CRL快速开发框架升级到4.52,谈谈开发过程中的优化
CRL4.5版本已经稳定使用于目前的几个中型项目中,在实际使用中,也发现了不少问题,这些问题都在4.52中提交
CRL具体功能和使用请浏览 CRL快速开发框架系列教程
由于现在项目是一套业务系统,查询需求比较多,CRL带的语法解析都能满足,特殊的可手写SQL,在针对查询的优化,以下几点
对查询调用的监视
由于业务封装写得非常复杂,方法嵌套很严重,无法检查一个方法内有多少查询,需不需要优化,因此使用CallContext进行了监视,并生成报表
public ActionResult RunTime()
{
var str = CRL.Runtime.RunTimeService.Display();
return Content(str);
}
最终如下图:
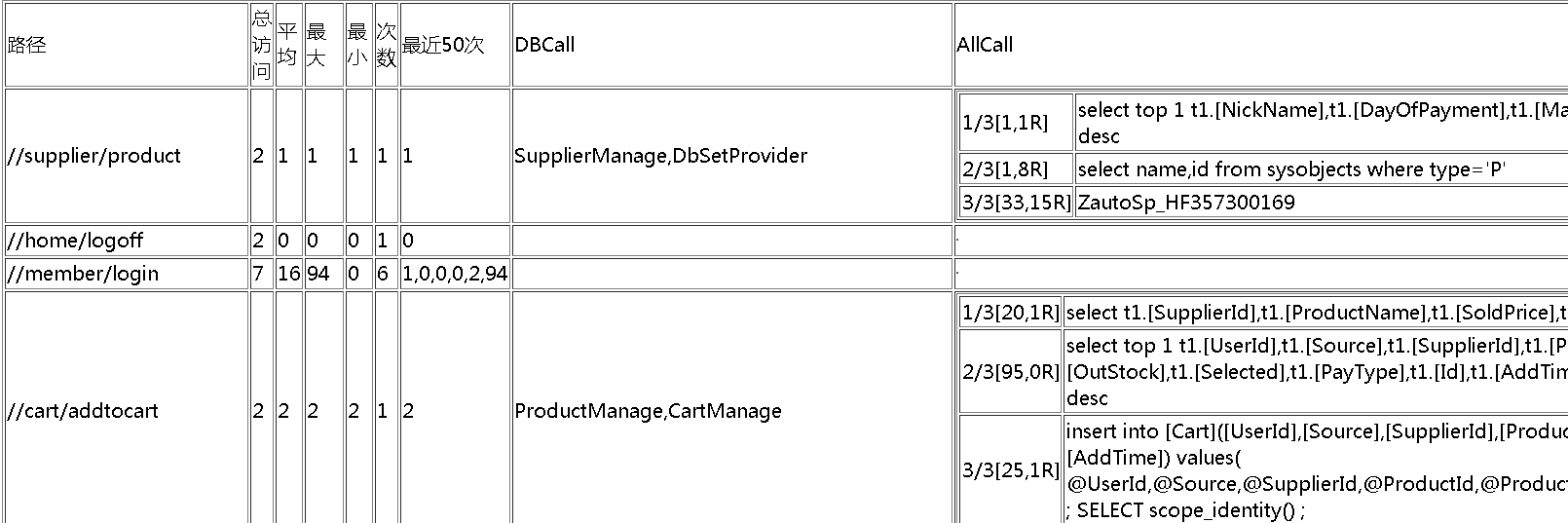
路径:表示调用方法的路径
DBCall:表示实例化的数据管理类
ALLCall:表示所有数据访问调用
表达式解析内存占用
在一次更新中,为了使解析速度更快,将表达式进行了缓存,只有参数进行了重解析,看上去是省了不少,如下所示
CRLExpression.CRLExpression BinaryExpressionHandler(Expression left, Expression right, ExpressionType expType)
var key = string.Format("{0}{1}{2}{3}", __PrefixsAllKey, left, expType, right);
var a = BinaryExpressionCache.TryGetValue(key, out cacheItem);
if (a)
{
返回缓存
}
但是Expression left.ToString()效率并不高,并且占内存,所以这个并没有什么卵用
字符串变量内存占用
因为CRL查询所有参数都需要进行参数化,因此需要对应的参数名,如以下表达式:b=>b.Id==1
参数名为:@p1,若再有参数,依次类推,然而@p1由 string.Format("{0}p{1}","@",1)生成,在对性能测试时发现,这个Format占用了很多内存
于是解决办法,还是缓存参数名,提前生成,重复使用
if (parameDic == null)
{
parameDic = new Dictionary<int, string>();
for (int i = 0; i <= 5000; i++)
{
parameDic.Add(i, __DBAdapter.GetParamName("p", i));
}
}
var _par = parameDic[parIndex];
AddParame(_par, par);
字段格式化内存占用
CRL查询默认是查询所有字段,所以查询为 select t1.Id,t1.Name,t1.Code.....,在没有手动选择查询字段时,这些select其实一直是一样的,通过性能监视发现,好多内存被这重复解析占用了
优化后,当是查询所有字段,从缓存里生成
if (GetPrefix(__MainType) == "t1.")
