spark (二) spark wordCount示例
实现思路
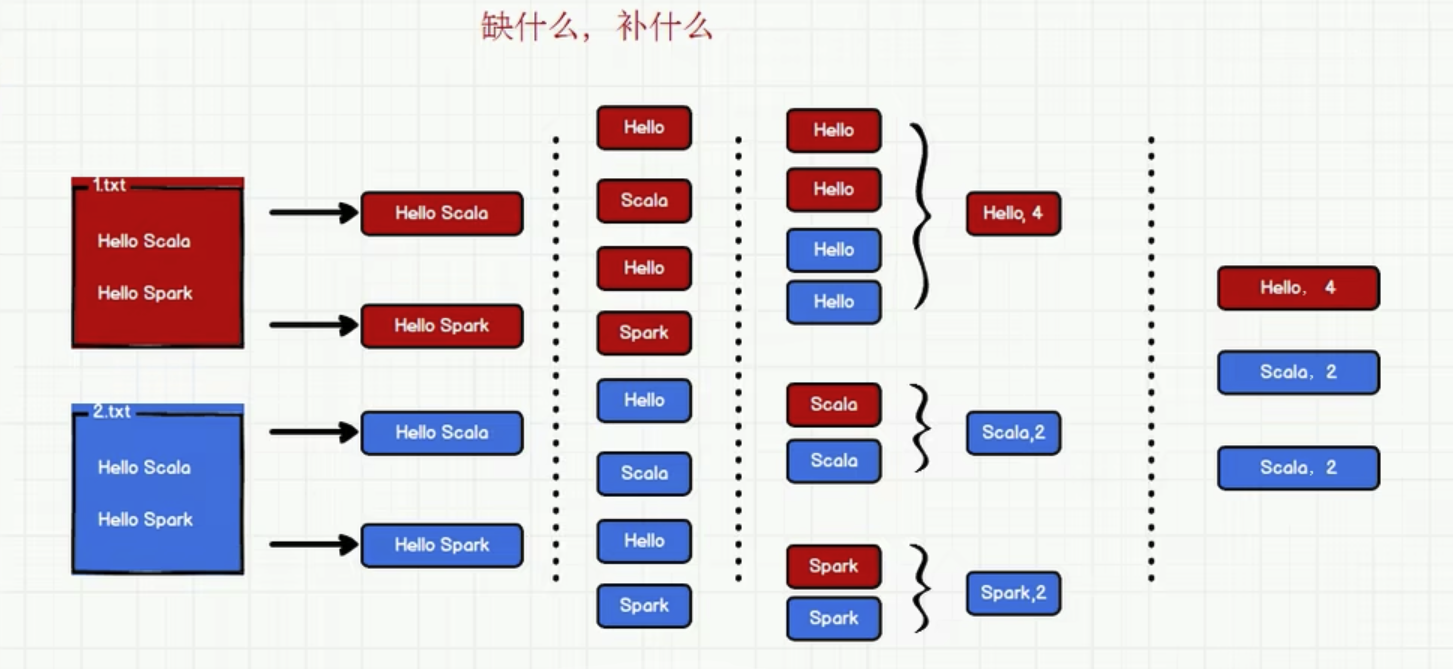
实现1: scala 基本集合操作方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
words.foreach(println)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
val x = 1
// 2.3 将数据根据单词进行分组,便于统计
val wordToCount: RDD[(String, Int)] = wordGroup.map({
case (word, list) => (word, list.size)
})
val tuples: Array[(String, Int)] = wordToCount.collect()
// 2.4 打印结果
tuples.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
实现2: scala map reduce方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
// lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// 分组
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(t => t._1)
// 聚合
val tuple: RDD[(String, Int)] = wordGroup.map({
case (word, list) => list.reduce((t1, t2) => (t1._1, t1._2 + t2._2))
})
tuple.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
实现3: spark 提供的map reduce方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
// lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// 相同的key会对value做reduce
val tuple: RDD[(String, Int)] = wordToOne.reduceByKey((t1, t2) => t1 + t2)
tuple.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
FAQ:
Q: 初步运行spark错误
A: JDK版本问题, 切换jdk到1.8就可以了
spark (二) spark wordCount示例的更多相关文章
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- Spark练习之wordcount,基于排序机制的wordcount
Spark练习之wordcount 一.原理及其剖析 二.pom.xml 三.使用Java进行spark的wordcount练习 四.使用scala进行spark的wordcount练习 五.基于排序 ...
