当我们在聊「开源大数据调度系统Taier」的数据开发功能时,到底在讨论什么?
原文链接:当我们在聊「开源大数据调度系统Taier」的数据开发功能时,到底在讨论什么?
课件获取:关注公众号__ “数栈研习社”,后台私信 “Taier”__ 获得直播课件
视频回放:点击这里
Taier 开源项目地址:github 丨gitee喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下摘月同学的直播分享《Taier数据开发介绍》
之前三期内容,我们为大家分享了Taier入门、控制台以及Web前端架构的介绍。本次分享我们将从Taier的数据开发功能,到任务运行、功能可扩展点以及未来规划为大家进行讲解。
一、数据开发功能介绍
Taier 是袋鼠云开源项目之一,是一个分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,Taier的数据开发功能主要分为以下三种:
1、资源管理
资源管理通常使用在UDF等自定义函数的场景中,也可以在任务开发中使用。在Taier中,对于函数引用,主要用在Spark、Flink自定义函数中,而在任务引用中,则主要用于Flink任务。

2、函数管理
自定义函数处理流程如下图所示:
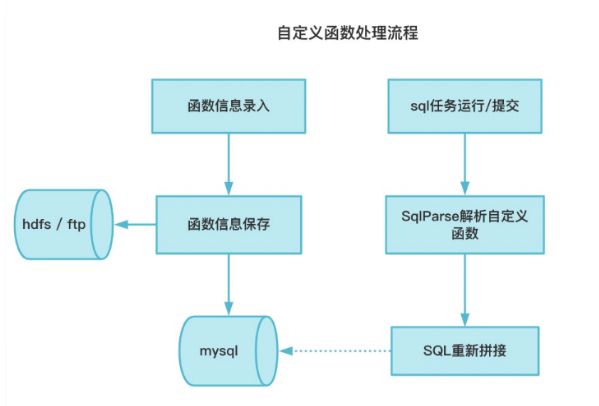
函数管理在Taier中的具体实现主要包括以下两个方面:
基于calcite完成不同数据源SQL自定义函数解析
使用SQL运行前创建临时函数替代创建永久函数,使函数使用更加灵活
3、任务管理
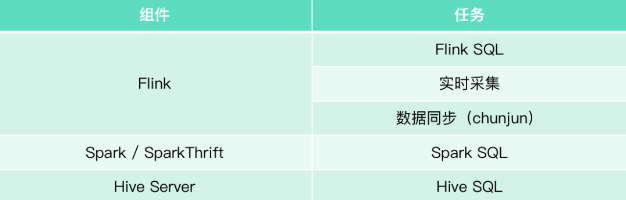
Taier现支持任务:Flink SQL、实时采集、数据同步(ChunJun)、Spark SQL、HiveSQL
Taier中有两块区分,分别为集群和数据开发,如果想在Taier中跑一个任务,需要先在集群中进行配置,具体组件与任务关系如下图:
二、Taier任务运行讲解
了解完Taier数据开发的功能介绍后,我们来为大家分享Taier的任务运行逻辑。
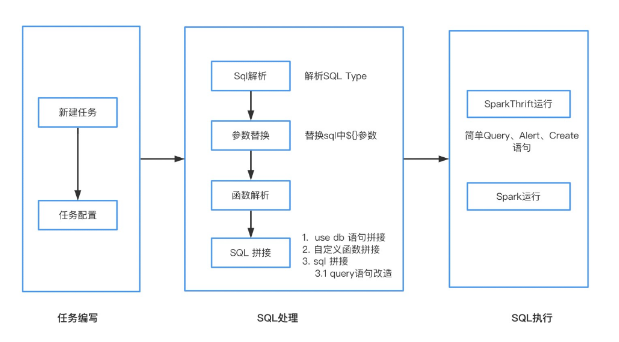
1、Spark Sql、Hive Sql临时运行流程
Spark Sql、Hive Sql 临时运行流程主要分为任务编写、SQL处理、SQL执行三步,以下图为SparkSql执行流程:
2、Spark Sql 、Hive Sql 运行依赖
Spark Sql 、Hive Sql 运行依赖主要包括以下两类:
● Sql解析(基于calcite进行)
· Sql Type 解析
· 函数、表名解析
● 数据源插件
· 统一不同数据源操作入口
· 封装数据源对应的数据操作方法
三、功能可扩展点介绍
当前而言,Taier中的功能还较为简单,只开放了主要流程的功能,在开源中还有许多可扩展点,接下来为大家介绍Taier的功能可扩展点。
1、功能扩展——数据权限控制
在sparkThrift、hiveserver中去进行create、insert into、alter、select时,不同的公司、不同的人有不一样的数据权限控制,面对这种情况,可以利用Apache Ranger大数据权限管理框架进行权限配置。
具体地址为:
github:https://github.com/ranger/ranger
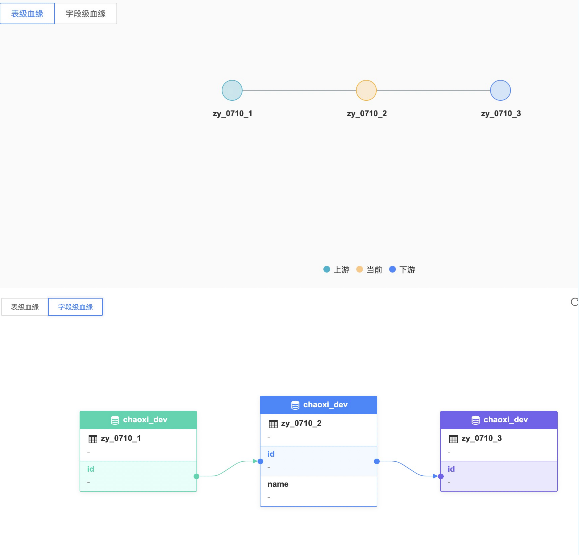
2、功能扩展——数据血源追踪
通过SQL解析可以得到表和表之间的关系,以及不同表中字段之间的血源关系。
● 实现工具:calcite
● 可操作任务:SparkSql、HiveSql、数据同步(ChunJun)
用sql举例:
create table zy_0710_1 (id int, name string);
create table zy_0710_2 as select id , name from zy_0710_1;
create table zy_0710_3 as select id , name from zy_0710_2;
四、Taier1.2尝鲜
最后为大家介绍未来不久将发布的Taier1.2新版本尝鲜:
●集群管理
控制台ui升级
● 数据开发
集群租户绑定流程简化
任务开发代码层面优化
任务新增schema配置
● 新增功能
FlinkSql支持jar包方式
新增工作流任务
自定义扩展开发任务
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
当我们在聊「开源大数据调度系统Taier」的数据开发功能时,到底在讨论什么?的更多相关文章
- 「产品经理全连接系列1」Epic/Feature/Story/Task/Bug到底是什么
