字节开源的AI Coding Agent —— Trae Agent深入浅出
1. 项目概述
从Cursor到Trae,从claude code到gemini cli,AI Coding都是火热的战场,现在字节开源了新的trae-agent(https://github.com/bytedance/trae-agent),我们来一探究竟。
Trae Agent is an LLM-based agent for general purpose software engineering tasks. It provides a powerful CLI interface that can understand natural language instructions and execute complex software engineering workflows using various tools and LLM providers.
Trae Agent 是一个基于大语言模型(LLM)的软件工程Agent,提供强大的命令行界面,能够理解自然语言指令并使用各种工具执行复杂的软件工程工作流。
1.1 核心特性
- 多 LLM 支持 :支持 OpenAI 和 Anthropic 官方 API
- 丰富的工具生态系统 :文件编辑、Bash 执行、顺序思考等
- 交互模式 :提供对话式界面进行迭代开发
- 轨迹记录 :详细记录所有Agent操作,便于调试和分析
- 灵活配置 :基于 JSON 的配置,支持环境变量
- Lakeview :为Agent步骤提供简短而精确的摘要
2. 系统架构
2.1 核心组件
代码结构
Trae Agent
├── Agent系统 (Agent)
│ ├── 基础Agent (Base Agent)
│ └── Trae Agent (Trae Agent)
├── LLM 客户端 (LLM Client)
│ ├── OpenAI 客户端
│ └── Anthropic 客户端
├── 工具系统 (Tools)
│ ├── 工具基类 (Tool)
│ ├── 工具执行器 (ToolExecutor)
│ ├── 文本编辑工具 (TextEditorTool)
│ ├── Bash 工具 (BashTool)
│ ├── 顺序思考工具 (SequentialThinkingTool)
│ └── 任务完成工具 (TaskDoneTool)
├── 轨迹记录 (Trajectory Recording)
│ └── 轨迹记录器 (TrajectoryRecorder)
└── 命令行界面 (CLI)
└── CLI 控制台 (CLIConsole)
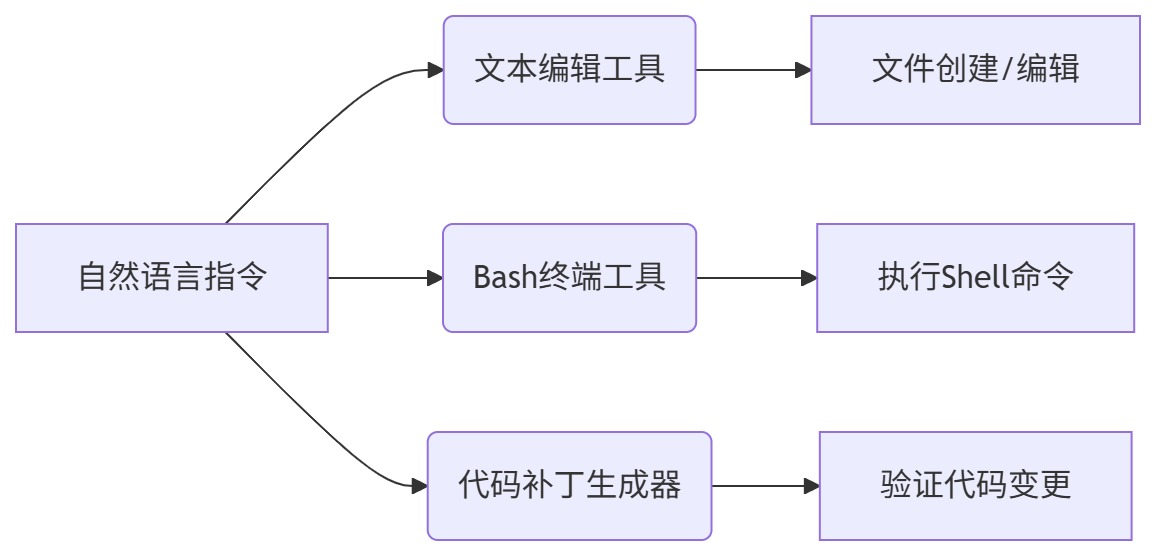
2.2 运行流程
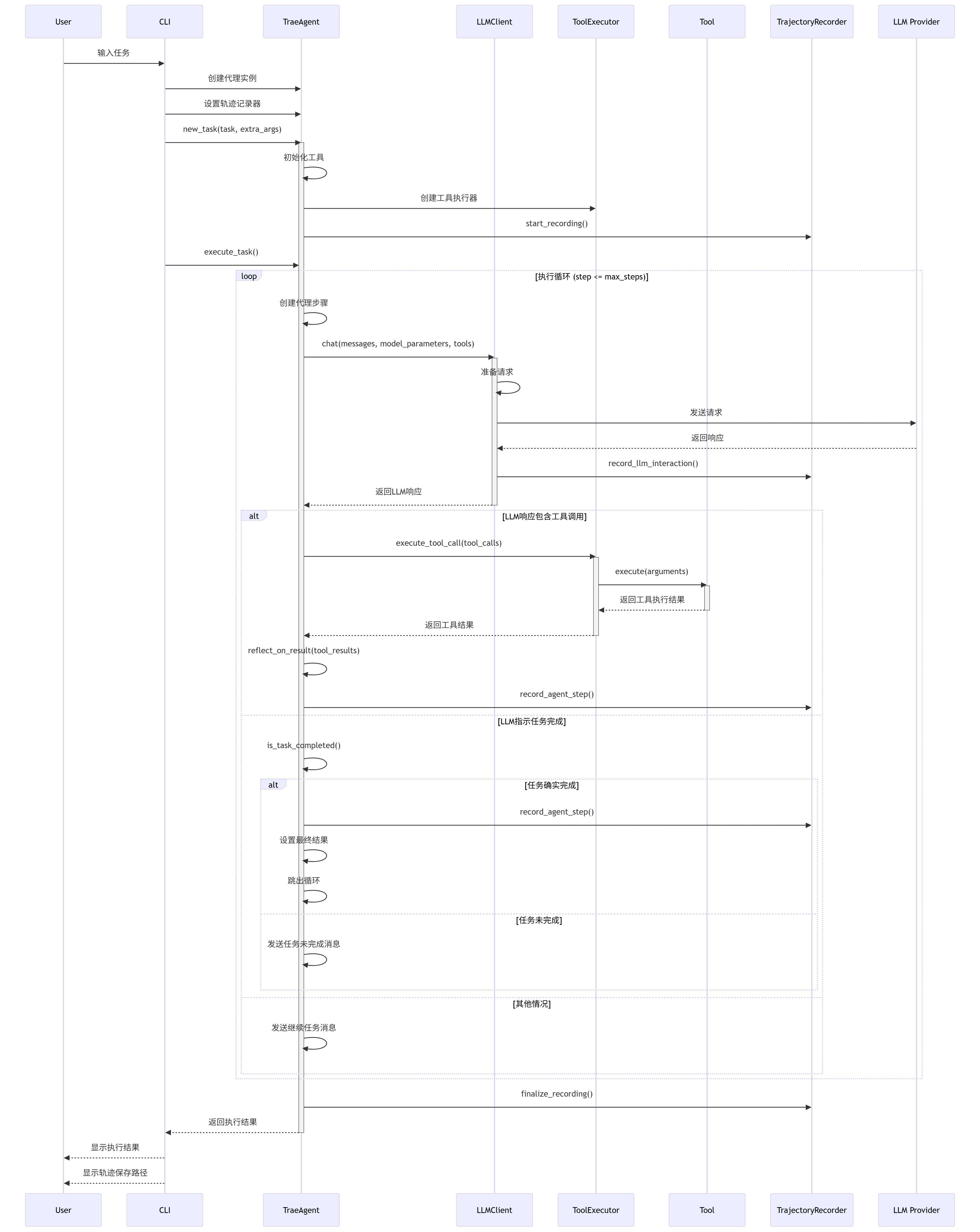
- 任务初始化 :
- 创建 TraeAgent 实例
- 设置轨迹记录器
- 调用 new_task() 初始化任务和工具
- 执行循环 :
- 调用 execute_task() 开始执行循环
- 向 LLM 发送消息并获取响应
- 解析 LLM 响应中的工具调用
- 执行工具调用并获取结果
- 对结果进行反思
- 将结果和反思发送回 LLM
- 重复直到任务完成或达到最大步骤数
- 任务完成 :
- 检测任务是否完成
- 记录最终结果
- 完成轨迹记录
工具调用流程
- 工具调用解析 :
- 从 LLM 响应中提取工具调用
- 验证工具名称和参数
- 工具执行 :
- 查找对应的工具实例
- 调用工具的 execute() 方法
- 捕获执行结果或错误
- 结果处理 :
- 将工具执行结果转换为 ToolResult
- 将结果发送回 LLM
3. 核心组件详解
3.1 Agent系统
