Python 实现的随机森林
随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险。 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失。也可用来预测疾病的风险和病患者的易感性。
随机森林是一个可做能够回归和分类。 它具备处理大数据的特性,而且它有助于估计或变量是非常重要的基础数据建模。
这是一篇关于使用Python来实现随机森林文章。
什么是随机森林?
随机 森林 是 几乎 任何 预测 问题 (甚至 非直线 部分) 的固有 选择 。 它是 一个 相对较 新 的 机器 学习 的 策略 ( 在90 年代产生于 贝尔 实验室 ) 和 它 可以 几乎用于 任何方面 。 它 属于 机器 学习 算法 一大类----- 集成学习 方法 。
集成学习
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
随机森林是集成学习的一个子类,由于它依靠于策率树的合并。你可以在这找到用python实现集成学习的文档:Scikit 学习文档。
随机决策树
我们 知道 随机 森林 是 其他 的模型 聚合, 但 它 聚合 了什么 类型 模型 ? 你 可能 已经 从 其 名称 、 随机 森林 聚合 分类(或 回归) 的 树 中猜到。 决策 树 是 由 一 系列 的 决策的组合, 可 用于 分类 观察 数据集 。
随机森林
算法引入了一个随机森林来 自动 创建 随机 决策 树 群 。 由于 树 随机 生成 的树, 大部分的树(或许 99.9%树) 不 会 对 学习 的 分类/回归 问题 都 有意义 。

如果 观察到 长度 为 45 ,蓝 眼睛 , 和 2 条腿 , 就 被 归类 为 红色 。
树的投票
所以10000个(概率上)糟糕的模型有TMD什么好的?好吧,这样确实没什么特别的好处。但是随着很多糟糕的决策树被生成,其中也会有很少确实很优秀的决策树。
当你要做预测的时候,新的观察到的特征随着决策树自上而下走下来,这样一组观察到的特征将会被贴上一个预测值/标签。一旦森林中的每棵树都给出了预测值/标签,所有的预测结果将被归总到一起,所有树的模式投票被返回做为最终的预测结果。
简单来说,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会超脱于芸芸“噪音”,做出一个好的预测。

为什么你让我用它?
简单
随机森林就是学习方法中的Leatherman呀。你几乎可以把任何东西扔进去,它基本上都是可供使用的。在估计推断映射方面特别好用,以致都不需要像SVM那样做很多调试(也就是说对于那些最后期限很紧的家伙们真是太棒了)。
[译者注:Leatherman就是那家生产多功能折叠刀的公司,类似瑞士军刀]
一个映射的例子
随机森林在没有精心准备的数据映射的情况下也能学习。以方程f(x) = log(x)为例。
制造一些假数据,并且加上一点儿噪音。
import numpy as np
x = np.random.uniform(1, 100, 1000)
y = np.log(x) + np.random.normal(0, .3, 1000)

如果 我们 建立了 一个 基本 的 线性 模型 通过使用 x 来预测y, 我们需要 作 一 条 直线 , 算是 平分 log (x) 函数。 而 如果 我们 使用 一个 随机 的 森林 , 它 不会 更 好 的 逼近 log (x) 曲线 并能够使得它更像实际函数。


你 也许会说 随机 森林 有点 扰乱了 log(x) 函数 。 不管怎样 , 我 都认为 这 做了一个 很 好 的 说明 如何 随机 森林 并 未绑定于 线性 约束 。
使用
变量选择
随机森林最好的用例之一是特征选择。尝试很多决策树变种的一个副产品就是你可以检测每棵树中哪个变量最合适/最糟糕。
当一棵树使用一个变量,而另一棵不使用这个变量,你就可以从是否包含这个变量来比较价值的减少或增加。优秀的随机森林实现将为你做这些事情,所以你需要做的仅仅是知道去看那个方法或参数。
在下述的例子中,我们尝试去指出对于将酒分为红酒或者白酒哪个变量是最重要的。


分类
随机森林也很善于分类。它可以被用于为多个可能目标类别做预测,它也可以被校正输出概率。你需要注意的一件事情是过拟合。随机森林容易产生过拟合,特别是在数据集相对小的时候。当你的模型对于测试集合做出“太好”的预测的时候就应该怀疑一下了。
产生过拟合的一个原因是在模型中只使用相关特征。然而只使用相关特征并不总是事先准备好的,使用特征选择(就像前面提到的)可以使其更简单。

