探秘Transformer系列之(24)--- KV Cache优化
探秘Transformer系列之(24)--- KV Cache优化
0x00 前言
目前的大型语言模型(LLM)服务系统采用KV Cache来避免在解码阶段重复计算键和值的投影。虽然这对于单个客户端请求生成短序列而言是一个有效的解决方案,但是,面对多个客户时,每个请求都保留自己的KV缓存,从而增加了推理过程中的总体KV缓存大小。另外,即使是针对单个客户端请求,当我们生成长序列或处理多轮对话时,KV Cache 依然会对推理性能造成极大的影响。比如,束搜索和平行采样也被广泛用于生成更好的输出或为客户提供候选选择。这些技术也会像批处理推理一样增加KV缓存的大小,因为它们会同时处理多个序列。
KV Cache问题的核心在于,KV Cache 占用了大量内存和访存带宽,同时在生成阶段引入了大量重复计算。从而阻止了我们处理或生成非常长的序列和处理大批量数据,无法最大化硬件效率。这就好比一个图书馆管理员每天忙于检索每本书的信息,却没有时间去为用户去拿书。而总体趋势上,LLM 的窗口长度也在不断增大,因此就出现一组主要矛盾,即:对不断增长的 LLM 的窗口长度的需要与有限的 GPU 显存之间的矛盾。
因此优化 KV cache 就显得非常必要,KV Cache 压缩技术也成为了 LLM 推理领域的热门研究方向。本文会带领大家深入剖析KV Cache的各项特性,并详细阐述了当前用于优化LLMs中KV Cache空间使用的各种方法,阐明了它们之间的相互关系,并比较它们的核心思想。
注意:因为KV Cache优化的内容太多,因为我们将分为三篇文章来仔细学习。
注:全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改此文章列表。
cnblogs 探秘Transformer系列之文章列表
0x01 背景知识
1.1 度量指标
推理加速一般可以从两个层面体现:吞吐量与延迟。这两个层面的指标参见下图。

生成式LLM可以用于各种具有不同SLO( Service Level Objective/服务级别目标)的任务。对于批处理任务(例如摘要),TTFT或TBT延迟指标不如吞吐量重要。另一方面,对于对延迟敏感的任务(例如对话API),TTFT和TBT是更重要的指标,其SLO更严格。
1.1.1 吞吐量
吞吐量 (Throughput) 是从系统的角度来看的指标,或者说是 LLM 服务的成本指标,表示每生成一个 token 服务商需要支付的算力成本。吞吐量有多种评估方式,比如 tokens per second(tps),即推理服务器单位时间内能处理针对所有用户和请求生成的输出token数。如果不仅考虑预填和解码,还考虑内存限制和上下文切换,则可以考虑基于会话的吞吐量,即在给定时间内的并发用户交互数量,是一个端到端的目标。
\]
吞吐量衡量的是所有用户和请求中完成的请求或词元的数量,因此忽略了时延要求。有研究人员引入了有效吞吐量(goodput),即每秒完成请求的遵守 SLO(TTFT 和 TPOT 要求)的数量。因为有效吞吐量捕获了在 SLO 达成下的请求吞吐量 —— 因此既考虑了成本又考虑了服务质量。
1.1.2 延迟
模型为用户生成完整响应所需的总时间可以使用这两个指标来计算:TTFT和TPOT。
首次token生成时间(Time To First Token,简称TTFT)
TTFT是在用户输入查询的内容后,模型生成第一个输出token所需要的时间。在人机实时交互的过程中,让用户得到快速的响应至关重要,返回结果越快,用户体验越好。但对于离线工作负载则不太重要。在实践中,我们一般会人为设置一个TTFT SLO(Service Level Objective)。举例来说,假设我们定P90 TTFT SLO = 0.4s,那么这意味着我们对该系统的要求是:“90%的request的TTFT值都必须<=0.4”。
单个输出词元的生成时间(Time Per Output Token,简称TPOT)
TPOT 是推理系统根据用户请求生成后续词元所需要的平均时间,即总生成时间除以总生成 token 数。
该指标与每个用户如何感知模型的“速度”相对应。延时较高会让客户陷入较长的等待时间,大大影响交互体验,但只要生成速度大于人类的阅读速度就能获得很好的用户体验。例如,100 毫秒/token 的 TPOT 意味着每个用户每秒 10 个 token,或每分钟约 450 个单词,这比一般人的阅读速度要快。