大家好,我是华为云的产品经理 恒少: 作为布道师和产品经理,出差各地接触客户是常态,经常和华为云的客户交流.布道.技术沙龙,但是线下交流,覆盖的用户总还是少数. 我希望可以借线上的平台,和用户持续交流 ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 假设一个大小为100亿个数据的数组,该数组是从小到大排好序的,现在该数组分成若干段,每个段的数据长度小于20「也就是说:题目并没有说每段数据的size 相同,只是说每个段的 size < 20 而已」
假设一个大小为100亿个数据的数组,该数组是从小到大排好序的,现在该数组分成若干段,每个段的数据长度小于20「也就是说:题目并没有说每段数据的size 相同,只是说每个段的 size < 20 ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- 开源大数据引擎:Greenplum 数据库架构分析
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库.商务智能(OLAP)和数据挖掘等.自2015年10月正式开源以来,受到国内外业内人士的广泛关注 ...
- 《开源大数据分析引擎Impala实战》目录
当当网图书信息: http://product.dangdang.com/23648533.html <开源大数据分析引擎Impala实战>目录 第1章 Impala概述.安装与配置.. ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
随机推荐
- 数据质量框架QUalitis浅尝使用
数据质量管理平台(微众银行)Qualitis+Linkis (一)Qualitis是一个数据质量管理系统,用于监控数据质量. 其功能包括: 数据质量模型定义 数据质量结果可视化 可监控 数据质量管理服 ...
- 一步一步教你部署ktransformers,大内存单显卡用上Deepseek-R1
环境准备 硬件环境 CPU:intel四代至强及以上,AMD参考同时期产品 内存:800GB以上,内存性能越强越好,建议DDR5起步 显卡:Nvidia显卡,单卡显存至少24GB(用T4-16GB显卡 ...
- 为什么不建议通过Executors构建线程池
Executors类看起来功能还是比较强大的,又用到了工厂模式.又有比较强的扩展性,重要的是用起来还比较方便,如: ExecutorService executor = Executors.newFi ...
- BUUCTF---Cipher1(playfair)
playfair Playfair密码原理以及该题解题步骤 Playfair密码(Playfair cipher 或 Playfair square)一种替换密码,1854年由查尔斯·惠斯通(Char ...
- [每日算法 - 华为机试] leetcode463. 岛屿的周长
入口 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer.https://le ...
- mybatis-plus.global-config.db-config.id-type=auto 和 @TableId(value = "id", type = IdType.ASSIGN_ID)哪个优先生效
对于id自动生成的方式,有注解和配置两种. 含义相同:不过设置自动增长的时候必须保证数据库中id是自增,assign_id和assign_uuid则不需要. yml配置: mybatis-plus: ...
- elemengui分页
<!-- 分页模块 --> <template> <div class="block" style="margin-top:20px&quo ...
- 解决宝塔环境composer报错:TypeError: Return value of Symfony\Component\Process\Process::close
问题: 解决宝塔环境安装运行composer时报错:TypeError: Return value of Symfony\Component\Process\Process::close 不熟悉的人看 ...
- nodejs隐藏窗口启动redis服务,一个vbs文件即可
网上也有很多类似的,但基本都是用nodejs调.vbs,然后间接调.bat,经过多番尝试发现其实合并为一个文件亦可 将如下内容保存为.vbs文件,如startRedis.vbs (在nw的根目录) s ...
- 【经验】Python3|输入多个整数(map方法或ctypes调用C标准库scanf)
文章目录 方法一:多次调用input 1. 代码 方法二:调用C标准库 1. 代码 2. 残留的问题(int数组取元素) 附:计算时间差的程序(使用实例) 第一种读取方式: 第二种读取输入方式: 方法 ...