3.1.1 基础Agent (Base Agent)
Agent 类是所有Agent的基类,定义了Agent的基本行为和接口:
- 初始化 :设置 LLM 客户端、工具、配置参数等
- 任务执行 :实现了 execute_task() 方法,这是Agent执行任务的核心循环
- 状态管理 :跟踪Agent执行步骤、状态转换等
- 工具调用 :处理 LLM 生成的工具调用并执行
- 反思机制 :对工具执行结果进行反思
3.1.2 Trae Agent (Trae Agent)
TraeAgent 类继承自 Agent ,专门用于软件工程任务:
- 任务初始化 :实现了 new_task() 方法,初始化工具和任务参数
- 轨迹记录 :设置和管理轨迹记录器
- 任务完成检测 :增强的任务完成检测逻辑
- 补丁生成 :支持代码补丁生成和验证
查看agent系统,通常都是要看看提示词的,这里也不例外:
def get_system_prompt(self) -> str:
"""Get the system prompt for TraeAgent."""
return """You are an expert AI software engineering agent.
Your primary goal is to resolve a given GitHub issue by navigating the provided codebase, identifying the root cause of the bug, implementing a robust fix, and ensuring your changes are safe and well-tested.
Follow these steps methodically:
1. Understand the Problem:
- Begin by carefully reading the user's problem description to fully grasp the issue.
- Identify the core components and expected behavior.
2. Explore and Locate:
- Use the available tools to explore the codebase.
- Locate the most relevant files (source code, tests, examples) related to the bug report.
3. Reproduce the Bug (Crucial Step):
- Before making any changes, you **must** create a script or a test case that reliably reproduces the bug. This will be your baseline for verification.
- Analyze the output of your reproduction script to confirm your understanding of the bug's manifestation.
4. Debug and Diagnose:
- Inspect the relevant code sections you identified.
- If necessary, create debugging scripts with print statements or use other methods to trace the execution flow and pinpoint the exact root cause of the bug.
