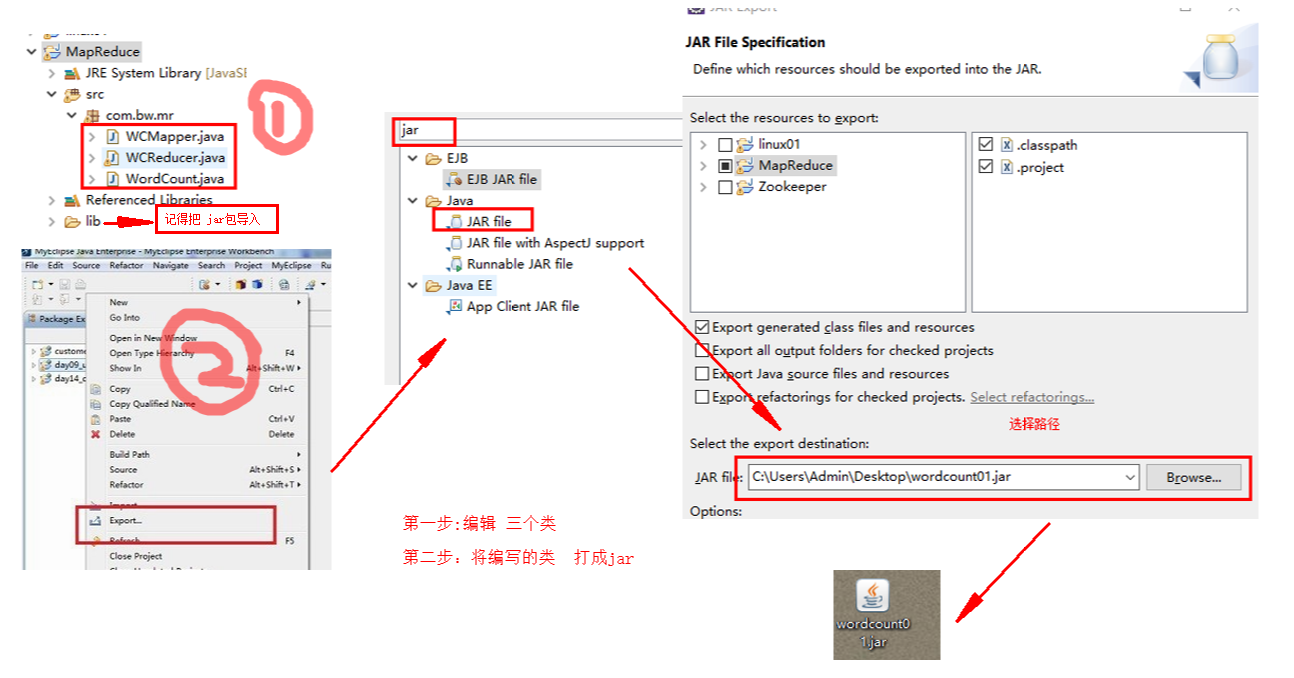
用eclipce编写 MR程序 MapReduce

package com.bw.mr; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; // yarn mr--->Mapper map Reducer reduce
// Mapper:四个泛型
//keyin :Map端输入的K值 keyin :偏移量
// hello word hello tom hello jim
//hello word 9 (hello word) String
// hello tom 17( hello tom)
// hello jim .....