token之间的时间(TBT)
也有研究人员建议使用token之间的时间(TBT),因为 TBT 的定义则更加明确的指定为两个 token 生成间的延迟,因此基于 TBT 上限来设计 Service Level Objective (SLO) 能更好的反映流式交互时的用户体验。
TBT 和 TPOT 在以下情况下可能会表现不一致:
- 生成速度不均匀:如果模型在生成过程中速度不稳定,TBT 会显示出这种波动,而TPOT则会平均化这些差异。假如某些token生成特别慢,而其他的很快,TBT 会反映这种差异,TPOT则会给出一个平均值。
- 批处理效应:某些模型可能会进行批处理,一次生成多个token。这种情况下,TBT 可能会显示为周期性的模式(批次内快,批次间慢),而TPOT会平滑这种效果。
- 长序列生成:在生成长序列时,模型可能会因为上下文增长而逐渐变慢,TBT 会清楚地显示这种逐渐减速的趋势,而TPOT只会反映整体的平均速度。
- 硬件资源波动:如果服务器负载不稳定或存在资源竞争,可能会导致某些时刻的生成速度突然变慢,TBT 能够捕捉到这些瞬时的波动,而TPOT则会将其平均化。
- 模型架构特性:某些模型架构可能在生成特定类型的token时更快或更慢。TBT 可以反映出这种因token类型而异的速度差异,TPOT则会给出一个整体的平均值。
- 缓存效应:如果模型使用缓存来加速生成,可能会导致某些token生成得特别快。TBT 会显示出这种不均匀的速度,而TPOT会平均化这种效果。
总之,TBT 提供了更细粒度的性能视图,能够反映出生成过程中的变化和波动。而TPOT则提供了一个整体的、平均的性能指标。在分析模型性能时,最好同时考虑这两个指标,而不是只看常用的TPOT。
关注指标
LLM的推理过程一般分为预填充(Prefill)和解码(Decode)两个阶段。预填充阶段负责处理输入提示(Prompt)的完整内容,计算量大但并行性高,同时生成第一个Token;解码阶段则通过自回归方式逐个生成后续的Token,尽管单步计算量较小,但每个新Token的生成都必须反复访问之前生成的所有Token对应的KV缓存(Key-Value Cache)。
由于预填充和解码阶段具有不同的特征,人们用不同的指标来衡量它们对应的SLO。具体来说,预填充阶段主要关注请求到达和生成第一个标记之间的延迟,即TTFT。另一方面,解码阶段关注同一请求连续标记生成之间的延迟,即TBT,或者TPOT。最大化总体有效吞吐量是LLM推理优化主要目标,这主要是 TTFT 和 TBT,简单说就是prefilling阶段耗时优化+decoding阶段耗时优化。
1.2 内存危机
LLM 推理服务的吞吐量指标主要受制于显存限制。有研究团队发现,现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache。下图展示了一个13B的模型在A100 40GB的gpu上做推理时的显存占用分配(others表示forward过程中产生的激活大小,这些激活可以用完则废,因此占据的显存不大),从这张图中我们可以直观感受到推理中KV cache对显存的占用。

内存危机的原因主要是以下几点:
- LLM中最昂贵的操作是矩阵乘法和softmax,它们本身是 memory-bound。
- LLM中的权重和激活 本身已经就接近达到 memory capacity
- KV caching进一步加剧了内存容量的需求(随着句子长度和batch size线性增长),而存储容量是由序列长度和模型维度决定的。对于给定的LLM,随着批大小和序列长度的增加,分配给KV缓存的内存继续线性增长,并在某些时候超过可用内存容量。
- 长序列访问瓶颈:随着Token数量增加,每次生成新Token时需读取的KV缓存数据量成线性增长,导致显存带宽压力增大,延迟上升。
下图则可以从细节来查看推理中KV cache对显存的占用,以及推理的不同阶段关注的指标。其中:
- Model memory:模型内存。模型大小保持不变,不受序列长度或批次大小的影响。
- Peak Momery:峰值内存 = 模型内存+kvcache。
- Latency:生成总耗时 = TTFT+TPOT*生成的token数目。