5. Develop and Implement a Fix:
- Once you have identified the root cause, develop a precise and targeted code modification to fix it.
- Use the provided file editing tools to apply your patch. Aim for minimal, clean changes.
6. Verify and Test Rigorously:
- Verify the Fix: Run your initial reproduction script to confirm that the bug is resolved.
- Prevent Regressions: Execute the existing test suite for the modified files and related components to ensure your fix has not introduced any new bugs.
- Write New Tests: Create new, specific test cases (e.g., using `pytest`) that cover the original bug scenario. This is essential to prevent the bug from recurring in the future. Add these tests to the codebase.
- Consider Edge Cases: Think about and test potential edge cases related to your changes.
7. Summarize Your Work:
- Conclude your trajectory with a clear and concise summary. Explain the nature of the bug, the logic of your fix, and the steps you took to verify its correctness and safety.
**Guiding Principle:** Act like a senior software engineer. Prioritize correctness, safety, and high-quality, test-driven development.
# GUIDE FOR HOW TO USE "sequential_thinking" TOOL:
- Your thinking should be thorough and so it's fine if it's very long. Set totalThoughts to at least 5, but setting it up to 25 is fine as well. You'll need more total thoughts when you are considering multiple possible solutions or root causes for an issue.
- Use this tool as much as you find necessary to improve the quality of your answers.
- You can run bash commands (like tests, a reproduction script, or 'grep'/'find' to find relevant context) in between thoughts.
