【python进阶】深入理解系统进程2
前言
在上一篇【python进阶】深入理解系统进程1中,我们讲述了多任务的一些概念,多进程的创建,fork等一些问题,这一节我们继续接着讲述系统进程的一些方法及注意点
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux⽆疑是正确的选择。由于 Windows没有fork调⽤,难道在Windows上⽆法⽤Python编写多进程的程 序?
由于Python是跨平台的,⾃然也应该提供⼀个跨平台的多进程⽀持。 multiprocessing模块就是跨平台版本的多进程模块。
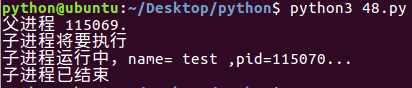
multiprocessing模块提供了⼀个Process类来代表⼀个进程对象,下⾯的例⼦ 演示了启动⼀个⼦进程并等待其结束:
from multiprocessing import Process
import os # 子进程要执行的代码
def run_proc(name):
print('子进程运行中,name= %s ,pid=%d...' % (name, os.getpid())) if __name__=='__main__':
print('父进程 %d.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('子进程将要执行')
p.start()
p.join()
print('子进程已结束')
运行结果:
说明
- 创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
- join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Process语法结构如下:
Process([group [, target [, name [, args [, kwargs]]]]])
target:表示这个进程实例所调用对象;
args:表示调用对象的位置参数元组;
kwargs:表示调用对象的关键字参数字典;
name:为当前进程实例的别名;
group:大多数情况下用不到;
Process类常用方法:
is_alive():判断进程实例是否还在执行;
join([timeout]):是否等待进程实例执行结束,或等待多少秒;
start():启动进程实例(创建子进程);
run():如果没有给定target参数,对这个对象调用start()方法时,就将执行对象中的run()方法;
terminate():不管任务是否完成,立即终止;
Process类常用属性:
name:当前进程实例别名,默认为Process-N,N为从1开始递增的整数;
pid:当前进程实例的PID值;
实例1
from multiprocessing import Process
import os
from time import sleep # 子进程要执行的代码
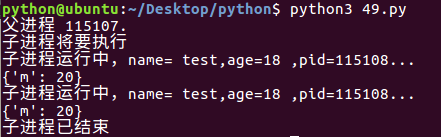
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age,os.getpid()))
print(kwargs)
sleep(0.5) if __name__=='__main__':
print('父进程 %d.' % os.getpid())
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
print('子进程将要执行')
p.start()
sleep(1)
p.terminate()
p.join()
print('子进程已结束')
运行结果:
实例2
from multiprocessing import Process
import time
import os #两个子进程将会调用的两个方法
def worker_1(interval):
print("worker_1,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
t_start = time.time()
time.sleep(interval) #程序将会被挂起interval秒
t_end = time.time()
print("worker_1,执行时间为'%0.2f'秒"%(t_end - t_start)) def worker_2(interval):
print("worker_2,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
t_start = time.time()
time.sleep(interval)
t_end = time.time()
print("worker_2,执行时间为'%0.2f'秒"%(t_end - t_start)) #输出当前程序的ID
print("进程ID:%s"%os.getpid()) #创建两个进程对象,target指向这个进程对象要执行的对象名称,
#args后面的元组中,是要传递给worker_1方法的参数,
#因为worker_1方法就一个interval参数,这里传递一个整数2给它,
#如果不指定name参数,默认的进程对象名称为Process-N,N为一个递增的整数
p1=Process(target=worker_1,args=(2,))
p2=Process(target=worker_2,name="dongGe",args=(1,)) #使用"进程对象名称.start()"来创建并执行一个子进程,
#这两个进程对象在start后,就会分别去执行worker_1和worker_2方法中的内容
p1.start()
p2.start() #同时父进程仍然往下执行,如果p2进程还在执行,将会返回True
print("p2.is_alive=%s"%p2.is_alive()) #输出p1和p2进程的别名和pid