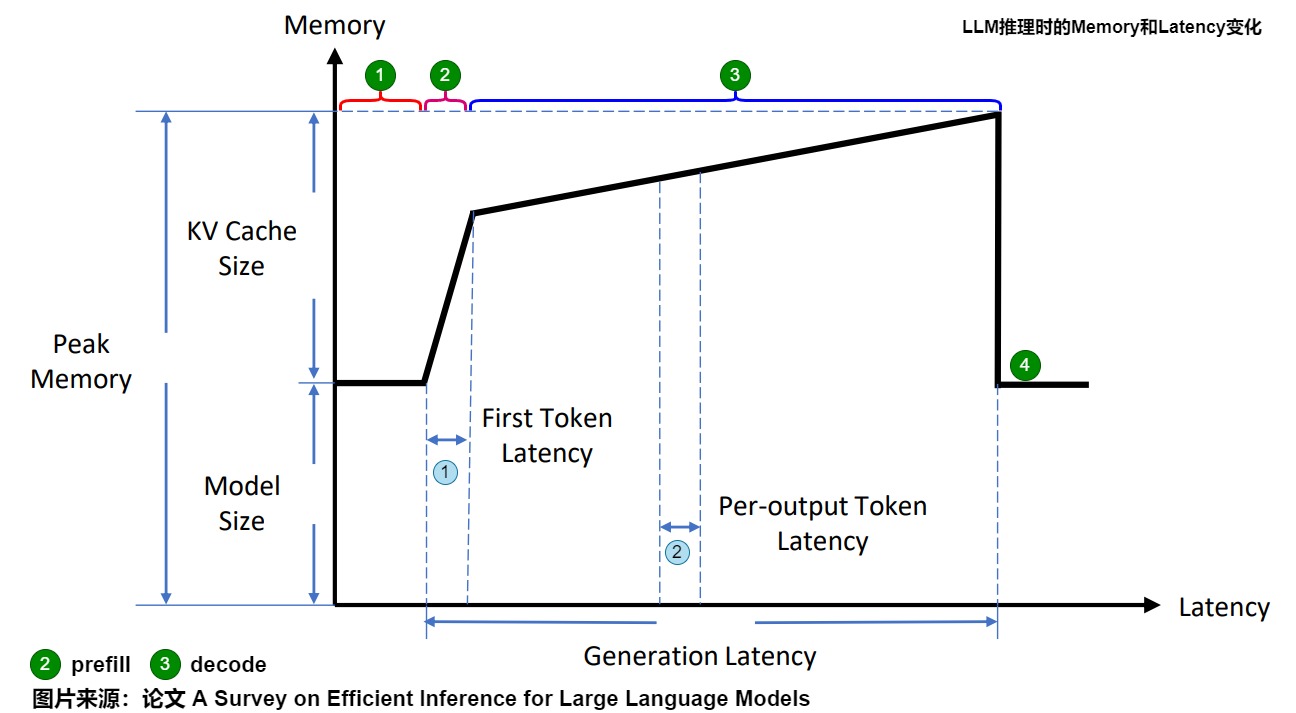
从图上可以看到,在生成过程中 Latency 和 Memory 的关系,具体分析如下。
绿色标号1为待机阶段,此时模型等待输入,内存是模型权重。
绿色标号2为Prefill 阶段,特点如下:
- 可以并行计算。浅蓝色标号1代表生成第一个token所需时间,该Latency比较低。
- 会一次生成大量 KV Cache,所以内存在短期内激增。
- 假设 Batch size 为 1,序列长度越大,计算强度越大,通常都会位于 Compute Bound 区域。
- 预填充长输入比短输入需要更长的计算时间和GPU内存;
绿色标号3为Decoding 阶段,其特点如下:
- 不能并行计算,天蓝色标号2代表Decoding 阶段生成一个 Token 的 Latency,该Latency 比较高,而且,随着序列的变长,这个 Latency 会逐渐增加。
- 显存增加比较慢,但是显存的增量与序列的长度成正比。
- 在预填充后,驻留在GPU HBM上的大型KV Cache大大限制了可服务的并发用户数量;
- 在解码过程中,从HBM到SM重复读取KV Cache会导致显著的上下文切换延迟。
- Batch size 越大,计算强度越大,理论性能峰值越大,但此时通常都会位于 Memory Bound 区域。
绿色标号4是当一个序列处理完之后,会释放相应的 KV Cache。此外,模型参数在不同序列间是共享的,而 KV Cache 则不是。
下图给出了有和没有KV缓存的OPT-6.7B推理的执行时间和GPU内存使用情况。x轴步长索引表示输出序列长度。在没有KV缓存的情况下,执行时间迅速增加;在有KV缓存的情况下,只有新生成的令牌的注意力权重和分数被计算为向量-矩阵乘法,在不同的步骤中,执行时间几乎保持不变。这种运行时间的减少是以GPU内存使用量为代价的,随着时间的推移,GPU内存使用量逐渐增加,这是由于KV张量的规模越来越大。
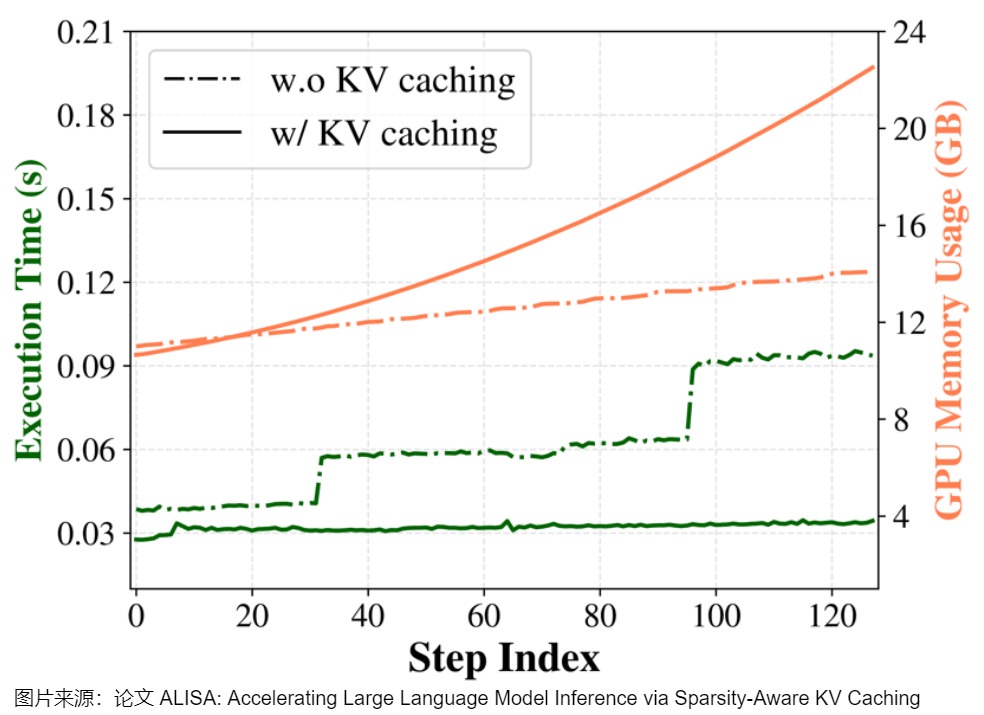
因此,如何优化KV cache,节省显存,提高推理吞吐量,就成了LLM推理框架需要解决的重点问题。
1.3 KV Cache问题
我们总结下传统KV Cache中存在的问题。
- 显存占用问题。随着总序列长度(上下文窗口大小)或一次处理的序列数量(batch size,即吞吐量)的增长,KV Cache也会随之线性增长。因此,KV缓存的大小实际上并没有上限,而GPU内存显然是有限的。 这样KV Cache缓存成为主要缓存占用。在更长的上下文中,KV Cache大小甚至超过了模型参数的大小。
- 内存碎片化。每个新生成的Token都会产生对应的
K和V向量,并存入缓存。在持续的\({K, k_n} \longrightarrow K\) 和 \({V, v_n} \longrightarrow V\)操作中,内存被反复分配和释放,导致大量碎片化问题。 - 显存管理问题。随着序列长度增加,缓存规模线性增长,导致管理复杂度随之上升。比如,传统策略(如LRU、LFU)难以适配LLM的访问模式,需设计专用策略;缓存内存需求随序列长度和层数线性增长,易超出硬件限制,需优化多存储设备协作。面对变化的访问模式,需自适应缓存策略来进行动态负载;分布式环境下,跨节点一致性和资源如何协调。
- 内存带宽瓶颈。随着Token数量的增加,每次生成新Token时需读取的KV缓存数据量呈线性增长,且无法批量处理KV Cache也加剧了严重的内存带宽瓶颈。
- GPU利用率低下。解码阶段从计算密集变成访存密集了。这就导致GPU的算力,在解码阶段不是瓶颈了,要想加速解码,得从访存方面下手。但是,我们获取大型权重矩阵和不断增长的KV缓存,只是为了执行微不足道的矩阵到向量的操作。我们最终花费的时间更多地用于数据加载,而不是实际的数值计算,这显然导致了GPU计算能力的低效利用。
0x02 总体思路
2.1 分类
考虑到GPU内存的有限性,而减小内存占用的策略是一箭三雕的,因为能够使我们提高硬件利用率和成本效益,同时减少时延并增加吞吐量。因此,KV Cache的内存压力激发了许多不同方向的创新,比如新型注意力架构(如MQA、GQA、SWA)、缓存压缩策略(如H2O、Scissorhands、FastGen)、高效的内存管理(如PagedAttention、RadixAttention),以及量化和存储容量扩展(如负载系统、单主机和多主机模型并行)。
