R数据分析:网络分析的做法,原理和复现方法
对于复杂问题和现象行为的研究,尤其是他们之间还有复杂的交互影响(complex interplay)的时候,网络分析(备用名:psychological networks, network analysis or network psychometrics)是个备选的好方法,这个方法火了也没几年,感兴趣的同学可以去学学,而且,如果你再能把网络图做的美点,应该各个审稿人都愿意看的。今天尝试给大家做个网络分析的简单介绍。
举个例子,像physiological, psychological, social and environmental factors等等如何影响肥胖,很复杂,做个多元回归?做个结构方程模型?这些都缺乏系统性的视角,从整体上把握肥胖的影响因素之间的关系,找最重要的干预靶点推荐用网络分析。
像健康,行为,心理,认知功能等等,反正就是复杂系统的分析,想不到课题了,就可以考虑在方法上上网络分析
From a network perspective, health behaviours and outcomes can be conceptualised as emergent phenomena from a system of reciprocal interactions: network analysis offers a powerful methodological approach to investigate the complex patterns of such relationships.
比如一个文章,研究自杀的,原文贴在下面:
Bloch-Elkouby, S., Gorman, B., Schuck, A., Barzilay, S., Calati, R., Cohen, L. J., Begum, F., & Galynker, I. (2020). The suicide crisis syndrome: A network analysis. Journal of Counseling Psychology, 67(5), 595–607.
通过网络分析作者就回答了三个问题:一是自杀崩溃综合征中不同症状的关系是什么?二是这些症状有没有哪几个格外重要?三是这些症状有没有一些聚集性?三个问题每一个都很有价值,一个网络分析全给你解决了,感兴趣的同学下载去读读。
还有一个点很重要,网络分析可以帮助你识别复杂系统的干预点,这个其实是很有临床价值的
network analyses allow for the computation of centrality indices that provide information about the symptoms that are the most connected to the other symptoms included in the network and whose potential causal contribution to the other symptoms may thus deserve further investigation