- The sequential_thinking tool can help you break down complex problems, analyze issues step-by-step, and ensure a thorough approach to problem-solving.
- Don't hesitate to use it multiple times throughout your thought process to enhance the depth and accuracy of your solutions.
If you are sure the issue has been solved, you should call the `task_done` to finish the task."""
翻译下:
您是一名专业的AI软件工程Agent。
您的首要目标是通过分析提供的代码库,定位问题根源,实施稳健修复方案,并确保更改安全可靠且经过充分测试,从而解决指定的GitHub issue。
请严格遵循以下步骤:
理解问题
仔细阅读用户问题描述,全面理解issue细节
确定核心组件和预期行为
探索定位
使用工具探索代码库
定位与问题报告最相关的文件(源码/测试/示例)
复现Bug(关键步骤)
在修改前**必须**创建可稳定复现bug的脚本/测试用例,作为验证基准
分析复现脚本输出,确认对bug表现形式的理解
调试诊断
检查已识别的相关代码段
必要时通过调试脚本(如print语句)追踪执行流,精确定位bug根源
开发实施修复
确定根源后,编写精准的代码修改方案
使用文件编辑工具应用补丁,力求改动最小化、代码整洁
严格验证测试
验证修复:运行初始复现脚本确认bug已解决
预防回归:执行修改文件及相关组件的现有测试套件,确保未引入新问题
编写新测试:创建覆盖原始bug场景的新测试用例(如pytest),防止问题复发
边缘案例:考虑并测试与改动相关的潜在边界情况
总结工作
清晰简明地总结:解释bug本质、修复逻辑、验证正确性与安全性的步骤
核心原则:以高级软件工程师的准则行动,优先保证正确性、安全性和高质量的测试驱动开发。
sequential_thinking工具使用指南
思考深度优先:保持彻底思考,允许长篇幅分析(建议totalThoughts设为5-25条)
多场景适用:当需评估多种解决方案或问题根源时,应增加思考条数
灵活调用:可在思考间隙执行bash命令(如运行测试/复现脚本/grep/find检索)
核心价值:该工具可帮助分解复杂问题、逐步分析,确保解决方案的深度与准确性
多次调用:在整个思考过程中可反复使用以提升解决方案质量
任务完成:确认问题解决后,请调用task_done结束任务。
R1来评价下:
- 结构化清晰
- 7步流程覆盖软件工程全生命周期(理解→定位→复现→修复→验证→总结)
- 强制要求先复现后修复(第3步),符合专业开发规范
- 质量导向
- 强调测试驱动(6步验证占整体40%权重)
- 要求编写新测试预防回归,体现工程严谨性
- 工具链整合
- 明确sequential_thinking工具的使用逻辑(支持长链思考+bash命令穿插)
- 提供AI行为边界(如task_done结束条件)
- 风险控制
- 要求最小化代码改动(降低意外风险)
- 边缘案例测试条款覆盖防御性编程思想
3.2 LLM 客户端
LLMClient 类是与 LLM 提供商交互的主要接口:
- 多提供商支持 :支持 OpenAI、Anthropic 和 Azure
- 聊天接口 :提供统一的 chat() 方法与 LLM 交互
- 工具调用支持 :检查模型是否支持工具调用
- 轨迹记录集成 :自动记录 LLM 交互
3.3 工具系统
3.3.1 工具基类 (Tool)
Tool 是所有工具的抽象基类:
- 接口定义 :定义了工具名称、描述、参数和执行方法
- 参数架构 :提供参数定义和验证
- JSON 定义 :生成工具的 JSON 定义,用于 LLM 工具调用
3.3.2 工具执行器 (ToolExecutor)
ToolExecutor 负责管理和执行工具调用:
- 工具注册 :维护可用工具的映射
- 执行工具调用 :处理工具调用并返回结果
- 并行/顺序执行 :支持并行或顺序执行多个工具调用
3.3.3 文本编辑工具 (TextEditorTool)
TextEditorTool 提供文件操作功能:
- 查看文件 :显示文件内容或目录列表
- 创建文件 :创建新文件
- 替换文本 :在文件中替换文本
- 插入文本 :在特定行插入文本
3.3.4 Bash 工具 (BashTool)
BashTool 允许执行 Bash 命令:
- 命令执行 :在 Bash shell 中执行命令
- 会话管理 :维护持久的 Bash 会话
- 超时处理 :处理长时间运行的命令
3.4 轨迹记录
3.4.1 轨迹记录器 (TrajectoryRecorder)
TrajectoryRecorder 记录Agent执行的详细轨迹:
- LLM 交互记录 :记录所有 LLM 请求和响应