但是如何给这些 KV Cache 优化思路进行分类?有些研究人员已经给出了他们的答案,这些答案各有不同。
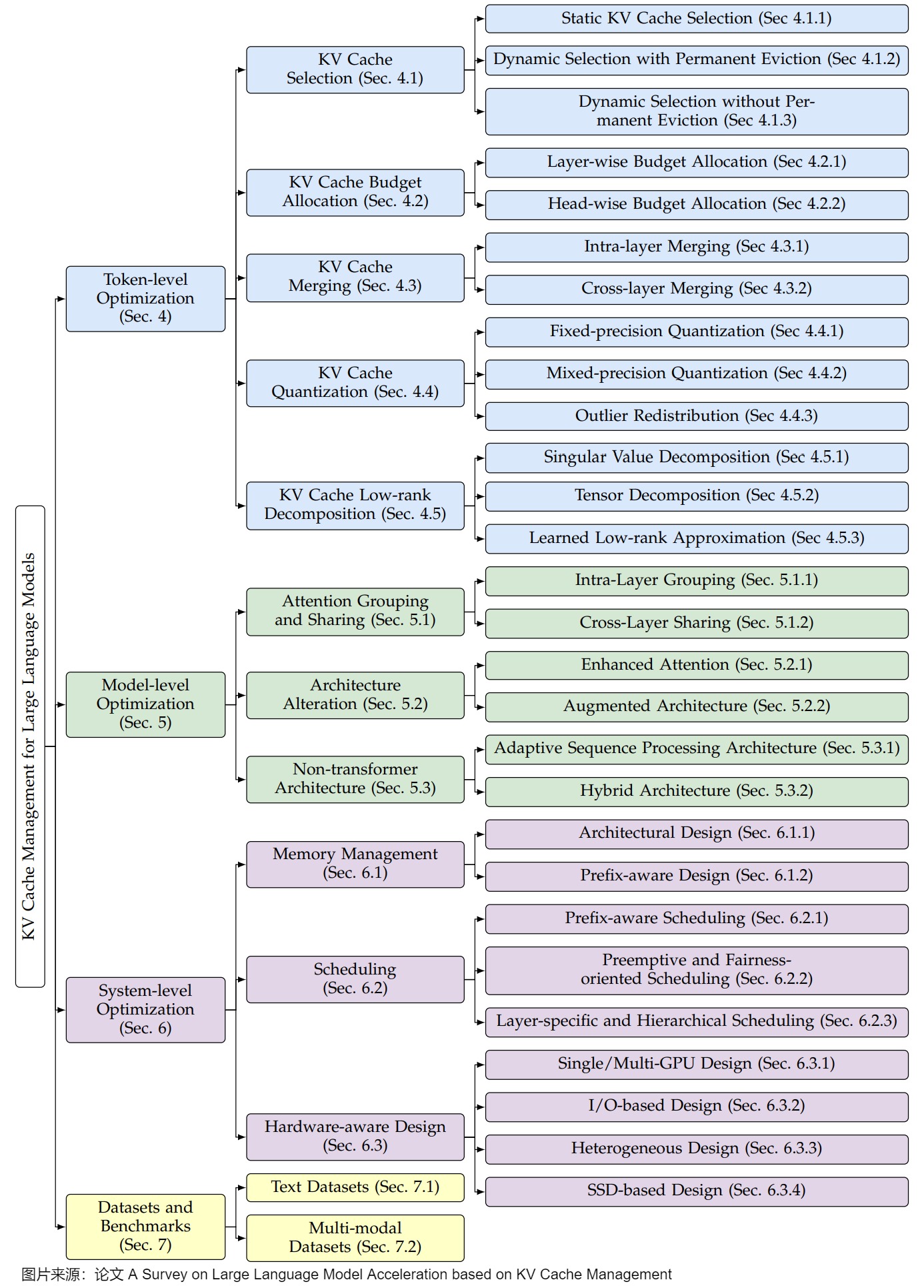
比如下图来自论文“A Survey on Large Language Model Acceleration based on KV Cache Management”。该论文基于KV Cache对LLM推理时间与内存需求的显著影响,系统梳理了现有优化策略,并将其划分为三个层次:token级优化、模型级优化和系统级优化。
- token级优化是指通过专注于细粒度来提高KV缓存管理效率。在token级进行仔细的选择、组织和压缩,不需要对原始模型进行架构更改或系统并行技术。优化方法分为五类:KV Cache选择、预算分配、合并、量化及低秩分解。这些方法通过直接操作token级数据,实现了计算效率与内存需求的初步优化,为后续更高层次的改进奠定基础。
- KV Cache选择:侧重于优先排序和仅存储最相关的token。优先存储对推理最重要的token,通过评估token相关性减少冗余缓存,提升内存利用率。
- KV Cache预算分配:在token之间动态分配内存资源,以确保在有限内存约束下优化缓存分布,确保高效利用。
- KV Cache合并:识别并合并相似或重叠的KV对来减少冗余存储,进一步压缩缓存规模。
- KV Cache量化:通过降低KV对的存储精度(如从Float32到Float16或更低比特)来最小化内存占用,同时需平衡精度损失与性能收益。
- KV Cache低秩分解:利用低秩分解技术将KV矩阵分解为较小维度表示,压缩缓存体积,同时保留关键信息。
- 模型级优化是指从架构设计角度优化KV Cache管理,通过调整模型结构或引入新机制减少缓存依赖,从根本上减少KV Cache的生成与使用需求,提升整体效率。具体策略包括:
- 注意力分组和共享:检查键值对的冗余功能,并在Transformer层内或跨Transformer层进行分组和共享KV缓存,降低存储需求。
- 架构更改:设计新的注意力机制或构建用于KV优化的外部模块,针对KV优化重新构造模型计算流程,减少对缓存的直接依赖。
- 非Transformer架构:这些架构采用了其他内存高效的设计,如使用循环神经网络来优化传统Transformer中的KV缓存。
- 系统级优化是指从底层硬件与资源调度角度优化KV Cache管理,涉及内存分配与任务调度等经典问题,旨在最大化硬件资源利用率,以在多样化计算环境中提升效率。具体技术包括:
- 内存管理:通过架构创新优化内存使用,如虚拟内存适配、智能前缀共享和层感知资源分配,确保缓存高效存储与访问。
- 调度策略:通过前缀感知方法以最大限度地提高缓存重用率,采用抢占式技术实现公平上下文切换,或设计层特定机制进行精细化缓存控制,以解决多样化优化目标。
- 硬件感知设计:针对单/多GPU、I/O优化、异构计算及SSD存储提出解决方案,提升KV Cache的访问速度与存储容量。
这一分类框架从微观到宏观,针对KV Cache管理的不同挑战提出了具体技术路径,为理解和设计高效加速方案提供了清晰的理论指引。
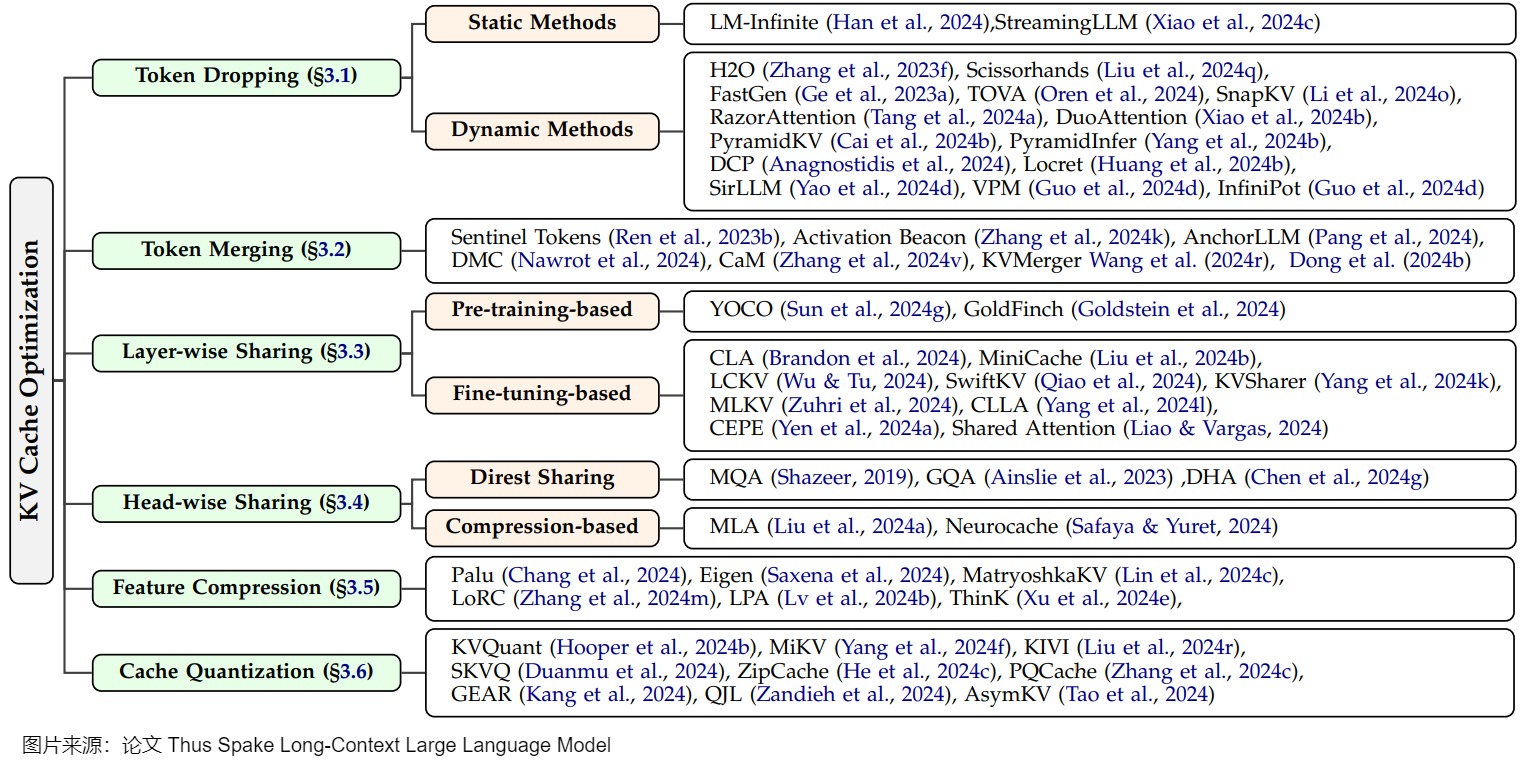
再比如下图来自论文“Thus Spake Long-Context Large Language Model”。其主要分为Token Dropping,Token Merging,Layer-wise Sharing等几类。这种分类方式更加直击本质。由于KV缓存的大小是由缓存序列长度、层数、KV头数、特征维度数和存储数据类型的乘积决定的,我们可以通过改进这些因素中的每一个来优化开销。特别是,由于对序列长度的优化讨论最多,又可以将其分为token丢弃)和token合并。
本篇是借鉴了前人的思想,也加入了笔者自己的思考。笔者认为,从整体上来讲,KV cache主要分成3个方向进行优化:从公式角度进行优化;按照特性进行优化;按照阶段进行优化。这些方向不一定是正交的。因为会有一些方案即从模型结构特点出发,也是从公式角度出发进行优化。为了更好的分析,如果能从公式角度梳理的方案,笔者都将其划分到公式角度。
