OpenCV二维Mat数组(二级指针)在CUDA中的使用
CUDA用于并行计算非常方便,但是GPU与CPU之间的交互,比如传递参数等相对麻烦一些。在写CUDA核函数的时候形参往往会有很多个,动辄达到10-20个,如果能够在CPU中提前把数据组织好,比如使用二维数组,这样能够省去很多参数,在核函数中可以使用二维数组那样去取数据简化代码结构。当然使用二维数据会增加GPU内存的访问次数,不可避免会影响效率,这个不是今天讨论的重点了。
举两个代码栗子来说明二维数组在CUDA中的使用(亲测可用):
1. 普通二维数组示例:
输入:二维数组A(8行4列)
输出:二维数组C(8行4列)
函数功能:将数组A中的每一个元素加上10,并保存到C中对应位置。
这个是一个简单的示例,以一级指针和二级指针开访问二维数组中的数据,主要步骤如下:
(1)为二级指针A、C和一级指针dataA、dataC分配CPU内存。二级指针指向的内存中保存的是一级指针的地址。一级指针指向的内存中保存的是输入、输出数据。
(2)在设备端(GPU)上同样建立二级指针d_A、d_C和一级指针d_dataA、d_dataC,并分配GPU内存,原理同上,不过指向的内存都是GPU中的内存。
(3)通过主机端一级指针dataA将输入数据保存到CPU中的二维数组中。
(4)关键一步:将设备端一级指针的地址,保存到主机端二级指针指向的CPU内存中。
(5)关键一步:使用cudaMemcpy()函数,将主机端二级指针中的数据(设备端一级指针的地址)拷贝到设备端二级指针指向的GPU内存中。这样在设备端就可以使用二级指针来访问一级指针的地址,然后利用一级指针访问输入数据。也就是A[][]、C[][]的用法。
(6)使用cudaMemcpy()函数将主机端一级指针指向的CPU内存空间中的输入数据,拷贝到设备端一级指针指向的GPU内存中,这样输入数据就算上传到设备端了。
(7)在核函数addKernel()中就可以使用二维数组的方法进行数据的读取、运算和写入。
(8)最后将设备端一级指针指向的GPU内存中的输出数据拷贝到主机端一级指针指向的CPU内存中,打印显示即可。
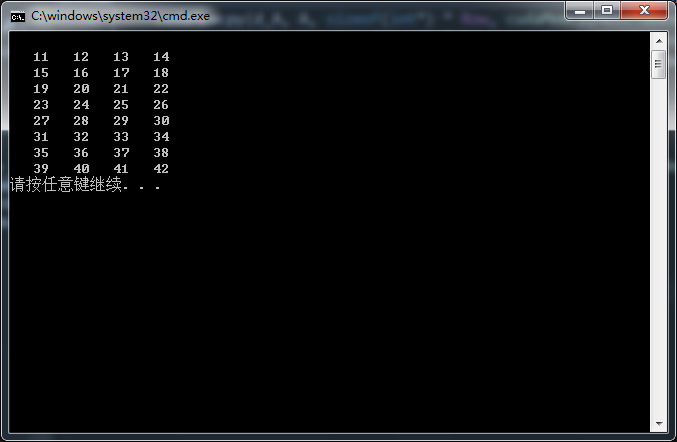
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <opencv2\opencv.hpp>
#include <iostream>
#include <string> using namespace cv;
using namespace std; #define Row 8
#define Col 4 __global__ void addKernel(int **C, int **A)
{
int idx = threadIdx.x + blockDim.x * blockIdx.x;
int idy = threadIdx.y + blockDim.y * blockIdx.y;
if (idx < Col && idy < Row)
{
C[idy][idx] = A[idy][idx] + ;
}
} int main()
{
int **A = (int **)malloc(sizeof(int*) * Row);
int **C = (int **)malloc(sizeof(int*) * Row);
int *dataA = (int *)malloc(sizeof(int) * Row * Col);
int *dataC = (int *)malloc(sizeof(int) * Row * Col); int **d_A;
int **d_C;
int *d_dataA;
int *d_dataC;
//malloc device memory
cudaMalloc((void**)&d_A, sizeof(int **) * Row);
cudaMalloc((void**)&d_C, sizeof(int **) * Row);
cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col);
cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col);
//set value
for (int i = ; i < Row*Col; i++)
{
dataA[i] = i+;
}
//将主机指针A指向设备数据位置,目的是让设备二级指针能够指向设备数据一级指针
//A 和 dataA 都传到了设备上,但是二者还没有建立对应关系
for (int i = ; i < Row; i++)
{
A[i] = d_dataA + Col * i;
C[i] = d_dataC + Col * i;
} cudaMemcpy(d_A, A, sizeof(int*) * Row, cudaMemcpyHostToDevice);
cudaMemcpy(d_C, C, sizeof(int*) * Row, cudaMemcpyHostToDevice);
cudaMemcpy(d_dataA, dataA, sizeof(int) * Row * Col, cudaMemcpyHostToDevice);
dim3 block(, );
dim3 grid( (Col + block.x - )/ block.x, (Row + block.y - ) / block.y );
addKernel << <grid, block >> > (d_C, d_A);
//拷贝计算数据-一级数据指针