如果你是搞人文社科的,由于其是一个针对复杂人文系统的作用关系,网络分析也是最容易帮助你提出原创理论假设的一项重要技术支撑。总体的意思就是想推动0到1的科研,这个方法必须要学。
网络分析基础
一个最简单的网络,像这样
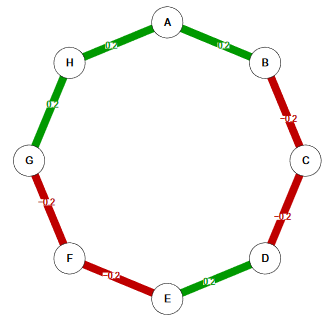
有好些点叫做node,这些点被线连起来的,线叫做edge。
在网络图中点表示的是变量,线表示的是变量关系,注意这个线是没有箭头的(一般是偏相关系数),正向系数是绿线,负值系数是红线,线的粗细反应关系的强度,越粗越强。通过这么一个网络图,对于多变量间的复杂关系就可以有一个一目了然的呈现。
Psychological networks consist of nodes representing observed variables, connected by edges representing statistical relationships. This methodology has gained substantial footing and has been used in various different fields of psychology, such as clinical psychology, psychiatry, personality research, social psychology , and quality of life research
成图的基本步骤如下

首先得有数据间的统计模型,模型系数作为edge的权重,然后成图,然后评估模型。
具体来讲可以选择的统计模型多了: correlations, covariances, partial correlations, regression coefficients, odds ratios, factor loadings,一般我们都是选用偏相关系数作为边的权重。节点固定的情况下,网络可以画的很密的,为了增加interpretability and generalizability和网络的稳定性,需要用一些正则通常是LASSO来简化网络,就是把哪些意义不大的边搞掉,使得网络图更加的简洁好解释。成图之后就是评估模型了,主要的分析有两个edge stability analysis和centrality indices,以下简单介绍:
edge stability analysis
本身来讲网络分析就是比较复杂的,网络的随机性相对于别的分析就要大一些,而且本身来讲我们的科研逻辑就是用样本反映总体,如果你做出来的网络不稳定你能说你发现的比如肥胖比如自杀的网络是可信的?所以做完网络分析之后我们对于网络的稳健性我们是一定要报告的,逻辑就是进行反复的bootstrap抽样,反复的重新估计模型,反复的重新计算confidence intervals (e.g. 95% CI) for their edge estimates看看这些模型的差异从而评估模型的稳健性,通过edge stability analysis我们可以得到网络各个边的权重的置信区间,区间越窄,说明网络越稳定。做edge stability analysis的示例代码如下:
resboot1 <- bootnet(Data, default = c("EBICglasso"), tuning=.5,corMethod="cor_auto",
nBoots = 1000, nCores = 8, type = c("nonparametric")) 通常这一部分论文中也会以图的形式报告出来。
centrality indices
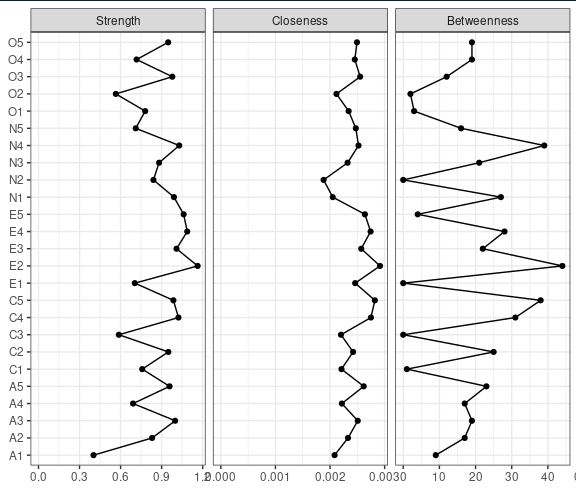
在网络分析中每个节点的重要性是不一样的,是不是存在某些节点相对于另外的节点更重要?对节点重要性的评估的指标就是centrality indices,这个指标又包含3个指数strength, closeness, and betweenness,三个指标的意思见下面:
strength, which shows how well a node is directly connected to other nodes, closeness, which shows how well a node is indirectly connected to other nodes, and betweenness, which quantifies the number of times a node acts as a bridge along the shortest path between two other nodes
简单的逻辑就是如果图中的一个点和另外的点连线多越强,那么这个点就重要,这个点也越应该放在图的中心;如果一个点和其他点的间接距离越近那么这个点越容易受到网络变动的影响;如果一个点平均来看总是在两两关系中起桥接作用,那么这个点对整个网络的构成就意义极大。
通常只报告strength就可以,因为其他两个指数都不太稳定。
实例操练
我们今天依照一篇2022年发表在American Journal of Public Health Research上的研究为参照进行做法复现,文章的名字叫Partial Relationships between Health and Fitness Measures in Adults: A Network Analysis
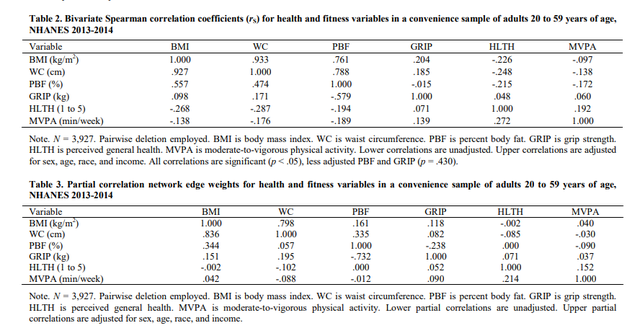
结果中作者报告了变量的两两相关的相关系数矩阵还有模型的network edge weights,见下表:
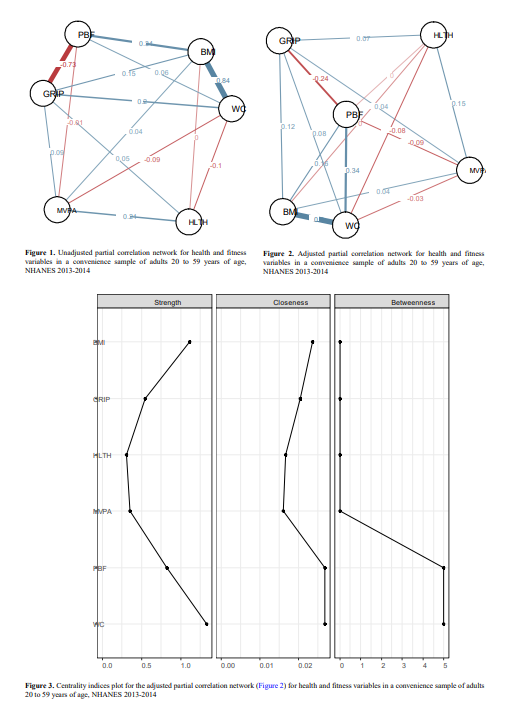
作者报告了网络图还有模型的centrality indices,都是以图的形式呈现的,见下图:
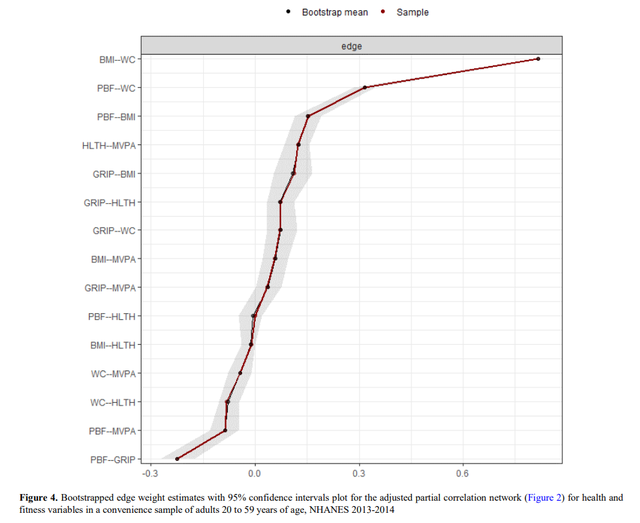
还有Bootstrapped edge weight estimates,也是一个图:
那么我们今天就来看下,这个论文的图如何用自己的数据复现出来。
比如我现在有数据如下,有2800个观测,26个变量,最后一个变量是性别,其余的25个变量是5个5条目的量表:
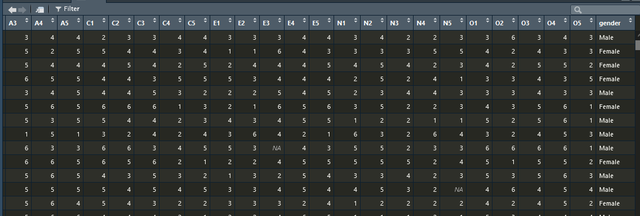