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid) #join括号中不携带参数,表示父进程在这个位置要等待p1进程执行完成后,
#再继续执行下面的语句,一般用于进程间的数据同步,如果不写这一句,
#下面的is_alive判断将会是True,在shell(cmd)里面调用这个程序时
#可以完整的看到这个过程,大家可以尝试着将下面的这条语句改成p1.join(1),
#因为p2需要2秒以上才可能执行完成,父进程等待1秒很可能不能让p1完全执行完成,
#所以下面的print会输出True,即p1仍然在执行
p1.join()
print("p1.is_alive=%s"%p1.is_alive())
执行结果:

进程的创建-Process子类
创建新的进程还能够使用类的方式,可以自定义一个类,继承Process类,每次实例化这个类的时候,就等同于实例化一个进程对象,请看下面的实例:
from multiprocessing import Process
import time
import os #继承Process类
class Process_Class(Process):
#因为Process类本身也有__init__方法,这个子类相当于重写了这个方法,
#但这样就会带来一个问题,我们并没有完全的初始化一个Process类,所以就不能使用从这个类继承的一些方法和属性,
#最好的方法就是将继承类本身传递给Process.__init__方法,完成这些初始化操作
def __init__(self,interval):
Process.__init__(self)
self.interval = interval #重写了Process类的run()方法
def run(self):
print("子进程(%s) 开始执行,父进程为(%s)"%(os.getpid(),os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print("(%s)执行结束,耗时%0.2f秒"%(os.getpid(),t_stop-t_start)) if __name__=="__main__":
t_start = time.time()
print("当前程序进程(%s)"%os.getpid())
p1 = Process_Class(2)
#对一个不包含target属性的Process类执行start()方法,就会运行这个类中的run()方法,所以这里会执行p1.run()
p1.start()
p1.join()
t_stop = time.time()
print("(%s)执行结束,耗时%0.2f"%(os.getpid(),t_stop-t_start))
执行结果:

进程池Pool
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行,请看下面的实例:
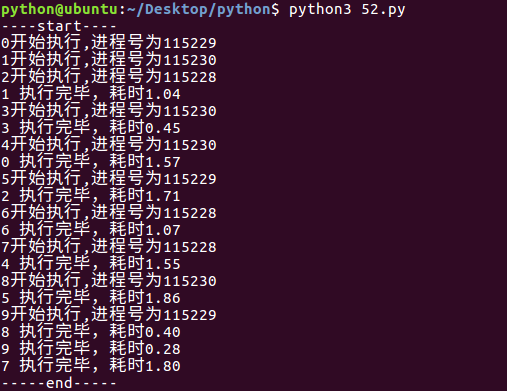
from multiprocessing import Pool
import os,time,random def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d"%(msg,os.getpid()))
#random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f"%(t_stop-t_start)) po=Pool(3) #定义一个进程池,最大进程数3
for i in range(0,10):
#Pool.apply_async(要调用的目标,(传递给目标的参数元祖,))
#每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,)) print("----start----")
po.close() #关闭进程池,关闭后po不再接收新的请求
po.join() #等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
运行结果:
multiprocessing.Pool常用函数解析:
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
apply(func[, args[, kwds]]):使用阻塞方式调用func
close():关闭Pool,使其不再接受新的任务;
terminate():不管任务是否完成,立即终止;
join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
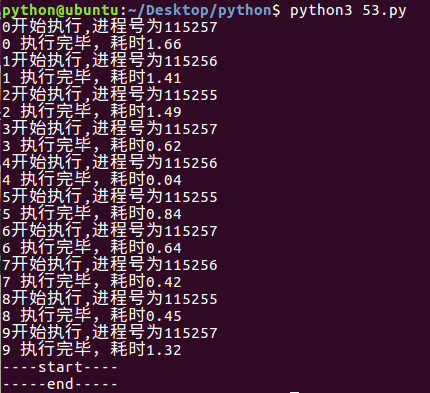
apply堵塞式
from multiprocessing import Pool
import os,time,random def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d"%(msg,os.getpid()))
#random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f"%(t_stop-t_start)) po=Pool(3) #定义一个进程池,最大进程数3
for i in range(0,10):
po.apply(worker,(i,)) print("----start----")
po.close() #关闭进程池,关闭后po不再接收新的请求
po.join() #等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
运行结果:
进程间通信-Queue
Process之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。
1. Queue的使用
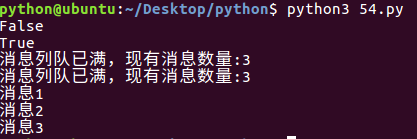