cudaMemcpy(dataC, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); for (int i = ; i < Row*Col; i++)
{
if (i%Col == )
{
printf("\n");
}
printf("%5d", dataC[i]);
}
printf("\n");
}
2.OpenCV中Mat数组示例
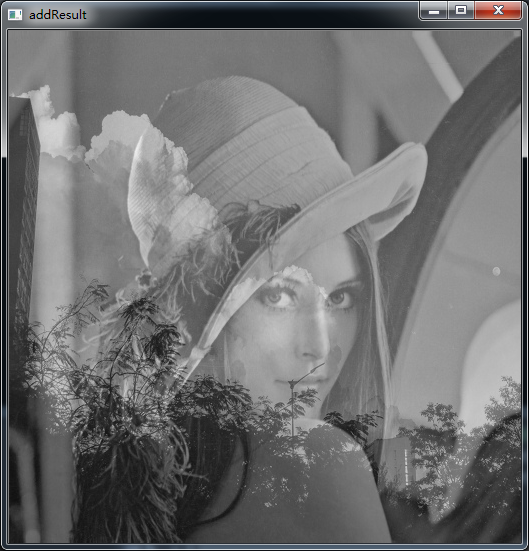
输入:图像Lena.jpg
输出:图像moon.jpg
函数功能:求两幅图像加权和
原理和上面一样,流程上的差别就是输入的二维数据是下面两幅图像数据,然后在CUDA中进行加权求和。


效果如下:
代码在此,以供参考
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <opencv2\opencv.hpp>
#include <iostream>
#include <string> using namespace cv;
using namespace std; __global__ void addKernel(uchar **pSrcImg, uchar* pDstImg, int imgW, int imgH)
{
int tidx = threadIdx.x + blockDim.x * blockIdx.x;
int tidy = threadIdx.y + blockDim.y * blockIdx.y;
if (tidx<imgW && tidy<imgH)
{
int idx=tidy*imgW+tidx;
uchar lenaValue=pSrcImg[][idx];
uchar moonValue=pSrcImg[][idx];
pDstImg[idx]= uchar(0.5*lenaValue+0.5*moonValue);
}
} int main()
{
//OpenCV读取两幅图像
Mat img[];
img[]=imread("data/lena.jpg", );
img[]=imread("data/moon.jpg", );
int imgH=img[].rows;
int imgW=img[].cols;
//输出图像
Mat dstImg=Mat::zeros(imgH, imgW, CV_8UC1);
//主机指针
uchar **pImg=(uchar**)malloc(sizeof(uchar*)*); //输入 二级指针 //设备指针
uchar **pDevice;//输入 二级指针
uchar *pDeviceData;//输入 一级指针
uchar *pDstImgData;//输出图像对应设备指针 //分配GPU内存
cudaError err;
//目标输出图像分配GPU内存
err=cudaMalloc(&pDstImgData, imgW*imgH*sizeof(uchar));
//设备二级指针分配GPU内存
err=cudaMalloc(&pDevice, sizeof(uchar*)*);
//设备一级指针分配GPU内存
err=cudaMalloc(&pDeviceData, sizeof(uchar)*imgH*imgW*); //关键:主机二级指针指向设备一级指针位置,这样才能使设备的二级指针指向设备的一级指针位置
for (int i=; i<; i++)
{
pImg[i]=pDeviceData+i*imgW*imgH;
} //拷贝数据到GPU
//拷贝主机二级指针中的元素到设备二级指针指向的GPU位置 (这个二级指针中的元素是设备中一级指针的地址)
err=cudaMemcpy(pDevice, pImg, sizeof(uchar*)*, cudaMemcpyHostToDevice);
//拷贝图像数据(主机一级指针指向主机内存) 到 设备一级指针指向的GPU内存中
err=cudaMemcpy(pDeviceData, img[].data, sizeof(uchar)*imgH*imgW, cudaMemcpyHostToDevice);
err=cudaMemcpy(pDeviceData+imgH*imgW, img[].data, sizeof(uchar)*imgH*imgW, cudaMemcpyHostToDevice); //核函数实现lena图和moon图的简单加权和
dim3 block(, );
dim3 grid( (imgW+block.x-)/block.x, (imgH+block.y-)/block.y);
addKernel<<<grid, block>>>(pDevice, pDstImgData, imgW, imgH);
cudaThreadSynchronize(); //拷贝输出图像数据至主机,并写入到本地
err=cudaMemcpy(dstImg.data, pDstImgData, imgW*imgH*sizeof(uchar), cudaMemcpyDeviceToHost);
imwrite("data/synThsis.jpg", dstImg);
}
OpenCV二维Mat数组(二级指针)在CUDA中的使用的更多相关文章
- 计算机二级-C语言-程序填空题-190109记录-对二维字符串数组的处理
//给定程序,函数fun的功能是:求出形参ss所指字符串数组中最长字符串的长度,将其余字符串右边用字符*补齐,使其与最长的字符串等长.ss所指字符串数组中共有M个字符串,且串长<N. //重难点 ...