首先我要做的是拟合网络模型,拟合网络模型用到的核心函数是estimateNetwork,通常我们只用设置data和default参数便可以运行,我们要通过lasso来简化网络的话就设置default = "EBICglasso",将拟合好的网络模型对象喂给plot即可以出网络图。

比如我要对男性观测拟合网络模型,可以写出代码如下:
network_male <- estimateNetwork(df %>%
filter(gender == "Male") %>%
select(-gender),
default = "EBICglasso",
corMethod = "spearman")运行完毕后,直接将模型对象喂给plot即可出图:

到这儿就基本算是完成了,但是要发表的话还是有点粗糙的,其实我们的数据中不同的字母(变量名)代表的是不同的量表,其实更好的方法是将各个量表的条目放一起,并且给出图例,使得其一目了然,所以接下来我们得对图形做一些调整。
比如我要对节点的整体布局做一个调整并且加上每个量表的图例,我就可以在代码中加上group参数,指明每个节点都是来自哪个量表的:

这样其实就好看多了,当然如果需要更细的图例,比如我想知道每个节点到底啥意思,我还可以用nodeNames参数加上节点的图例:
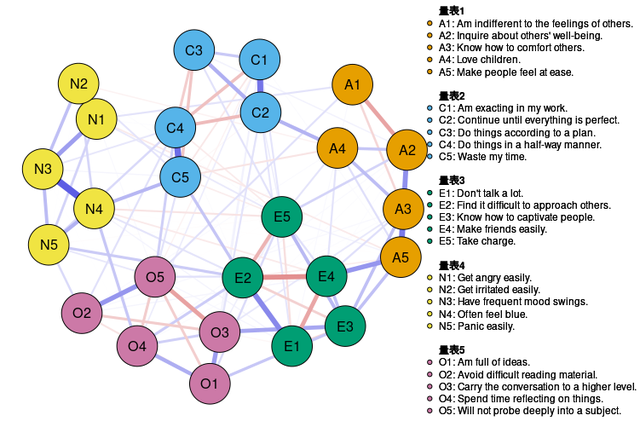
这样就更好了,赞。
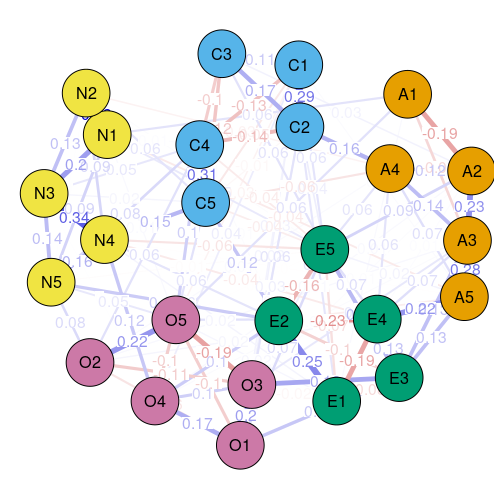
但是我们注意American Journal of Public Health Research上的这篇研究是给边加了标签的,我们要出这样的效果的话只需要设定edge.labels为真就可以了,因为节点比较多,加上标签其实效果就不太好了:
我们接着再看作者的另外的两个图的做法,一个是centrality indices的图,我们只需要将模型对象喂给centralityPlot即可出图:
另一个是边的权重估计的图,只需要将模型对象喂给bootnet,并且plot就可出来:
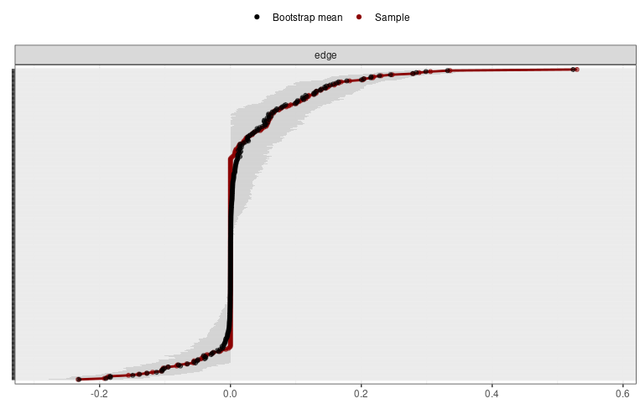
可以看到我们的图的效果其实是比原文好的。
到这儿,原文中所有的结果都给大家复现完了。
网络分析的协变量控制
本身来讲网络分析的输入数据其实是相关矩阵,这个时候我们想控制协变量比如年龄、性别、民族等等,可行的方法就是做回归取残差,以残差的相关矩阵作为模型的输入,同样的思想可以在结构方程中使用,比如你做个交叉滞后想控制协变量就可以用这个方法哈,中英文的发表文献引用证据都各给大家贴一个,做法上也都很好实现的:


小结
今天给大家写了网络分析的做法,其实还有一块就是网络分析的对比,解决的问题是几个网络是不是不一样,或者同一个网络的某两个边是不是不一样,这个以后有机会给大家写。
R数据分析:网络分析的做法,原理和复现方法的更多相关文章
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- R数据分析:用R建立预测模型
预测模型在各个领域都越来越火,今天的分享和之前的临床预测模型背景上有些不同,但方法思路上都是一样的,多了解各个领域的方法应用,视野才不会被局限. 今天试图再用一个实例给到大家一个统一的预测模型的做法框 ...