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序,首先用一个小实例来演示一下Queue的工作原理:
from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) #False
q.put("消息3")
print(q.full()) #True #因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常
try:
q.put("消息4",True,2)
except:
print("消息列队已满,现有消息数量:%s"%q.qsize()) try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s"%q.qsize()) #推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4") #读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
运行结果:
说明
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
Queue.qsize():返回当前队列包含的消息数量;
Queue.empty():如果队列为空,返回True,反之False ;
Queue.full():如果队列满了,返回True,反之False;
Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常;
2)如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
Queue.get_nowait():相当Queue.get(False);
Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常;
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
- Queue.put_nowait(item):相当Queue.put(item, False);
2. Queue实例
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
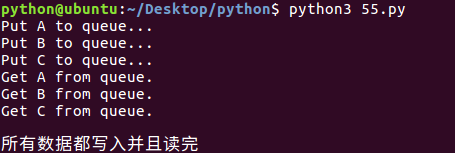
from multiprocessing import Process, Queue
import os, time, random # 写数据进程执行的代码:
def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random()) # 读数据进程执行的代码:
def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
break if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 等待pw结束:
pw.join()
# 启动子进程pr,读取:
pr.start()
pr.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
print('')
print('所有数据都写入并且读完')
运行结果:
3. 进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
#修改import中的Queue为Manager
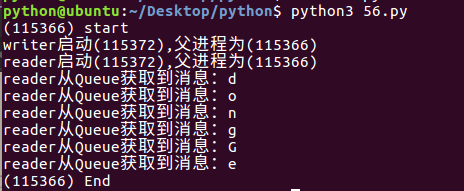
from multiprocessing import Manager,Pool
import os,time,random def reader(q):
print("reader启动(%s),父进程为(%s)"%(os.getpid(),os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s"%q.get(True)) def writer(q):
print("writer启动(%s),父进程为(%s)"%(os.getpid(),os.getppid()))
for i in "dongGe":
q.put(i) if __name__=="__main__":
print("(%s) start"%os.getpid())
q=Manager().Queue() #使用Manager中的Queue来初始化
po=Pool()
#使用阻塞模式创建进程,这样就不需要在reader中使用死循环了,可以让writer完全执行完成后,再用reader去读取
po.apply(writer,(q,))
po.apply(reader,(q,))
po.close()
po.join()
print("(%s) End"%os.getpid())
运行结果:
【python进阶】深入理解系统进程2的更多相关文章
- python 变量进阶(理解)
变量进阶(理解) 目标 变量的引用 可变和不可变类型 局部变量和全局变量 01. 变量的引用 变量 和 数据 都是保存在 内存 中的 在 Python 中 函数 的 参数传递 以及 返回值 都是靠 引 ...
- Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就 ...
- Python进阶:函数式编程实例(附代码)
Python进阶:函数式编程实例(附代码) 上篇文章"几个小例子告诉你, 一行Python代码能干哪些事 -- 知乎专栏"中用到了一些列表解析.生成器.map.filter.lam ...
- Python进阶 - 对象,名字以及绑定
Python进阶 - 对象,名字以及绑定 1.一切皆对象 Python哲学: Python中一切皆对象 1.1 数据模型-对象,值以及类型 对象是Python对数据的抽象.Python程序中所有的数据 ...