- 二维字符数组利用gets()函数输入
举例: ][]; ;i<;i++) gets(a[i]); a是二维字符数组的数组名,相当于一维数组的指针, 所以a[i]就相当于指向第i个数组的指针,类型就相当于char *,相当于字符串.
- 分配一维动态数组or 二维动态数组的方法以及学习 new 方法or vector
先来个开胃菜 // 使用new动态分配存储空间 #include<iostream> using std::cout; int main() { // 第1种方式 int *a=new i ...
- 【C/C++】二维数组的传参的方法/二维字符数组的声明,使用,输入,传参
[问题] 定义了一个子函数,传参的内容是一个二维数组 编译提示错误 因为多维数组作为形参传入时,必须声明除第一位维外的确定值,否则系统无法编译(算不出偏移地址) [二维数组的传参] 方法一:形参为二维 ...
- PHP二维关联数组的遍历方式
采用foreach循环对二维索引数组进行遍历,相对来讲速度更快,效率更高,foreach循环是PHP中专门用来循环数组的.实例也相对简单,多加练习,想清楚程序运行逻辑即可. <?php $arr ...
- Task 4.4二维环形数组求最大子矩阵之和
任务: (1)输入一个二维整形数组,数组里有正数也有负数. (2)二维数组首尾相接,象个一条首尾相接带子一样. (3)数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和. (4)求所有子数 ...
- 子串查询(二维前缀数组) 2018"百度之星"程序设计大赛 - 资格赛
子串查询 Time Limit: 3500/3000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Subm ...
- go 动态数组 二维动态数组
go使用动态数组还有点麻烦,比python麻烦一点,需要先定义. 动态数组申明 var dynaArr []string 动态数组添加成员 dynaArr = append(dynaArr, &quo ...
- int (*p)[4] p 是二级指针 二维数组 二级指针 .xml
pre{ line-height:1; color:#2f88e4; background-color:#e9ffff; font-size:16px;}.sysFunc{color:#3d7477; ...
随机推荐
- MySQL之多表操作
前言:之前已经针对数据库的单表查询进行了详细的介绍:MySQL之增删改查,然而实际开发中业务逻辑较为复杂,需要对多张表进行操作,现在对多表操作进行介绍. 前提:为方便后面的操作,我们首先创建一个数据库 ...
- MySQL之常用函数
MySQL有如下常用函数需要掌握: 1.数学类函数 函数名称 作用 ABS(x) 返回x的绝对值 SQRT(x) 返回x的非负二次方根 MOD(x,Y ...
- Linux CentOS 7 防火墙/端口设置
CentOS升级到7之后用firewall代替了iptables来设置Linux端口, 下面是具体的设置方法: []:选填 <>:必填 [<zone>]:作用域(block.d ...
- 单独创建一个Android Test Project 时junit 的配置和使用
现在的集成ADT后Eclipse都可以直接创建Android Test Project 如图所示: 命名后选择你要测试的单元程序,比如我自己准备测试sms,便可以如图所示那样选择 本人新建的测试工程为 ...
- HDU1403Longest Common Substring
明天写 超时代码: #include<cstdio> #include<cstdlib> #include<iostream> #include<cstrin ...
- zoj1871steps 数学 水
zoj1871 题目大意 ...
- TypeScript中的怪语法
TypeScript中的怪语法 如何处理undefined 和 null undefined的含义是:一个变量没有初始化. null的含义是:一个变量的值是空. undefined 和 null 的最 ...
- 【转】嵌入式C语言调试开关
在调试程序时,经常会用到assert和printf之类的函数,我最近做的这个工程里就有几百个assert,在你自认为程序已经没有bug的时候,就要除去这些调试代码,应为系统在正常运行时这些用于调试的信 ...
- jquery入门知识点总结(转)
一.jquery的加载方法 $(document).ready(function(){js代码}); $(function(){js代码});(一般使用这个); 注意点1:使用jquery必须先导入函 ...
- [原创]浅谈JAVA在ACM中的应用
由于java里面有一些东西比c/c++方便(尤其是大数据高精度问题,备受广大ACMer欢迎),所以就可以灵活运用这三种来实现编程,下面是我自己在各种大牛那里总结了一些,同时加上自己平时遇到的一些jav ...