关联分析中寻找频繁项集的FP-growth方法
关联分析是数据挖掘中常用的分析方法。一个常见的需求比如说寻找出经常一起出现的项目集合。
引入一个定义,项集的支持度(support),是指所有包含这个项集的集合在所有数据集中出现的比例。
规定一个最小支持度,那么不小于这个最小支持度的项集称为频繁项集(frequent item set)。
如何找到数据集中所有的频繁项集呢?
最简单的方法是对所有项集进行统计,可以通过逐渐增大项集大小的方式来遍历所有项集。比如说下面的数据集,先统计所有单个元素集合的支持度,{z} 的支持度为5 (这里把项目出现次数作为支持度,方便描述),然后逐渐增大项集大小,比如{z,r} 的支持度为1
| 数据集ID | 数据 |
| 001 | r, z, h, j, p |
| 002 | z, y, x, w, v, u, t, s |
| 003 | z |
| 004 | r, x, n, o, s |
| 005 | y, r, x, z, q, t, p |
| 006 | y, z, x, e, q, s, t, m |
显然这样的方式,计算量很大,当项目增多,项集的数目是指数增长的。当然我们也可以应用一些规律
1)如果一个项集是频繁项集,那么它的子集都是频繁项集
2)如果一个项集不是频繁项集,那么它的超集也不是频繁项集
Apriori算法就是应用了这些方法可以减少寻找频繁项集的计算。而FP-Growth算法则另辟蹊径,它在遍历数据的时候构造一个树结构,当树构造完成,每个节点记录的值就是这个节点到根节点路径上的项集的支持度。
首先对数据集中的数据按单个元素的支持度进行重排
| 数据集ID | 数据 | 按单元数支持度重排后的数据 |
| 001 | r, z, h, j, p | z, r |
| 002 | z, y, x, w, v, u, t, s | z, x, y, s, t |
| 003 | z | z |
| 004 | r, x, n, o, s | x, s, r |
| 005 | y, r, x, z, q, t, p | z, x, y, r, t |
| 006 | y, z, x, e, q, s, t, m | z, x, y, s, t |
然后把每一行数依次拿来构建FP树。把重排后每一行数据从左到右入树。从空集开始,如果树中已存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分支。
树构造完成后,以{x:3}这个节点为例,它表示了从这个节点到根节点路径上集合{x,z}的支持度为3。
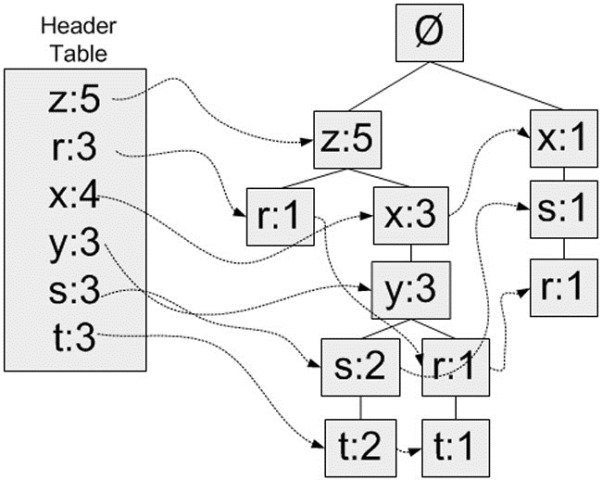
那么问题来了,我们如何保证我们能获得所有的频繁项集,即支持度大于最小支持度的项集。是找出节点值大于最小支持度就够了吗?比如设最小支持度为3,从树上可以看出{z,x,y}的支持度为3,但是仔细观察{z,x,y,t}这个项集的支持度也是为3,如何做呢?