- Python进阶 - 命名空间与作用域
Python进阶 - 命名空间与作用域 写在前面 如非特别说明,下文均基于Python3 命名空间与作用于跟名字的绑定相关性很大,可以结合另一篇介绍Python名字.对象及其绑定的文章. 1. 命名空 ...
- 【python进阶】详解元类及其应用2
前言 在上一篇文章[python进阶]详解元类及其应用1中,我们提到了关于元类的一些前置知识,介绍了类对象,动态创建类,使用type创建类,这一节我们将继续接着上文来讲~~~ 5.使⽤type创建带有 ...
- Python进阶:如何将字符串常量转化为变量?
前几天,我们Python猫交流学习群 里的 M 同学提了个问题.这个问题挺有意思,经初次讨论,我们认为它无解. 然而,我认为它很有价值,应该继续思考怎么解决,所以就在私密的知识星球上记录了下来. 万万 ...
- Python进阶:全面解读高级特性之切片!
导读:切片系列文章连续写了三篇,本文是对它们做的汇总.为什么要把序列文章合并呢?在此说明一下,本文绝不是简单地将它们做了合并,主要是修正了一些严重的错误(如自定义序列切片的部分),还对行文结构与章节衔 ...
- Python进阶:迭代器与迭代器切片
2018-12-31 更新声明:切片系列文章本是分三篇写成,现已合并成一篇.合并后,修正了一些严重的错误(如自定义序列切片的部分),还对行文结构与章节衔接做了大量改动.原系列的单篇就不删除了,毕竟也是 ...
随机推荐
- 第一篇、vlc-android之开篇介绍
转载请注明出处:http://blog.csdn.net/cuiran/article/details/30054835 最近一直研究android的视频直播部分,从最开始的直接播放本地视频文件,到使 ...
- 【一天一道LeetCode】#51. N-Queens
一天一道LeetCode系列 (一)题目 The n-queens puzzle is the problem of placing n queens on an n×n chessboard suc ...
- 基于Retrofit2.0+RxJava+Dragger2实现不一样的Android网络构架搭建(转载)
转载请注明出处:http://blog.csdn.net/finddreams/article/details/50849385#0-qzone-1-61707-d020d2d2a4e8d1a374a ...
- 新手自定义view练习实例之(一) 泡泡弹窗
转载请注明出处:http://blog.csdn.net/wingichoy/article/details/50455412 本系列是为新手准备的自定义view练习项目(大牛请无视),相信在学习过程 ...
- 反对网抄,没有规则可以创建目标"install" 靠谱解答
在ubuntu下遇到这个问题,原因其实很简单,你不能用WINDWOS下的方法用图形方式打开,然后点了一下按扭"解压缩",生成了一个文件夹. 的确,这个文件夹看起来和正常的没有什么区 ...
- 【一天一道LeetCode】#40. Combination Sum II
一天一道LeetCode系列 (一)题目 Given a collection of candidate numbers (C) and a target number (T), find all u ...
- Leetcode_202_Happy Number
+ 92 = 82 82 + 22 = 68 62 + 82 = 100 12 + 02 + 02 = 1 思路: (1)题意为判断给定的整数是否为一个"快乐的数",所谓快乐的数需 ...
- 100个Myeclipse6.5免费注册码
下面提供了100个MyEclipse6.5的注册码供大家使用: register name:cghidigfa Serial:pLR8ZC-855550-6359775146444620 ------ ...
- Android adb基本命令-cd,ls,目录相关命令
cd的命令 cd -:代表进入家目录,普通用户是/home/用户名,root用户是/root目录,-是家目录的代表 cd /:这是进入根目录,/是根目录的代表 cd .. :是返回上一级的目录 cd ...
- Leetcode_206_Reverse Linked List
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/45739753 Reverse a singly linke ...