//valuein: word
// hadoop 的api writeable
// keyout valueout ----> k(单词)
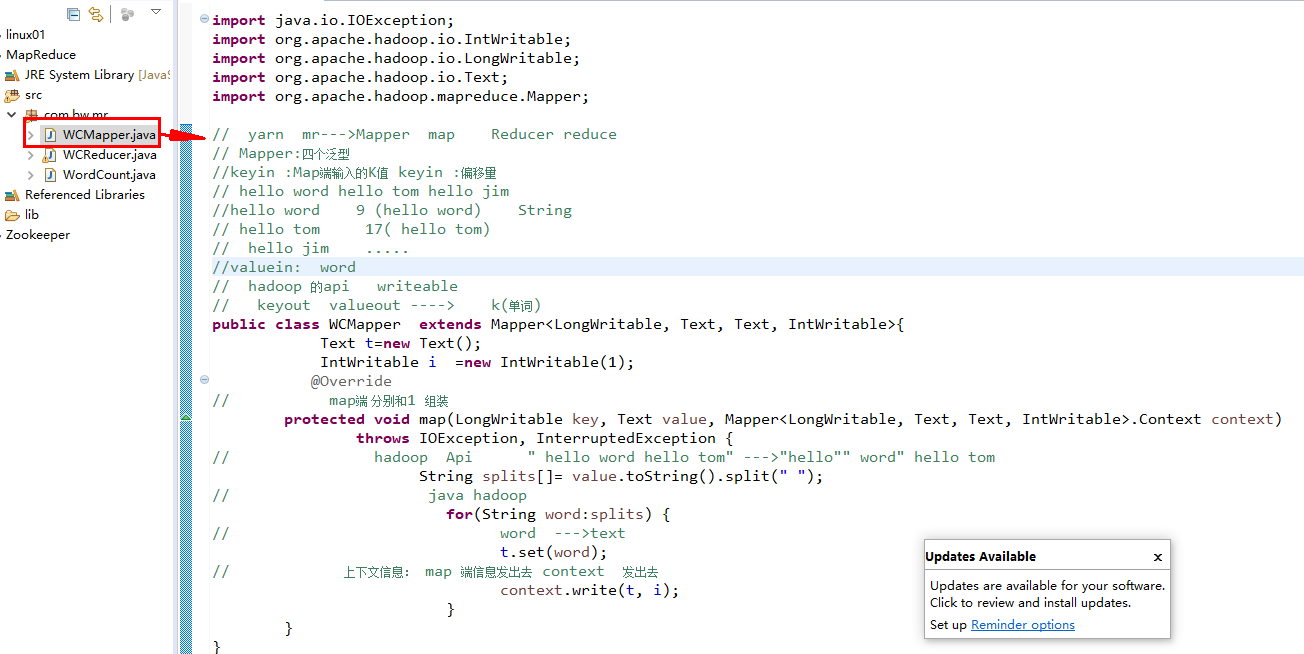
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text t=new Text();
IntWritable i =new IntWritable(1);
@Override
// map端 分别和1 组装
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// hadoop Api " hello word hello tom" --->"hello"" word" hello tom
String splits[]= value.toString().split(" ");
// java hadoop
for(String word:splits) {
// word --->text
t.set(word);
// 上下文信息: map 端信息发出去 context 发出去
context.write(t, i);
}
}
}
package com.bw.mr; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; // Mr :input map reduce output
// reducer reduce hello(1,1,1,1,1)-->hello(1+1+1+...)
// map(LongWriteable,text) --->(text,IntWriteable)\
// reduce (text,IntWriteable) ---->(text,IntWriteable)
// hello(1,1,1,1,1)-->
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 重写 reduce 方法
@Override
// text :word Iterable (111111111111111)
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
// reduce --->归并 ---》 word(1,1,1,1,...)---->word(count)
int count =0;
// 循环 。。。for
for(IntWritable i:arg1) {
count++;
}
// 输出最后 的结果
arg2.write(arg0,new IntWritable(count));