{
key = __MainType.ToString();
SelectFieldInfo value;
var a = queryFieldCache.TryGetValue(key, out value);
if (a)
{
if (!cacheAllFieldString)
{
var item = value.Clone();
item.CleanQueryFieldString();
_CurrentSelectFieldCache = item;
}
else
{
_CurrentSelectFieldCache = value;
}
return;
}
cache = true;
}
因为CRL对查询作了关键字处理,包括表名,字段名,所以最终的语句为
以MSSQL为例:select t1.[Name] from [table1] t1
方法为
public override string KeyWordFormat(string value)
{
return string.Format("[{0}]", value);
}
实际上,每个字段只用生成一次就行了,再次使用时从缓存中取,节省了不少内占用
public string FieldNameFormat(Attribute.FieldAttribute field)
{
if (string.IsNullOrEmpty(field.MapingNameFormat))
{
field.MapingNameFormat = KeyWordFormat(field.MapingName);
}
return field.MapingNameFormat;
}
手写语句提取参数
直接将参数拼在SQL里好像不怎么雅观,并且,容易造成语法错误和注入漏洞,如下:
string sql = "select top 10 Id,ProductId,ProductName1 from ProductData a where a.addtime>='2017-09-01' and a.id=234";
var helper = DBExtend;
var list = helper.ExecDynamicList(sql);
CRL新增了方法,能重新处理手写的SQL为参数化
int parIndex = 1;
/// <summary>
/// 提取SQL参数
/// </summary>
/// <param name="db"></param>
/// <param name="sql"></param>
/// <param name="manual"></param>
/// <returns></returns>
public virtual string ReplaceParameter(CoreHelper.DBHelper db,string sql,bool manual = false)
{
if (!SettingConfig.ReplaceSqlParameter && !manual)
{
return sql;
}
//return sql;
var re = @"((\s|,)*)(\w+)\s*(>|<|=|!=|>=|<=)\s*('(.*?)'|([1-9]\d*.\d*|0.\d*[1-9]\d*))(\s|,|\))";
sql = sql + " ";
if (!Regex.IsMatch(sql, re, RegexOptions.IgnoreCase))
{
return sql;
}
Regex r = new Regex(re, RegexOptions.IgnoreCase);
List<string> pars = new List<string>();
//int index = 1;
for (var m = r.Match(sql); m.Success; m = m.NextMatch())
{
var name = m.Groups[3];
var op = m.Groups[4];
var value1 = m.Groups[6];
var value2 = m.Groups[7];
var value = string.IsNullOrEmpty(value2.Value) ? value1 : value2;
var p = m.Groups[1];
var p2 = m.Groups[8];
var pName = GetParamName("_p", parIndex);
db.AddParam(pName, value.ToString());
sql = sql.Replace(m.ToString(), string.Format("{0}{1}{4}{2}{3} ", p, name, pName, p2, op));
parIndex += 1;
}
return sql;
}
在配置为自动替换SQL拼接参数(CRL.SettingConfig.ReplaceSqlParameter=true),实际输出将为:
select top 10 Id,ProductId,ProductName1 from ProductData a where a.addtime>=@p1 and a.id=@p2
异步插入MSMQ的实现
在某个业务中,一张表很频繁的单个插入,占用大量资源,专门为这写个消息队列好像不怎么高明,下次又有这样的情况怎么办
于是有就了,为每个对象定义自已的消息队列和处理,用第三方的不太好集成,就是微软自家的吧
/// <summary>
/// 添加一条记录[基本方法]
/// 异步时,会定时执行批量插入,依赖MSMQ服务
/// </summary>
/// <param name="p"></param>
/// <param name="asyn">异步插入</param>
public virtual void Add(TModel p, bool asyn = false)
调用参数为true时,则为TModel类型创建消息队列,并异步分批次插入到数据库中,比如在10秒内连续调用了100次此方法
只是将数据存入了消息队列,在队列下个处理周期,将这100条批量插入到数据库,效率倍增
DbSet方式的实现
在Entity Framework里,有DbSet的概念,配置好数据关系后,关联对象直接就能取到了
在CRL里,简单实现一下
public class Order : CRL.IModelBase
{
public CRL.Set.DbSet<ProductData> Products//返回关联的Product
{
get
{
return GetDbSet<ProductData>(b => b.Id, ProductId);
}
}
public CRL.Set.EntityRelation<Member> Member//返回关联的Member
{
get
{
return GetEntityRelation<Member>(b => b.Id, UserId);
}
}
}
调用如下:
var order = new Code.Order();
//所有
var product = order.Products.ToList();
//返回关联过的查询,使用完整查询满足更多需求
var product2 = order.Products.GetQuery();
var p = new Code.ProductData() { BarCode = "33333" };
//添加一项
order.Products.Add(p);
order.Products.Delete(p);//删除一项
//返回完整的BaseProvider
var provider = order.Products.GetProvider();
//返回关联的member,在调用时返回,在循环内调用会多次调用数据库
var member = order.Member.Value;
十年磨一剑,在代码写得越来越深入,再回头看自已的代码,残破不堪.