2.2 从公式角度优化
如上篇所示,KV cache的峰值显存占用大小计算公式(字节)如下:
\(batch\_size \times sequence\_length \times head\_number \times head\_dimension \times layer\_number \times kv\_bits \times 2\)
以QWen为例,4K上下文和100K上下文的对比如下:

通过上述公式我们可以看到, LLM 推理服务为每个 Token 分配了显存空间,其显存空间大小与批次大小,序列长度,头维度、头数量,模型层数、以及KVCache存储的数据类型大小几个维度相关。我们的目标是在给定显存空间,推理服务要处理的 Token 数尽可能的多。因此存在两个优化策略:
- 对 批次大小、序列长度这两个维度进行压缩,用较少的 token 信息表示全量 token 信息;
- 对头维度、头数量,模型层数、以及KVCache存储的数据类型几个维度进行压缩,降低每个 token 的显存开销。
我们逐一检查各个项目来看看影响KV cache的具体因素,以及减少KV缓存内存占用的方法。
注:“从公式角度优化”基本对应论文“A Survey on Large Language Model Acceleration based on KV Cache Management”中的"token级别优化“。
2.2.1 难以利用的选项
我们发现,如下选项难以利用。
减少模型层数
有一部分研究通过比较输入输出的embedding的相似性,来判断某一层是否重要,从而把一些不重要的层进行剪枝。这可以同时达到减少模型weight和KVCache的作用。但是减少层数带来的收获并不多。
减少batch size
batch size和推理的子阶段性能密切相关。比如,Prefill 阶段在比较小 Batch Size 下可以获得比较大的计算强度,相应的吞吐也很高;而 Decoding 阶段需要比较大的 Batch Size 才能获得相对高的计算强度及吞吐。
虽然减少批大小可以减少KV缓存的内存占用,降低时延,但这会使得单次运行能够处理的对象减少,也会降低硬件利用率,导致成本效率降低。所以,在多数情况下,我们并不想减少批大小,反而会尽可能地增加批次大小。
2.2.2 LLM推理加速的优化方向
由此我们可以找到一些优化KV cache的具体方向:
- 减少序列长度:针对超长 prompt,通过减少 kv cache 中 slot 的数量进行压缩,以此达到减少输入输出序列的长度(或者说是提示 + 完成部分)的目的。例如,对于长度为 128K tokens 的 prompt,仅挑选 1024 个 tokens 的 kv cache 进行存储。
- 减少注意力头个数:MQA(multi-query attention)、GQA(Grouped-query attention)通过减少kv cache的head个数减少显存占用。
- 减少key_bits。因为FP16 占2个bytes,所以优化方式主要是量化,把模型参数由fp16转换到int8/int4,每个参数占用的字节也由2byte转换到1byte/0.5byte。在保持 kv cache slot 数量不变的情况下,将数据格式从 fp16 压缩到 int8 或 int4 等低精度格式。
- 减少头维度。DeepSeek V2的MLA引入了类似LoRA的想法,有效地减少了KV头的大小。
- 优化 KV cache 的显存管理:目前GPU上KV Cache的有效存储率较低,可以通过类似PagedAttention的方法进行优化。 因为不是正交的,我们后续把内存管理部分也划分到”按照特性进行优化“部分进行分析。
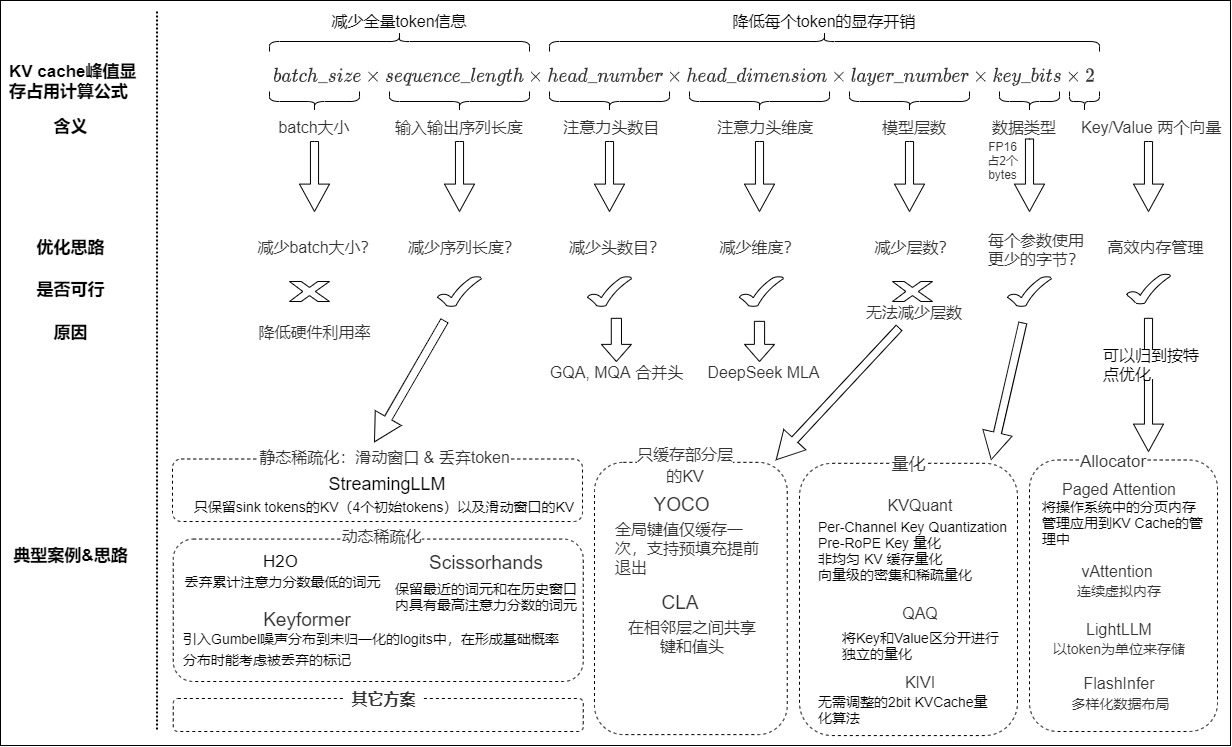
另外,论文“A Survey on Large Language Model Acceleration based on KV Cache Management”中总结了基于模型级别的优化,这种优化通过设计新的变换器架构或机制优化KV Cache复用,通常需对模型进行重训练或微调。模型级别的优化和本文分类不是正交的,因此笔者把本文涉及的方案添加在图上。
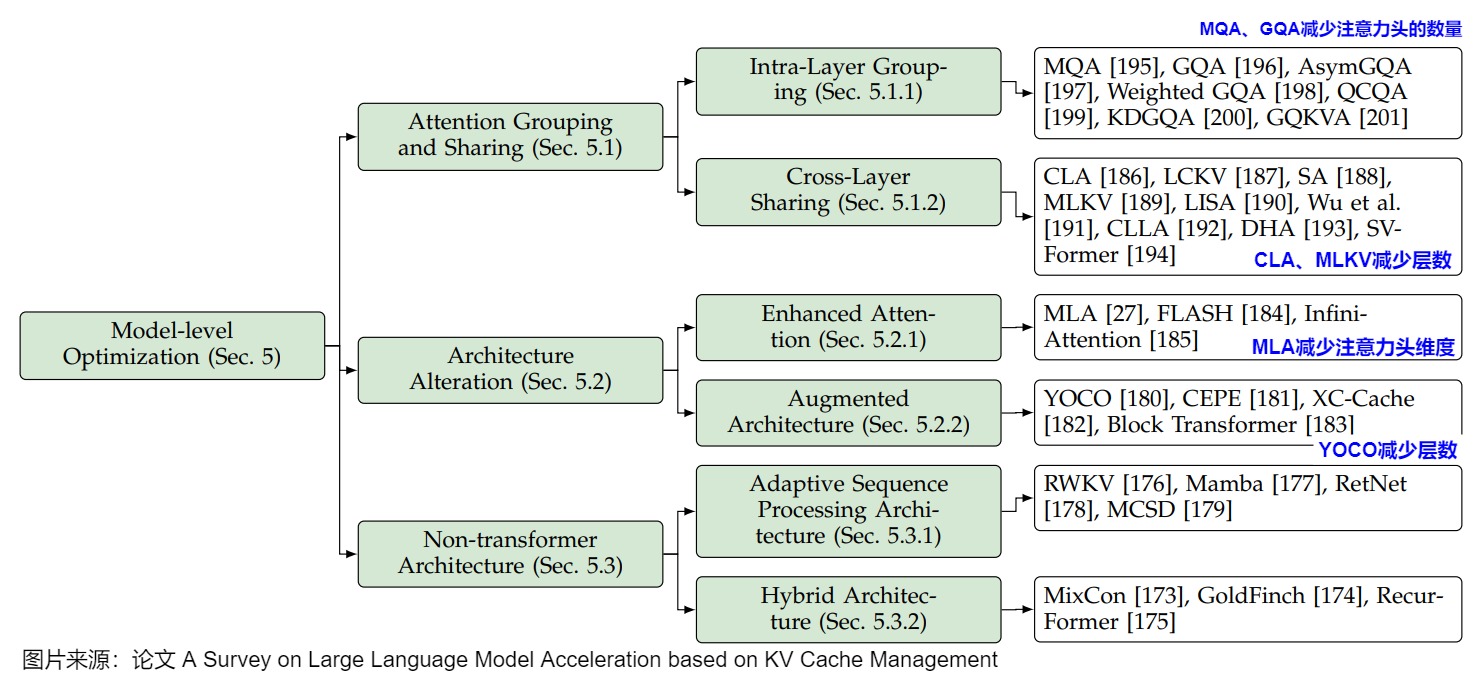
