结果传递给下一个运算符。
注意在引用文档中的字段名时,需要在字段名前加 $ ,表示这是一个字段值而不是字符串。
| 运算符 | 描述 | 示例 |
| $project | 通过重命名、添加或删除字段来重新定义文档。还能重新计算值以及添加子文档 | { $project : { title : " $name " } } |
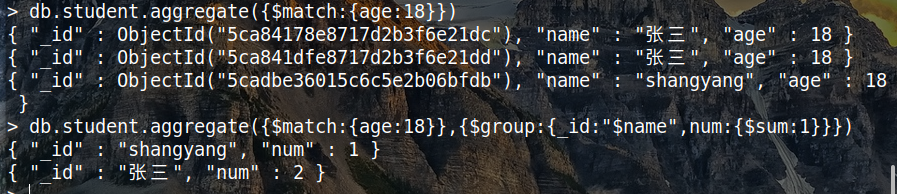
| $match | 可以实现查找的功能 | { $match : { value : { $gt : 50 } } } |
| $limit | 限制文档数,返回结果集中的前 n 个数 | { $limit : 5 } |
| $skip | 丢弃结果集中的前 n 个文档,效率较低,依然会遍历前 n 个文档 | { $skip : 5 } |
| $unwind | 其值必须是数组字段的名称。对指定的数组进行分拆,为其中的每个值创建一个文档 | { $unwind : { $myArr } } |
| $group | 将文档分组并生成新的文档,可以进行一系列子命令 | { $group : { _id : " $name " , num : { $sum : 1 } } } |
| $sort | 将文档排序 | { $sort : { name : 1 , age : -1 } } |
MapReduce() 方法
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
db.collection_name.mapReduce( map , reduce , arguments );
其中 map 是一个函数,用于分组,它将对数据集的每个对象执行它来生成一个键和值,这些值被加入到与键相关联的数组中,供归并阶段使用。
// map 函数
function() {
emit ( key , value );
}
参数 reudce 也是一个函数,将对 map 函数生成的每个对象执行它。reduce 函数必须将键作为第一个参数,将与键相关联的值数组作为第二个参数,并使用值数组来计算得到与键相关联的单个值,再返回结果。
// reduce 函数 处理需要统计的字段
function ( key , value ) {
......统计字段处理
return result;
}
参数 arguments 是一个对象,指定了检索传递给 map 函数的文档时使用的选项。
{
out : collection, // 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query : document, // 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
sort : document, // 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit : number // 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
}
MongoDB学习(使用分组、聚合和映射-归并)的更多相关文章
- MongoDB学习笔记-05 聚合
MongoDB除了基本查询功能之外,还有强大的聚合工具,其中包括:count().distinct().group().mapreduce. 计数函数count count是最简单的聚合工具,用于返回 ...
- mongodb学习之:聚合
@font-face { font-family: "Times New Roman"; }@font-face { font-family: "宋体"; }p ...
- MongoDB学习3:聚合查询
1. 什么是MongoDB聚合框架 1.1 MongoDB聚合框架(Aggregation Frameworn)是一个计算框架,它可以: ● 作用在一个或几个集合上 ● 对集合中的数据 ...
- MongoDB学习--高级查询 [聚合Group]
Group大约需要一下几个参数. key:用来分组文档的字段.和keyf两者必须有一个 keyf:可以接受一个javascript函数.用来动态的确定分组文档的字段.和key两者必须有一个 initi ...
- MongoDB学习总结(三) —— 常用聚合函数
上一篇介绍了MongoDB增删改查命令的基本用法,这一篇来学习一下MongoDB的一些基本聚合函数. 下面我们直奔主题,用简单的实例依次介绍一下. > count() 函数 集合的count函数 ...
- mongoDB 学习笔记纯干货(mongoose、增删改查、聚合、索引、连接、备份与恢复、监控等等)
最后更新时间:2017-07-13 11:10:49 原始文章链接:http://www.lovebxm.com/2017/07/13/mongodb_primer/ MongoDB - 简介 官网: ...
- Dubbo -- 系统学习 笔记 -- 示例 -- 分组聚合
Dubbo -- 系统学习 笔记 -- 目录 示例 想完整的运行起来,请参见:快速启动,这里只列出各种场景的配置方式 分组聚合 按组合并返回结果,比如菜单服务,接口一样,但有多种实现,用group区分 ...
- 【转】mongoDB 学习笔记纯干货(mongoose、增删改查、聚合、索引、连接、备份与恢复、监控等等)
mongoDB 学习笔记纯干货(mongoose.增删改查.聚合.索引.连接.备份与恢复.监控等等) http://www.cnblogs.com/bxm0927/p/7159556.html
- MongoDB学习总结(二)
前言:学习札记! MongoDB学习总结(二) 1. 安装.初识 之前写过一篇MongoDB的快速上手文章,里边详细的讲了如何安装.启动MongoDB,这里就不再累述安装过程,简单介绍一下Mongo ...
随机推荐
- jdk源码阅读笔记-String
本人自学java两年,有幸初入这个行业,所以功力尚浅,本着学习与交流的态度写一些学习随笔,什么错误的地方,热烈地希望园友们提出来,我们共同进步!这是我入园写的第一篇文章,写得可能会很乱. 一.什么是S ...
- asp.net core系列 54 IS4用客户端凭据保护API
一. 概述 本篇开始进入IS4实战学习,从第一个示例开始,该示例是 “使用客户端凭据保护API”,这是使用IdentityServer保护api的最基本场景.该示例涉及到三个项目包括:Identity ...
- 很详细的Django入门详解
Django 是用Python开发的一个免费开源的Web框架,可以用于快速搭建高性能,优雅的网站!采用了MVC的框架模式,即模型M,视图V和控制器C,也可以称为MVT模式,模型M,视图V,模板T.在学 ...
- 『性能』List 和 HashSet 查找性能比较 (任何数据量的检索 从此只用 HashSet )
结论: 总数 50000 (5万): List 检索 5W次 耗时 23秒, HashSet 检索 5W次 耗时 0.01秒. 总数 5000 (5千): List 检索 5K次 耗时 0.16秒 ...
- Python调用ansible API系列(二)执行adhoc和playbook
执行adhoc #!/usr/bin/env python # -*- coding: utf-8 -*- import sys from collections import namedtuple ...
- 微信小游戏爆款秘笈 数据库MongoDB攻略篇
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯云数据库 TencentDB 发表于云+社区专栏 随着微信小游戏的爆发,越来越多开发者关注到MongoDB与小游戏业务的契合度. ...
- Android版数据结构与算法(八):二叉排序树
本文目录 前两篇文章我们学习了一些树的基本概念以及常用操作,本篇我们了解一下二叉树的一种特殊形式:二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree) ...
- spring boot 文件上传大小限制
错误信息 : Spring Boot:The field file exceeds its maximum permitted size of 1048576 bytes. 解决方法一:在启动类添加如 ...
- USB总线标准
1.USB总线类型: OHCI(Open Host Controller Interface)是支持USB1.1的标准,但它不仅仅是针对USB,UHCI(Universal Host Controll ...
- PostgreSql 使用dblink跨库
此篇介绍下psql下dblink的使用方式,帮助自己记录以备后需.dblink是psql下的扩展功能,可以实现在一个数据库中远程操作另外一个数据库,是实现跨库的一种方法.下面步入正文. 安装dblin ...