回归
是的,它也可以做回归。
我们已经发现随机森林——不像其它算法——对分类变量或者分类变量和真实变量混合学习的非常好。具有高基数(可能值的#)的分类变量是很棘手的,所以在你的口袋中放点儿这样的东西将会是非常有用的。
一个简短的python例子
Scikit-Learn是开始使用随机森林的一个很好的方式。scikit-learn API在所以算法中极其的一致,所有你测试和在不同的模型间切换非常容易。很多时候,我从一些简单的东西开始,然后转移到了随机森林。
随机森林在scikit-learn中的实现最棒的特性是n_jobs参数。这将会基于你想使用的核数自动地并行设置随机森林。这里是scikit-learn的贡献者Olivier Grisel的一个很棒的报告,在这个报告中他谈论了使用20个节点的EC2集群训练随机森林。
01 |
from sklearn.datasets import load_iris |
02 |
from sklearn.ensemble import RandomForestClassifier |
03 |
import pandas as pd |
04 |
import numpy as np |
05 |
|
06 |
iris = load_iris() |
07 |
df = pd.DataFrame(iris.data, columns=iris.feature_names) |
08 |
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75 |
09 |
df['species'] = pd.Factor(iris.target, iris.target_names) |
10 |
df.head() |
11 |
|
12 |
train, test = df[df['is_train']==True], df[df['is_train']==False] |
13 |
|
14 |
features = df.columns[:4] |
15 |
clf = RandomForestClassifier(n_jobs=2) |
16 |
y, _ = pd.factorize(train['species']) |
17 |
clf.fit(train[features], y) |
18 |
|
19 |
preds = iris.target_names[clf.predict(test[features])] |
20 |
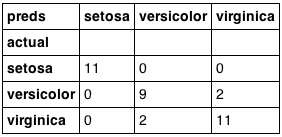
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds']) |
看起来很不错!
结语
随机森林相当容易使用,而且很强大。对于任何建模,都要注意过拟合。如果你有兴趣用R语言开始使用随机森林,那么就签出randomForest包。
本文地址:http://www.oschina.net/translate/random-forests-in-python
原文地址:http://blog.yhathq.com/posts/random-forests-in-python.html
Python 实现的随机森林的更多相关文章
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- Python数据挖掘之随机森林
主要是使用随机森林将four列缺失的数据补齐. # fit到RandomForestRegressor之中,n_estimators代表随机森林中的决策树数量 #n_jobs这个参数告诉引擎有多少处理 ...
- 随机森林入门攻略(内含R、Python代码)
随机森林入门攻略(内含R.Python代码) 简介 近年来,随机森林模型在界内的关注度与受欢迎程度有着显著的提升,这多半归功于它可以快速地被应用到几乎任何的数据科学问题中去,从而使人们能够高效快捷地获 ...
- 如何在Python中从零开始实现随机森林
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 决策树可能会受到高度变异的影响,使得结果对所使用的特定测试数据而言变得脆弱. 根据您的测试数据样本构建多个模型(称为套袋)可以减少这种差异,但是 ...
- Python中随机森林的实现与解释
使用像Scikit-Learn这样的库,现在很容易在Python中实现数百种机器学习算法.这很容易,我们通常不需要任何关于模型如何工作的潜在知识来使用它.虽然不需要了解所有细节,但了解机器学习模型是如 ...
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
随机推荐
- VS2015企业版和专业版永久密匙
专业版:HMGNV-WCYXV-X7G9W-YCX63-B98R2企业版:HM6NR-QXX7C-DFW2Y-8B82K-WTYJV
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- node.js的fs核心模块读写文件操作 -----由浅入深
node.js 里fs模块 常用的功能 实现文件的读写 目录的操作 - 同步和异步共存 ,有异步不用同步 - fs.readFile 都不能读取比运行内存大的文件,如果文件偏大也不会使用readFil ...
- Apple公司开发者账号申请(2017包含邓白氏码申请)
1.首先看需要那种账号 2.这个需要的是公司开发者账号,首先我们注册一个普通apple账号 打开网址 https://developer.apple.com 进入点击Account 进入登录页面,点击 ...
- 从聚合数据请求菜谱大全接口数据,解析显示到ListView
- 微信小程序view标签以及display:flex的测试
一:testview.wxml,testview.js自动生成示例代码 //testview.wxml <view class="section"> <view ...
- 【Beta】Daily Scrum Meeting——Day5
站立式会议照片 1.本次会议为第五次Meeting会议: 2.本次会议在早上9:35,在陆大2楼机房召开,本次会议为25分钟讨论今天要完成的任务以及接下来的任务安排. 燃尽图 每个人的工作分配 成 员 ...
- 201521123016 《Java程序设计》第8周学习总结
1. 本周学习总结 2. 书面作业 本次作业题集集合 1.List中指定元素的删除(题目4-1) 1.1 实验总结 1.删除元素的时候从最后一个元素开始,避免删除元素后位置发生变化而导致有些元素没有删 ...
- 201521123006 《Java程序设计》第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 本周除了继承,我们还重点学习了多态. (1)多态性在于有相同的形态,却是不同的行为或者说是不 ...
- 201521123116 《java程序设计》第十周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 Q1 finally 题目4-2 1.1 截图你的提交结果(出现学号) 1.2 4-2中fi ...