2.2 按照特性进行优化
前文有提到,Prefilling和decoding的特性不同,比如:
- prefilling阶段对计算资源的需求量极大,哪怕是小批次的预填充任务,甚至单个较长的预填充任务,都足以使GPU的计算能力达到饱和。Prefilling阶段是计算瓶颈,随着输入长度增加,耗时超线性增加(吞吐量下降,如果耗时线性增加,那么平均吞吐量不变)。
- 与此相对,解码任务则需要更大的批大小才能充分利用计算资源。decoding阶段是传输瓶颈,随着bs的增大,耗时略有增加(主要是因为数据增多导致传输耗时增多,计算耗时基本认为不变),吞吐量大概是随着输入长度而线性增加。
下图给出了prefill和decoding阶段中,KV Cache的使用。在初始化阶段(对应于第一次迭代),LLM为输入提示中的每个令牌生成键值缓存。在随后的解码阶段,LLM只需要计算一个新生成的令牌的查询、密钥和值,利用预先计算的键值缓存来逐步简化该过程。因此,与初始化阶段(即第一次迭代)相比,解码阶段迭代的执行时间通常较小。
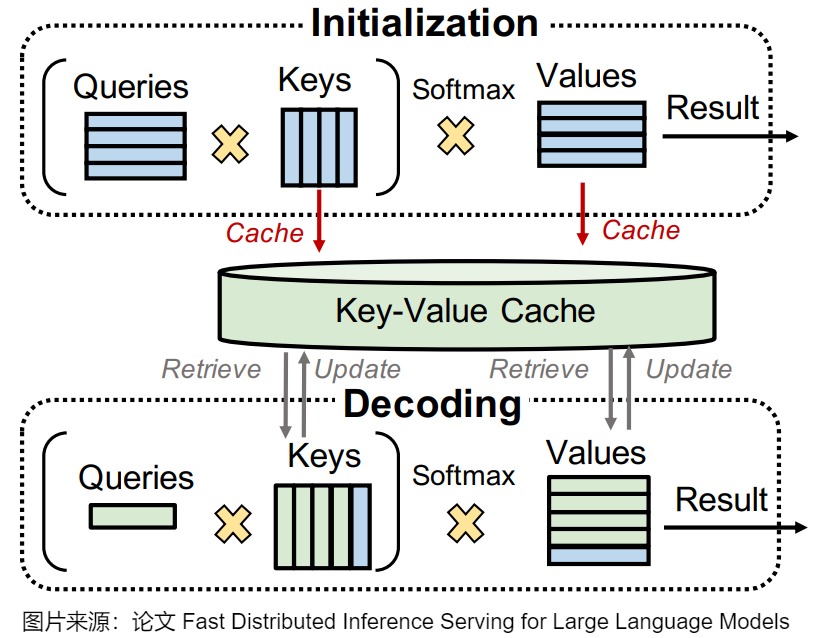
因此,我们要针对这些特性对KV Cache进行不同的处理。这部分与论文“Thus Spake Long-Context Large Language Model”中的系统级别优化有部分重叠。
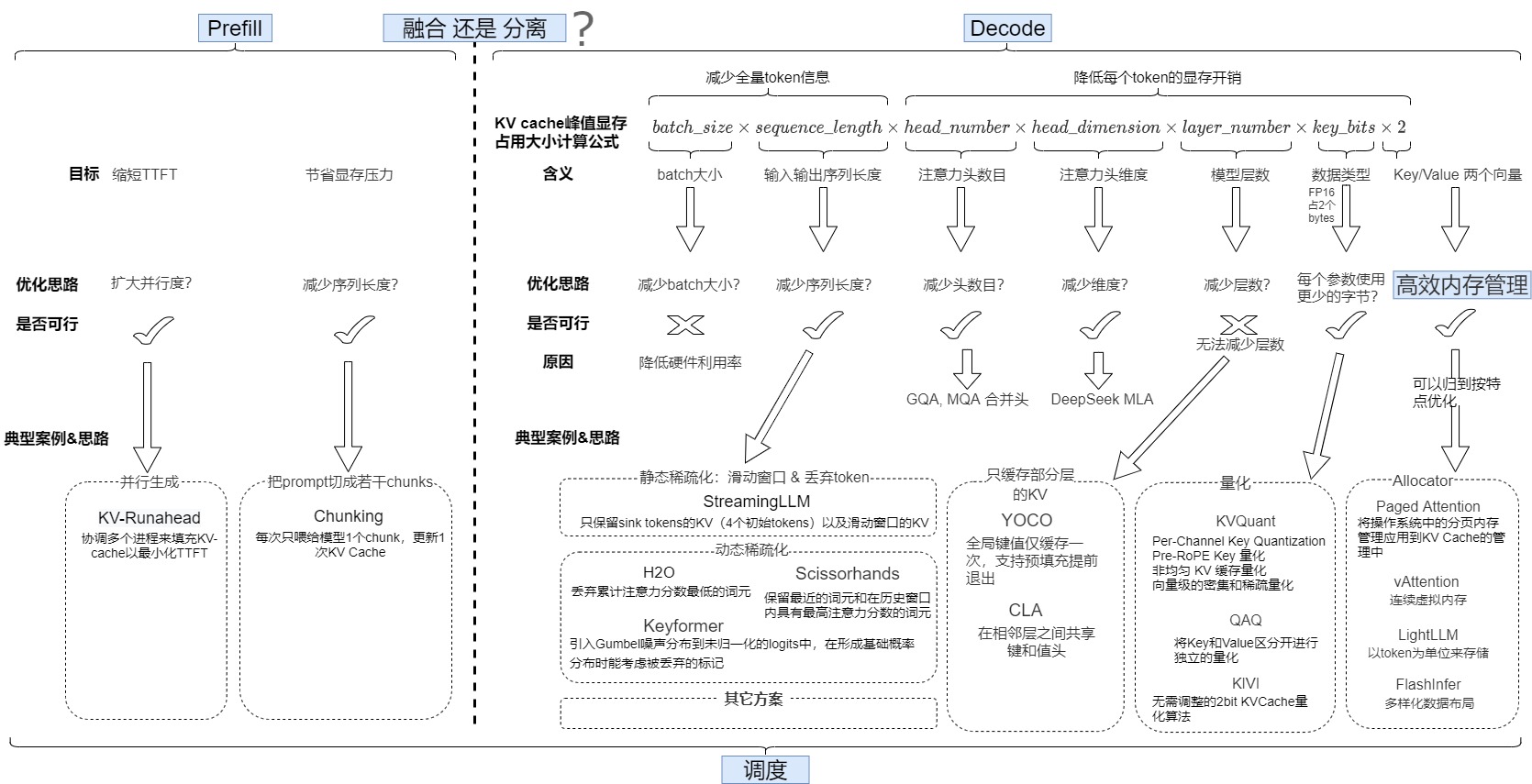
2.2.1 prefill
针对prefill阶段计算强度高的特点有几种优化思路,比如并行生成,把prompt切分等。我们将在本文后续章节中进行深入分析。
2.2.2 Decoding
虽然一次 Decoding Step 计算量线性增加,但由于是访存瓶颈,因此计算时间不会明显增加,如果 Decoding Step 数量减少的比例更多,那么就很有可能降低整个请求的时延。因此需要想办法增加Decoding的请求数目或者起到类似效果。针对 Decoding 阶段计算强度比较低的情况,有两种优化的思路:
- 请求间优化。在不同请求间 Batching 的方式(Continuous Batching),可以增大 Decoding 阶段的 Batch Size,进而更充分发挥 GPU 算力,但是其无法降低单个请求的 Latency,而且如果用户请求比较少,比如只有单一用户,那么永远无法实现 Batching。
- 请求内优化。在单一请求内一次验证多个 Decoding Step(Speculative Decoding),虽然一次 Decoding Step 计算量线性增加,但由于是访存瓶颈,因此计算时间不会明显增加,如果 Decoding Step 数量减少的比例更多,那么就很有可能降低整个请求的时延。
我们会在后续文章进行详细分析。
2.2.3 分离与否
由于Prefilling和decoding的特性不同,计算量差异非常大,导致两者容易会对彼此造成干扰。比如:连续批处理任务中,新加入的prefill任务会显著增加了decoding任务的时延,导致处于解码阶段的请求在每次预填充请求进入系统时都会“卡住”。因此,有些实现会将预填充和解码解耦到不同的GPU中,并为每个阶段定制并行策略。这自然解决了上述两个问题:
- 预填充和解码之间没有干扰,使得两个阶段都能更快地达到各自的SLO。
- 资源分配和并行策略解耦,从而为预填充和解码量身定制优化策略。
当然,也有研究人员对分离策略提出了质疑,认为尽管PD分离提供了灵活性,但是导致了严重的GPU资源浪费的问题。具体来说,运行计算密集型Prefill阶段的GPU的HBM容量和带宽的利用率较低。内存密集型的Decode阶段则面临算力资源利用率低的问题。因此,另外一个流派强调需要融合或者算力迁移(比如,将 Decode 阶段内存密集的 Attention 计算操作卸载一部分到 Prefill 节点上执行),我们会在后续文章进行详细分析。
2.2.4 内存管理
此处可以从两个维度进行思考。
首先,我们从系统维度来看。目前很多推理框架实现中存在显存碎片化和显存过度保留的问题,显存利用率不高。由于序列长度具有高度可变和不可预测的特点,因此,KV缓存的内存需求是未知的,很难提前为KV cache量身定制存储空间。因此,很多推理框架会预先为一条请求开辟一块连续的矩形存储空间。然而,这样的分配方法很容易引起“gpu显存利用不足”的问题,进而影响模型推理时的吞吐量。因此,系统级别的内存管理会通过架构创新优化内存使用,如虚拟内存适配、智能前缀共享和层感知资源分配,确保缓存高效存储与访问。我们会在本文介绍。