首先为每个元素的找到所有前缀路径,一条前缀路径,是指元素父节点到根节点的路径
| 单元素 | 前缀路径 |
| z | {}: 5 |
| r | {x, s}: 1, {z, x, y}: 1, {z}: 1 |
| x | {z}: 3, {}: 1 |
| y | {z, x}: 3 |
| s | {z, x, y}: 2, {x}: 1 |
| t | {z, x, y, s}: 2, {z, x, y, r}: 1 |
然后对每个元素的所有前缀路径再执行一次FP树的构造过程,这样看到去除这个元素后能得到什么样的频繁项集。如下可以顺利得出{z,x,y} + {t}是一个支持度为3的频繁项集。
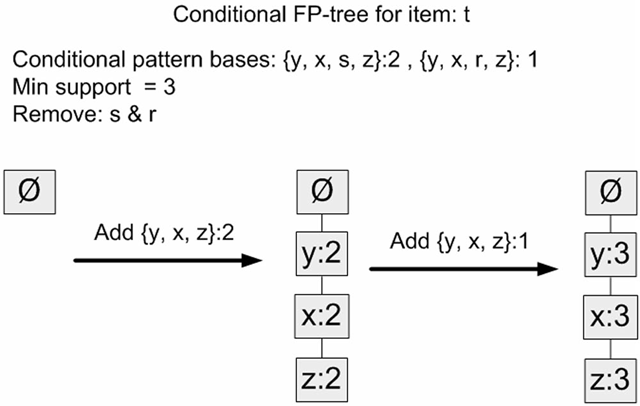
据此,FP-Growth方法就可以算出数据集中最小支持度为3的频繁项集:{z},{z,x},{z,x,y},{z,x,y,t}
参考:
1. https://www.cnblogs.com/qwertWZ/p/4510857.html
关联分析中寻找频繁项集的FP-growth方法的更多相关文章
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- 第十五篇:使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- R_Studio(时序)Apriori算法寻找频繁项集的方法
应用ARIMA(1,1,0)对2015年1月1日到2015年2月6日某餐厅的销售数量做为期5天的预测 setwd('D:\\dat') #install.packages("forecast ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
- FP-growth算法发现频繁项集(一)——构建FP树
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth.Apriori通过不断的构造候选集.筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- 海量数据挖掘MMDS week2: Association Rules关联规则与频繁项集挖掘
http://blog.csdn.net/pipisorry/article/details/48894977 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
随机推荐
- spring设计模式_代理模式
代理模式应该是Spring核心设计模式之一了 先说下代理模式特性: 1.有代理人和被代理人 2.对于被代理的人来说,这件事情是一定要做的,但是我又不想做,所有就找代理人来做. 3.需要获取到被代理人的 ...
- Android 性能测试优质实践汇总
这两天把testerhome上的关于Android 性能测试的精品文章看了一遍,很有收获,学习到了Android 性能测试该关注的一些细节.我所说的“精品”是指对我自己有启发的文章,可以被自己运用起来 ...
- springboot~maven制作底层公用库
把一些公用方法,类型抽象到一个项目里,让其它项目依赖它,这种设计是一种解耦的体现,其实像springboot就是我们的一种依赖,他里面有很多子模块,用到哪个就添加哪个依赖即可,像redis,mongo ...
- Ubuntu下搜狗输入法的安装教程
前面写过一篇centos7下搜狗输入法的安装教程,现在把搜狗输入法在Ubuntu下的安装方法也记录一下,相比之下Ubuntu下安装搜狗输入法要简便得多 安装fcitx以支持搜狗输入法 ...
- Python:bs4的使用
概述 bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签. 一.初始化 from bs4 import BeautifulSoup soup ...
- java 并发多线程 锁的分类概念介绍 多线程下篇(二)
接下来对锁的概念再次进行深入的介绍 之前反复的提到锁,通常的理解就是,锁---互斥---同步---阻塞 其实这是常用的独占锁(排它锁)的概念,也是一种简单粗暴的解决方案 抗战电影中,经常出现为了阻止日 ...
- DS控件库 一个简单的血条颜色渐变方案
Private Sub DS按钮1_ButtonClick(Sender As Object) Handles DS按钮1.ButtonClick Dim T As New Threading.Thr ...
- 为 Eureka 服务注册中心实现安全控制
上一篇Eureka 实现微服务注册发现讲了用 Eureka 实现单体版的服务注册与发现.因为本篇是在上一篇的基础上的一点扩充,所以读此篇之前要保证看了上一篇. Eureka 如果不加安全控制,会存在下 ...
- Java 项目中一种简单的动态修改配置即时生效的方式 WatchService
这种方式仅适合于比较小的项目,例如只有一两台服务器,而且配置文件是可以直接修改的.例如 Spring mvc 以 war 包的形式部署,可以直接修改resources 中的配置文件.如果是 Sprin ...
- oracle数据库导出表结构步骤
导出完成后在状态栏中显示Find