欢迎下载源码交流讨论
获取CRL最新源码见文章底部下载
CRL快速开发框架升级到4.52,谈谈开发过程中的优化的更多相关文章
- 非关系型数据库来了,CRL快速开发框架升级到版本4
轮子?,我很任性,我要造不一样的轮子,同时支持关系型和非关系型的框架有没有 新版数据查询作了些调整,抽象了LabmdaQueryy和DBExtend,升级到版本4,非关系数据库MongoDB被支持了! ...
- CRL快速开发框架升级到3.1
CRL是一款面向对象的轻量级ORM框架,本着快速开发,使用简便的原则,设计为 无需关心数据库结构,CRL自动维护创建,即写即用(CRL内部有表结构检查机制,保证表结构一致性) 无需第三方工具生成代理类 ...
- CRL快速开发框架开源完全转到Github
CRL简介 CRL是一款面向对象的轻量级ORM框架,本着快速开发,使用简便的原则,设计为 无需关心数据库结构,CRL自动维护创建,即写即用(CRL内部有表结构检查机制,保证表结构一致性) 无需第三方工 ...
- CRL快速开发框架系列教程十三(嵌套查询)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- CRL快速开发框架系列教程十二(MongoDB支持)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- CRL快速开发框架系列教程十(导出对象结构)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- CRL快速开发框架系列教程九(导入/导出数据)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- CRL快速开发框架系列教程七(使用事务)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
随机推荐
- SQL Server 初识游标
---恢复内容开始--- 游标:游标是一种能从包含多个数据的结果集每次提取一条的机制 游标的特点是: 检索得到的数据集更加灵活 可有针对性的对数据进行操作 拥有对数据进行删除和更新的能力 为何使用游标 ...
- python3学习笔记(3)
一.内置函数补充1.callable()检测传递的参数是否可以被调用.def f1() pass可以被调用f2 = 123不可以被调用2.chr()和ord()chr()将ascii码转换成字符,or ...
- PL/SQL 游标 (实验七)
PL/SQL 游标 emp.dept 目标表结构及数据 要求 基于部门表建立游标dept_cursor1,使用记录变量接收游标数据,输出部门表信息: 显示格式: 部 门 号: XXX 部门名称: XX ...
- Function Programming - 柯里化(curry)
看到一篇非常不错的文章,这里分享给大家:http://www.jianshu.com/p/fa3568087881. 首先,柯里化的定义:你可以只透过部分的参数呼叫一个function,它会回传一个f ...
- Unity20172.0 Android平台打包
Android SDK及Jdk百度网盘下载链接:https://pan.baidu.com/s/1dFbEmdz 密码:pt7b Unity20172.0 Android平台打包 简介说明: 第一步: ...
- ShoneSharp语言(S#)的设计和使用介绍系列(1)— 开篇
ShoneSharp语言(S#)的设计和使用介绍 系列(1)- 开篇 作者:Shone 声明:原创文章欢迎转载,但请注明出处,https://www.cnblogs.com/ShoneSharp. 一 ...
- Numpy入门 - 线性代数运算
本节矩阵线性代数有很多内容,这里重点演示计算矩阵的行列式.求逆矩阵和矩阵的乘法. 一.计算矩阵行列式[det] import numpy as np from numpy.linalg import ...
- ##8.创建虚拟机-- openstack pike
##8. openstack创建虚拟机 openstack pike 安装 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html ##.创建虚拟机.txt.s ...
- 简单的基于Vue-axios请求封装
具体实现思路=>封装之前需要用npm安装并引入axios,使用一个单独的js模块作为接口请输出对象,然后export dafult 这个对象. 1.首先我们需要在Vue实例的原型prototyp ...
- MySQL 性能优化的最佳20多条经验分享(一)(转)
当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能.这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库.希望下面的这 ...