}
}
package com.bw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
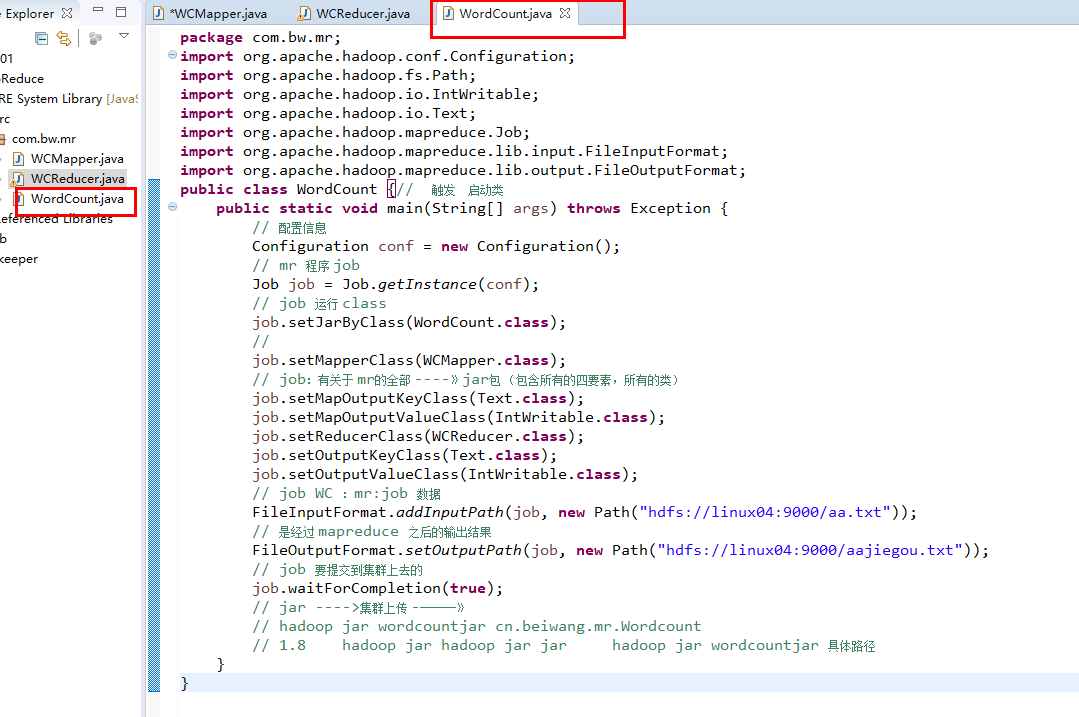
public class WordCount {// 触发 启动类
public static void main(String[] args) throws Exception {
// 配置信息
Configuration conf = new Configuration();
// mr 程序 job
Job job = Job.getInstance(conf);
// job 运行 class
job.setJarByClass(WordCount.class);
//
job.setMapperClass(WCMapper.class);
// job:有关于 mr的全部 ----》jar包 (包含所有的四要素,所有的类)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job WC :mr:job 数据
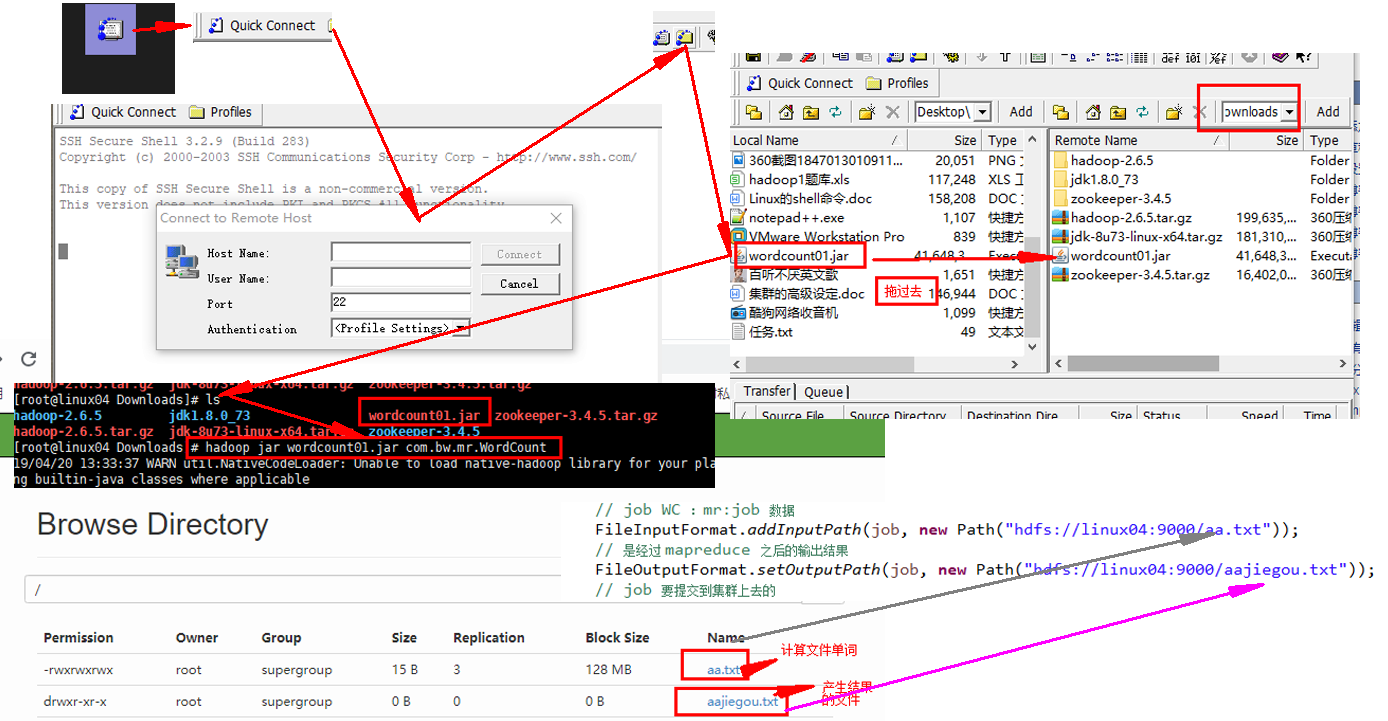
FileInputFormat.addInputPath(job, new Path("hdfs://linux04:9000/aa.txt"));
// 是经过 mapreduce 之后的输出结果
FileOutputFormat.setOutputPath(job, new Path("hdfs://linux04:9000/aajiegou.txt"));
// job 要提交到集群上去的
job.waitForCompletion(true);
// jar ---->集群上传 -————》
// hadoop jar wordcountjar cn.beiwang.mr.Wordcount
// 1.8 hadoop jar hadoop jar jar hadoop jar wordcountjar 具体路径
}
}
用eclipce编写 MR程序 MapReduce的更多相关文章
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 编写简单的Mapreduce程序并部署在Hadoop2.2.0上运行
今天主要来说说怎么在Hadoop2.2.0分布式上面运行写好的 Mapreduce 程序. 可以在eclipse写好程序,export或用fatjar打包成jar文件. 先给出这个程序所依赖的Mave ...
- Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html map,是m ...
- 用PHP编写Hadoop的MapReduce程序
用PHP编写Hadoop的MapReduce程序 Hadoop流 虽然Hadoop是用Java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编 ...
- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)
上一篇我们学习了MapReduce的原理,今天我们使用代码来加深对MapReduce原理的理解. wordcount是Hadoop入门的经典例子,我们也不能免俗,也使用这个例子作为学习Hadoop的第 ...
- 编写一个基于HBase的MR程序,结果遇到一个错:ERROR security.UserGroupInformation - PriviledgedActionException as ,求帮助
环境说明:Ubuntu12.04,使用CDH4.5,伪分布式环境 Hadoop配置如下: core-site.xml: <configuration><property> ...
- Windows下Eclipse提交MR程序到HadoopCluster
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载,转载请注明出处. 以前Eclipse上写好的MapReduce项目经常是打好包上传到Hadoop测试集 ...
- 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试
相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控 用python + hadoop streami ...
随机推荐
- 用ASP.NET Core 2.1 建立规范的 REST API -- 缓存和并发
本文所需的一些预备知识可以看这里: http://www.cnblogs.com/cgzl/p/9010978.html 和 http://www.cnblogs.com/cgzl/p/9019314 ...
- Asp.NetCore轻松学-业务重点-实现一个简单的手机号码验证
前言 本文纯干货,直接拿走使用,不用付费.在业务开发中,手机号码验证是我们常常需要面对的问题,目前市场上各种各样的手机号码验证方式,比如正则表达式等等,本文结合实际业务场景,在业务级别对手机号 ...
- Django-restframework 之权限源码分析
Django-restframework 之权限源码分析 一 前言 上篇博客分析了 restframework 框架的认证组件的执行了流程并自定义了认证类.这篇博客分析 restframework 的 ...
- jmFidExt - Fiddler 代理插件
本插件作用是把某些请求代理到指定的IP(端号)或文件,设置简便. 源码地址:https://github.com/jiamao/jmFidExt 示图 安装 下载代码,用开发工具vs2003及以上的版 ...
- [Nodejs] node的fs模块
fs 模块 Node.js 提供一组类似 UNIX(POSIX)标准的文件操作 API. Node 导入文件系统模块(fs).Node.js 文件系统(fs 模块)模块中的方法均有异步和同步版本,例如 ...
- qutebrowser 只用键盘操作的浏览器
一个 Qt 库制作的最简化浏览器,内核是 Chromium.最大特点就是它自带命令行,可以完全用键盘操作. 下载地址: 链接:https://share.weiyun.com/5Y2Ajvn 密码:m ...
- MVC开发模式简述
了解MVC开发模式,首先我们要了解一下发展趋势 一.什么是软件设计 Jack W.Reeves 于14年前(1992年),就在其撰写的论文——<What is Software Design&g ...
- 学习day01
1.web C/S:Client Server 客户端 服务器 QQ,... B/S:Browser Server 浏览器 服务器 PC机:Personal Computer 个人电脑 2.HTML ...
- vue中使用provide和inject刷新当前路由(页面)
1.场景 在处理列表时,常常有删除一条数据或者新增数据之后需要重新刷新当前页面的需求. 2.遇到的问题 1. 用vue-router重新路由到当前页面,页面是不进行刷新的 2.采用window.rel ...
- Easyui 关闭jquery-easui tab标签页前触发事件
关闭jquery-easui tab标签页前触发事件 by:授客 QQ:1033553122 测试环境 jquery-easyui-1.5.3 需求场景 点击父页面tab 页关闭按钮时,需要做判断,判 ...