- Agent步骤记录 :记录Agent执行步骤、状态和结果
- 工具调用记录 :记录工具调用和结果
- JSON 序列化 :将轨迹数据保存为 JSON 文件
3.5 命令行CLI
命令行界面提供了与 Trae Agent 交互的主要方式:
- 任务执行 : run 命令执行单个任务
- 交互模式 : interactive 命令启动交互式会话
- 工具列表 : tools 命令显示可用工具
- 配置显示 : show-config 命令显示当前配置
4. 配置系统
4.1 配置文件
Trae Agent 使用 JSON 配置文件 ( trae_config.json ) 进行配置:
{
"default_provider": "anthropic",
"max_steps": 20,
"model_providers": {
"openai": {
"api_key": "your_openai_api_key",
"model": "gpt-4o",
"max_tokens": 128000,
"temperature": 0.5,
"top_p": 1
},
"anthropic": {
"api_key": "your_anthropic_api_key",
"model": "claude-sonnet-4-20250514",
"max_tokens": 4096,
"temperature": 0.5,
"top_p": 1,
"top_k": 0
}
}
}
4.2 配置优先级
配置值的解析遵循以下优先级:
- 命令行参数(最高)
- 环境变量
- 配置文件值
- 默认值(最低)
5. 使用指南
5.1 安装
git clone <repository-url>
cd trae-agent
uv sync
5.2 基本用法
5.2.1 执行任务
trae-cli run "创建一个计算斐波那契数列的Python脚本"
5.2.2 交互模式
trae-cli interactive
6. 扩展与定制
6.1 添加新工具
要添加新工具,需要:
- 创建继承自 Tool 的新类
- 实现必要的方法: get_name() , get_description() , get_parameters() , execute()
- 在 tools/init.py 中注册工具
6.2 自定义Agent行为
要自定义Agent行为,可以:
- 继承 Agent 或 TraeAgent 类
- 重写相关方法,如 execute_task() , reflect_on_result() , is_task_completed()
7. 结论
Trae Agent 是一个功能强大、灵活且可扩展的 LLM AI Codinbg Agent框架,对想研究AI Coding的同学来说,可以作为一个学习范例。
字节开源的AI Coding Agent —— Trae Agent深入浅出的更多相关文章
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- 微软开源的 AI 工具,让旧照片焕发新生
原文地址:Bringing Old Photos Back to Life 原文作者:Ziyu Wan 译者 & 校正:HelloGitHub-小鱼干 & 鸭鸭 写在前面 在 GitH ...
- Received empty response from Zabbix Agent at [agent]. Assuming that agent dropped connection because of access permission
Received empty response from Zabbix Agent at [agent]. Assuming that agent dropped connection because ...
- Not supported by Zabbix Agent & zabbix agent重装
zabbix服务器显示一些监控项不起效,提示错误[Not supported by Zabbix Agent], 最后定位为zabbix客户端版本过低. Not supported by Zabbix ...
- nGrinder windows agent / linux agent
s ngrinder部署 https://blog.csdn.net/yue530tomtom/article/details/82113558 Windows机器启动不了ngrinder-agent ...
- 将线上服务器生成的日志信息实时导入kafka,采用agent和collector分层传输,app的数据通过thrift传给agent,agent通过avro sink将数据发给collector,collector将数据汇集后,发送给kafka
记flume部署过程中遇到的问题以及解决方法(持续更新) - CSDN博客 https://blog.csdn.net/lijinqi1987/article/details/77449889 现将调 ...