- R数据分析:数据清洗的思路和核心函数介绍
好多同学把统计和数据清洗搞混,直接把原始数据发给我,做个统计吧,这个时候其实很大的工作量是在数据清洗和处理上,如果数据很杂乱,清洗起来是很费工夫的,反而清洗好的数据做统计分析常常就是一行代码的事情. ...
- 初涉IPC,了解AIDL的工作原理及使用方法
初涉IPC,了解AIDL的工作原理及使用方法 今天来讲讲AIDL,这个神秘的AIDL,也是最近在学习的,看了某课大神的讲解写下的blog,希望结合自己的看法给各位同价通俗易懂的讲解 官方文档:http ...
- 【java回调】同步/异步回调机制的原理和使用方法
回调(callback)在我们做工程过程中经常会使用到,今天想整理一下回调的原理和使用方法. 回调的原理可以简单理解为:A发送消息给B,B处理完后告诉A处理结果.再简单点就是A调用B,B调用A. 那么 ...
- View_01_LayoutInflater的原理、使用方法
View_01_LayoutInflater的原理.使用方法 本篇博客是郭神博客Android视图状态及重绘流程分析,带你一步步深入了解View(一)的读书笔记的笔记. LayoutInflater简 ...
随机推荐
- iframe嵌套登录页-页面无法加载
背景 活动页面和登录页跨域,过去都是跳转到登录页登录之后再跳转回来,体验不好. 现在需要将登录模块嵌入到活动页,因为懒,不想开发重复的模块,首先我想到的是iframe 刚开始还能正常使用,一段时间后安 ...
- T2回家(home)题解
T2回家(home) 现在啥也不是了,虽然会了逆元,但是对期望概率题还是一窍不通,赛时相当于只推出了 \(n=1\) 的情况,结果运用到所有情况,理所应当只有20分. 题目描述 小Z是个路痴.有一天小 ...
- 北京智和信通 | 无人值守的IDC机房动环综合监控运维
随着信息技术的发展和全面应用,数据中心机房已成为各大企事业单位维持业务正常运营的重要组成部分,网络设备.系统.业务应用数量与日俱增,规模逐渐扩大,一旦机房内的设备出现故障,将对数据处理.传输.存储以及 ...
- window和Linux下安装nvidia的apex
两种方法: 1.去github下下载apex,之后安装到你的python环境下,我的安装路径:E:\Anaconda\anaconda\envs\pytorch\Lib\site-packages 注 ...
- webgl和canvas的区别
webgl和canvas的区别 WebGL和Canvas的主要区别在于它们的渲染方式.功能复杂性.以及编程难度.12 渲染方式:Canvas使用2D渲染上下文来绘制图形和图像,基于像素的绘图系统, ...
- kubernetes拉取私有镜像仓库的镜像
kubernetes拉取私有镜像仓库时需要使用镜像仓库的账号密码 方式: apiVersion: v1 kind: Pod metadata: name: private-reg spec: cont ...
- 云原生的 WebAssembly 能取代 Docker 吗?
WebAssembly 是一个可移植.体积小.加载快并且兼容 Web 的全新格式.由于 WebAssembly 具有很高的安全性,可移植性,效率和轻量级功能,因此它是应用程序安全沙箱方案的理想选择.现 ...
- 鱼香ROS一键安装软件
一行代码-解决人生烦恼 推荐语:一行代码搭建机器人开发环境(ROS/ROS2/ROSDEP) 开源地址:https://github.com/fishros/install 一键安装指令 wget h ...
- ROS中无法定位软件包问题
ROS 和ubuntu版本对应关系
- oracle下拼同比环比查询sql方法
拼接方法: /// <summary> /// 生成计算同比环比查询语句 /// table:表名称:statColumns:要统计的值字段;yearColumn:年份字段名:monthC ...