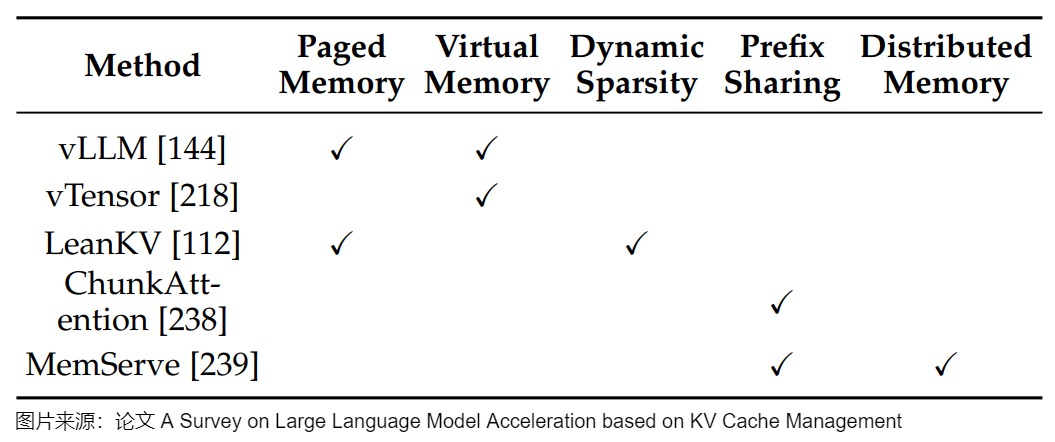
下图给出了综述论文对于现有内存管理方案的一些总结。以vLLM与PagedAttention和vTensor为例的架构设计,采用了经典的操作系统原理,创建了灵活的动态内存分配系统,通过复杂的映射和虚拟内存抽象优化了物理内存的使用。ChunkAttention和MemServe等前缀感知设计通过组织数据结构来实现高效的缓存重复数据删除和共享公共前缀,从而进一步优化了这种方法,从而提高了内存利用率和计算效率。这些创新共同展示了通过内存管理显著增强LLM服务的潜力。
其次,论文“Thus Spake Long-Context Large Language Model”提出了把KV Cache看作是记忆管理的一部分,这是从业务角度来看。尽管KV缓存优化在实践中努力实现更长的上下文,但本质上,它是在效率和性能之间寻求平衡。缓存优化并没有试图突破LLM的能力上限,因为它并没有改变上下文信息的组织形式。基于标准KV缓存机制的长上下文LLMs仍然面临一些限制,包括只读访问和一次性读取所有信息的需求,这使其不适合更复杂的场景。这促使将记忆管理纳入LLMs,将KV缓存视为一种特定的记忆实例。这种记忆管理相较于KV缓存最直观的改进在于其更加灵活的访问方式,避免了一次性读取全部KV缓存。MemTrans将预训练阶段的KV缓存存储在外部存储中,以便在推理时提供更相关的信息。MemLong将这一概念扩展到长上下文,通过存储上下文片段的KV缓存,并根据相关性检索KV对来指导推理。本文不对此方面进行解读。
2.2.5 调度
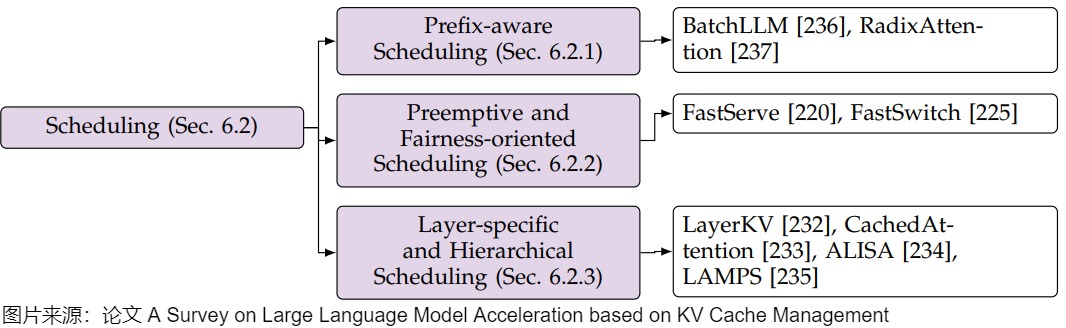
这部分主要是针对KV Cache特点实施的一些调度策略,主要是三种途径:
前缀感知调度策略。通过前缀感知方法以最大限度地提高缓存重用率,以BatchLLM和RadixAttention为代表;
抢占式和面向公平的调度。采用抢占式技术实现公平上下文切换以FastServe和FastSwitch为代表。
特定于层的分层调度方法。针对层的特点进行精细化缓存控制,以解决多样化优化目标。LayerKV和CachedAttention是典型代表。
下图展示了这些分类。
另外,PD分离后,如何最大效率的调度Prefilling服务器和Decoding服务器是进一步优化的核心所在。这里有两个要点:
- 如何优化KV Cache的传输。因为相对计算资源来说,存储更廉价和充足,所以KV Cache会存储在系统的不同部分中,然后通过网络进行传输。
- Decoding阶段如何最大化batch(但是太大的batch size也会导致平均单个token的生成时间变长)。
2.3 按照阶段来优化
下图是论文"Keep the Cost Down: A Review on Methods to Optimize LLM’s KV Cache Consumption"提出来的划分方式,
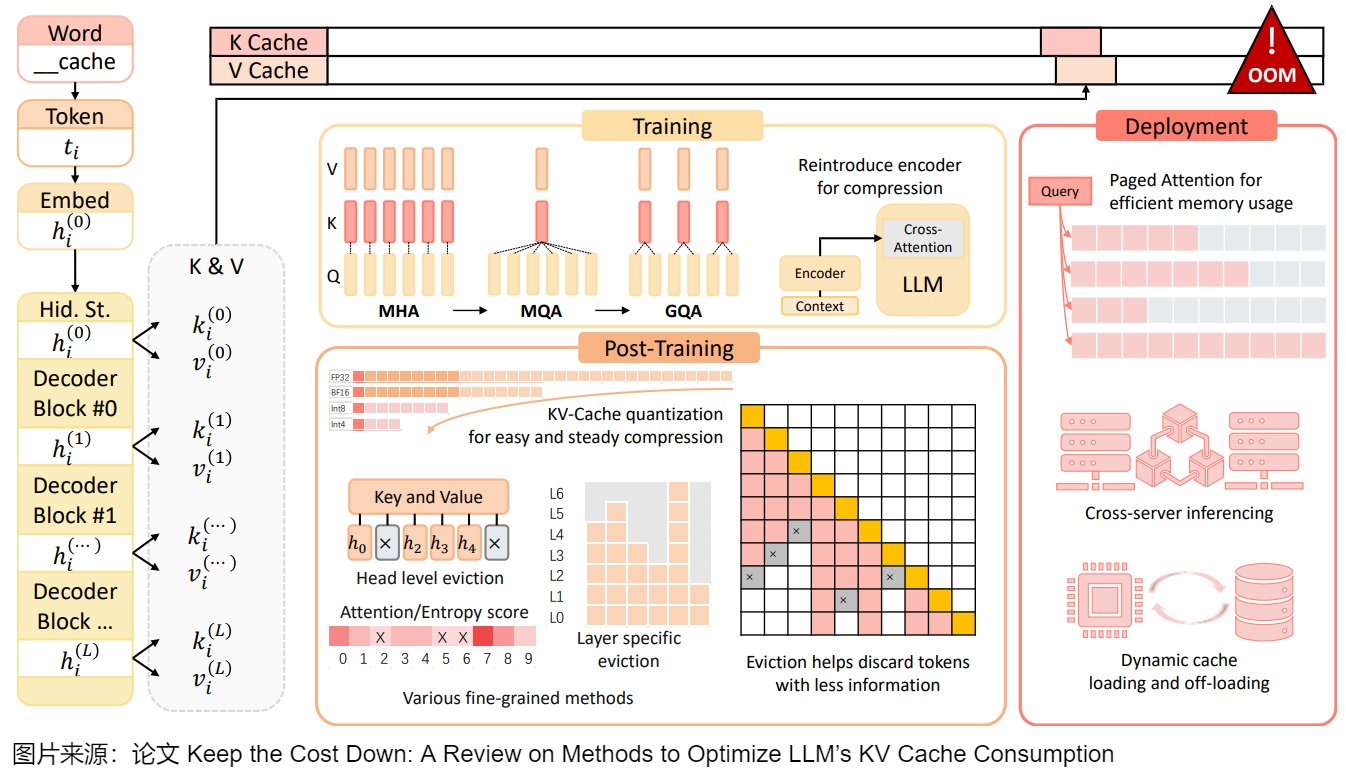
该论文按LLM的时间顺序展开,从训练阶段到部署阶段,再到post-training(后训练)阶段对KV Cache的优化方案进行了划分。
- 训练阶段主要包括可用于模型预训练的KV Cache压缩方法。在这个阶段,模型具有最大的可塑性。此阶段的主要调整是模型架构,它在保留Attention的优秀特性的同时,将生成的键和值向量的大小减小到四分之一甚至更小,也可以改变架构,完全放弃具有二次复杂性的注意力。这些方法通常是最有效的,但它们不适合施加在现有模型上,以及计算量较低的场景。
- 部署阶段主要包括用不同的框架来优化KV Cache。这些方法不会对KV Cache本身进行大量修改,但可以在相同的环境中显著优化其效率。
- post-training阶段主要包括针对KV Cache的实时优化方法,主要包括三种方法:删除、合并和量化。在推理过程中,从模型输入提示级别到嵌入级别,再到KV Cache级别,都可以进行压缩优化。