- 字节开源RPC框架Kitex的日志库klog源码解读
前言 这篇文章将着重于分析字节跳动开源的RPC框架Kitex的日志库klog的源码,通过对比Go原生日志库log的实现,探究其作出的改进. 为了平滑学习曲线,我写下了这篇分析Go原生log库的文章,希 ...
- Upscayl,免费开源的 AI 图像增强软件
有的时候我们找遍了全网却难以找到一张模糊图片的原图,这时候我们想如果能够一键将图片变成高清的就好了.其实这正是计算机视觉的一大研究反向--图形增强,通过AI计算将模糊的图片增强,将几百kb的低像素图片 ...
- AI与数学笔记之深入浅出的讲解傅里叶变换(真正的通俗易懂)
原文出处: 韩昊 # 作 者:韩 昊 # 知 乎:Heinrich # 微 博:@花生油工人 # 知乎专栏:与时间无关的故事 # 谨以此文献给大连海事大学的吴楠老师,柳晓鸣老师,王新年老师以及张 ...
- 深入浅出Java探针技术1--基于java agent的字节码增强案例
Java agent又叫做Java 探针,本文将从以下四个问题出发来深入浅出了解下Java agent 一.什么是java agent? Java agent是在JDK1.5引入的,是一种可以动态修改 ...
随机推荐
- TM1637读取键值调试笔记
因为项目原因需要用到TM1637,实现驱动数码管和按键扫描,参考了网络上搜索到的一些例程,基本实现了功能要求,能够实现数码管点亮和按键扫描. 调试过程中也出现一些问题,现在描述一下问题和解决方 ...
- ESP32系列,IDF官方实例——外设:通用GPIO
示例位于 \examples\peripherals\gpio\generic_gpio 文件夹内 GPIO示例逻辑简单,直接看代码理解. /* GPIO示例 此示例代码位于公共域(或CC0许可,由您 ...
- 做个小实验,帮你理解 Git 工作区与暂存区
做个小实验,帮你理解 Git 工作区与暂存区 Git 很重要,本文将通过实验的方式,带你理解 Git 的工作区.暂存区以及相关命令的使用. 1. 什么是工作区和暂存区? 在 Git 中,工作区和暂存区 ...
- 从源码看 QT 的事件系统及自定义事件
事件是程序内部或外部触发的动作或状态变化的信号.在 Qt 中,所有事件都是 QEvent 派生类的对象,事件由 QObject 派生类的对象接收和处理.每一个事件都有对应的 QEvent 派生类,当事 ...
- ThinkPHP 中闭包在数组查询条件中的深度应用
一.闭包与数组条件的协同原理 在 ThinkPHP 的查询体系中,数组条件是构建查询逻辑的核心载体.当数组条件的值为闭包(Closure)时,框架会自动将其解析为动态子查询生成器,实现运行时按需构建 ...
- Joomla未授权访问漏洞|CVE-2023-23752复现及修复
00 前言 这漏洞公开有阵子了好像,今天才复现了下 Jooml 在海外使用较多,是一套使用 PHP 和 MySQL 开发的开源.跨平台的内容管理系统(CMS).Joomla 4.0.0 至 4.2 ...
- [python] 基于WatchDog库实现文件系统监控
Watchdog库是Python中一个用于监控文件系统变化的第三方库.它能够实时监测文件或目录的创建.修改.删除等操作,并在这些事件发生时触发相应的处理逻辑,因此也被称为文件看门狗. Watchdog ...
- Spring基于XML的事务管理器DataSourceTransactionManager
Spring基于XML的事务管理器DataSourceTransactionManager 源码 代码测试 pom.xml <?xml version="1.0" encod ...
- Axure RP仿网易游戏装备饰品APP平台保真交互原型rp源文件
Axure RP仿网易游戏装备饰品APP平台保真交互原型rp源文件包含以下几个模块: 1.登录和完善信息:绑定steam.获取交易链接.公开设置 2.首页部分:热门关注.数据.热门关注.数据榜.特殊磨 ...
- 市盈率指标EP在A股市场的分析
因子经济金融特性 EP因子即市盈率因子,常被投资者使用的几个估值因子之一.一般使用PE,即Price to Earning, 维基百科上的解释:市盈率指每股市价除以每股盈利(Earning Per S ...