- Spark metrics on wordcount example
I read the section Metrics on spark website. I wish to try it on the wordcount example, I can't make ...
- openfire spark 二次 开发 服务插件
==================== 废话 begin ============================ 最近老大让我为研发平台增加即时通讯功能.告诉我用comet 在web端实现即 ...
- PC结束 Spark 二次开发 收到自己主动,并允许好友请求
本次Spark二次开发是为了客服模块的开发, 能让用户一旦点击该客服则直接自己主动加入好友.而客服放则需自己主动加入好友,不同弹出对话框进行允许,这方便的广大客服. 如今废话不多说,直接上代码. pa ...
- Spark:使用Spark Shell的两个示例
Spark:使用Spark Shell的两个示例 Python 行数统计 ** 注意: **使用的是Hadoop的HDFS作为持久层,需要先配置Hadoop 命令行代码 # pyspark >& ...
- Spark初步 从wordcount开始
Spark初步-从wordcount开始 spark中自带的example,有一个wordcount例子,我们逐步分析wordcount代码,开始我们的spark之旅. 准备工作 把README.md ...
- 运行spark官方的graphx 示例 ComprehensiveExample.scala报错解决
运行spark官方的graphx 示例 ComprehensiveExample.scala报错解决 在Idea中,直接运行ComprehensiveExample.scala,报需要指定master ...
- Spark安装和简单示例
spark的安装 先到官网下载安装包 注意第二项要选择和自己hadoop版本相匹配的spark版本,然后在第4项点击下载.若无图形界面,可用windows系统下载完成后传送到centos中. 本例中安 ...
- 配置spark历史服务(spark二)
1. 编辑spark-defaults.conf位置文件 添加spark.eventLog.enabled和spark.eventLog.dir的配置修改spark.eventLog.dir为我们之前 ...
随机推荐
- C++新版本特性
C++新特性 1.C++11 中的新特性 C++11 引入了许多新特性,包括自动类型推导.lambda 表达式.右值引用等.下面介绍其中的一些重要特性. 1.1 自动类型推导(Type Inferen ...
- 轻量级网络-ShuffleNetv2 论文解读
摘要 1.介绍 2.高效网络设计的实用指导思想 G1-同样大小的通道数可以最小化 MAC G2-分组数太多的卷积会增加 MAC G3-网络碎片化会降低并行度 G4-逐元素的操作不可忽视 3.Shuff ...
- 蚂蚁图团队GraphRAG支持社区摘要——Token相比微软直降50%
今年5月份,我们在DB-GPT v0.5.6版本发布了蚂蚁首个开源GraphRAG框架,支持了多种知识库索引底座,并在文章<Vector | Graph:蚂蚁首个开源GraphRAG框架设计解读 ...
- 怎样替换 rhel 7.3 的 yum
[背景] 想在自己安装的虚拟机上搭建一套 git+gitee+vscode 环境(欢迎看下期文章),发现python版本是2.7,这个版本太老 想通过yum进行更新,结果提示需要注册,索性就查查替换y ...
- esp8266+MQTT+DHT11(温湿度计) platformio
esp8266 + MQTT + DHT11(温湿度计) 连线 #include <Arduino.h> #include <ESP8266WiFi.h> #include & ...
- C221027B
B 抽 \(n\) 次卡, 连续 \(i\) 次没有抽中时, 第 \(i+1\) 次抽中的概率是 \(p_i\), 规定\(p_k=1\), 求期望抽中次数. 标签:矩阵加速递推, 动态规划. 暴力: ...
- 狗的名字 ATCOER-ABC-171-C One Quadrillion and One Dalmatians
狗的名字 ATCOER-ABC-171-C One Quadrillion and One Dalmatians 题目链接 我们可以将名字看成26进制的数,就可以转化为将一个10进制转26进制的数的问 ...
- linux history 想显示历史命令的时间和作者
vi ~/.profile 增加 HISTTIMEFORMAT="%F %T `whoami` `who am i|awk '{print $1,$5}'|sed 's/ (/@/'|sed ...
- (Redis基础教程之十) 如何在Redis中运行事务
介绍 Redis是一个开源的内存中键值数据存储.Redis允许您计划一系列命令,然后一个接一个地运行它们,这一过程称为_transaction_.每个事务都被视为不间断且隔离的操作,以确保数据完整性. ...
- 使用 JsonSchema 校验 JSON数据
有时候JSON 数据格式需要校验是否合法,我们可以使用 JsonSchema 来校验数据是否合法. 引入 pom.xml https://json-schema.org/ <dependency ...