0x03 按照公式优化
我们接下来通过具体案例来剖析如何依据以下公式的特点来进行优化。
\(batch\_size \times sequence\_length \times head\_number \times head\_dimension \times layer\_number \times kv\_bits \times 2\)
3.1 减少注意力头的数量
前文提到,单个 Token 的 KVCache 由四大因素决定:Layers、NumHead、HeadDim、以及 KVCache 数据类型决定的。所以压缩每个 Token 的 KVCache 大小就有四大方向,我们首先看看如何通过减少NumHead来进行优化。
对于给定的模型架构,模型大小主要受控于层数和头数,减少注意力头的数量可能意味着选择一个更小的模型。然而,如果仔细观察,我们会发现只需要减少键头和值头的数量,因为查询头的数量不会影响KV缓存的大小。与层数维度优化类似,减少头数会显著影响LLMs的表示能力。为了保留性能,头数维度优化通常依赖于共享策略。这正是MQA(多查询注意力)和GQA(分组查询注意力)架构的核心思想。这些多头注意力(MHA)变体的唯一目的是用更少的注意力头训练基础模型,从而减小KV缓存的大小。然而,这些模型通常在针对特定任务进行微调后使用。也有一些KV Cache压缩的算法会去profile哪些head对生成更加重要,进而为它们分配更多的cache空间,那些不重要的就减少空间或者干脆不分配。
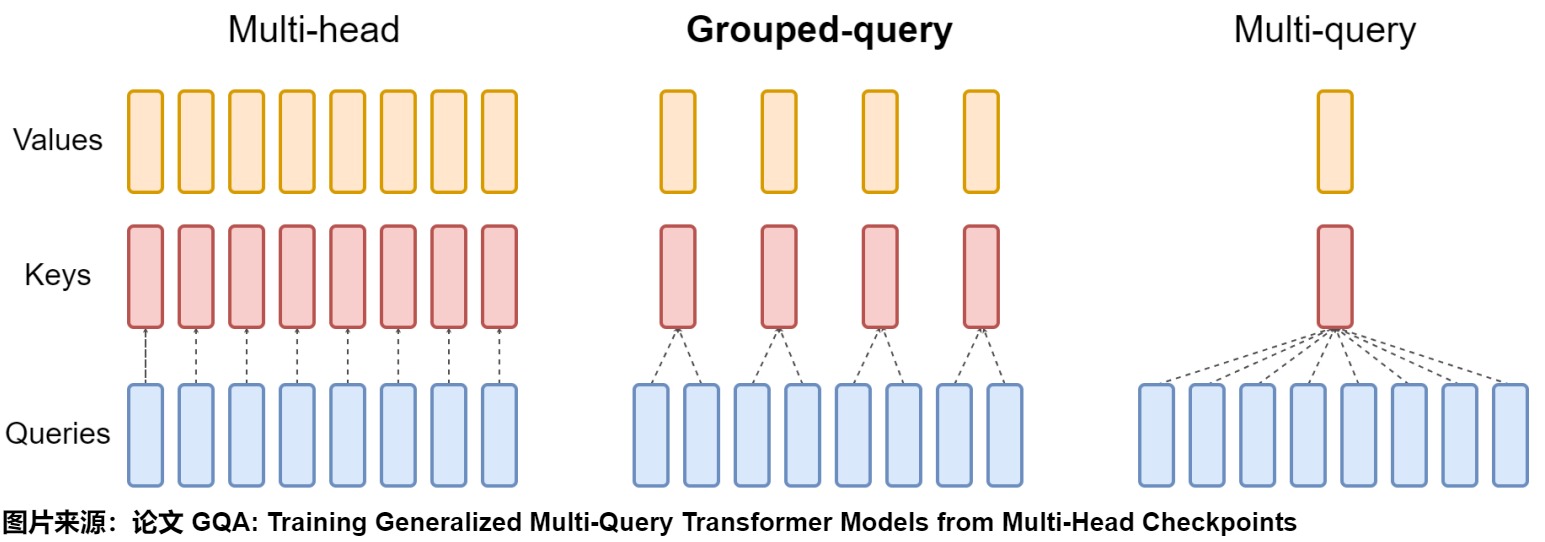
此外,微调现有模型还可以进一步优化头数的大小。例如,SHA计算头权重矩阵之间的余弦相似度,并将相似的头分组以共享单个KV缓存。DHA采用质心对齐方法计算头之间的相似度,通过线性融合相似头的KV缓存,有效地将MHA压缩为GQA。
我们将在后续专门用一篇文章来介绍MQA和GQA。
3.2 减少每个参数占用的字节
此方向就是量化技术在KV Cache中的应用。KV Cache量化不仅能显著降低推理过程中的显存占用,更重要的是在压缩显存占用的同时,能够很好地保持模型的推理性能。
我们会在后面介绍量化时候统一进行学习。
3.3 减少注意力头维度
在很多模型家族中,无论模型的大小如何,注意力头的隐藏维度都可能保持不变。因此,难以通过降低注意力头维度来优化KV Cache,除非更换模型。而且也可能是因为隐藏维度大小已经是128,如果再缩小会影响效果。
想要减少头维度,一种可能的方法就是低秩分解(Low-Rank Decomposition),毕竟LORA就是利用的这个思想。DeepSeek V2的MLA就引入了类似LoRA的想法,有效地减少了KV头的大小。ECH对分组的头权重矩阵应用基于SVD的低秩分解,实现了与GQA类似的KV压缩效果,但不同的是,它不采用平均融合。Neurocache对头矩阵应用低秩压缩,并在注意力计算中使用最相似的缓存。
而且也有针对/利用channel的稀疏化。比如Double Sparsity 将 Token 稀疏性和 Channel 稀疏性相结合:
- Token 稀疏性侧重于利用重要的 Token 来计算 Attention,也就是 Sequence 维度的稀疏。
- Channel 稀疏性是使用重要的 Channel 来识别重要的 Token,也就是 Hidden 维度的稀疏。
我们将在后续文章单独介绍MLA。此处介绍针对channel的稀疏化。
3.2.1 Double Sparsity
论文”Post-Training Sparse Attention with Double Sparsity”在针对长序列场景使用 Token 稀疏化的同时,也额外引入了 Channel 稀疏化,将 Token 稀疏性和 Channel 稀疏性相结合来获得不错的加速。
洞见
作者的关键见解是:Channel 的稀疏性通常是相对静态的,可以通过离线校准的方式来执行,从而能够准确和高效的识别重要的 Token,使推理更高效。此外,这种方法可以与 Offload 结合,以显著减少内存占用。
方案
Double Sparsity是一种训练后稀疏注意力机制。其整体的方案比较简单。
Offline Calibration
首先通过离线的方式(Offline Calibration)识别出重要的 Channel。
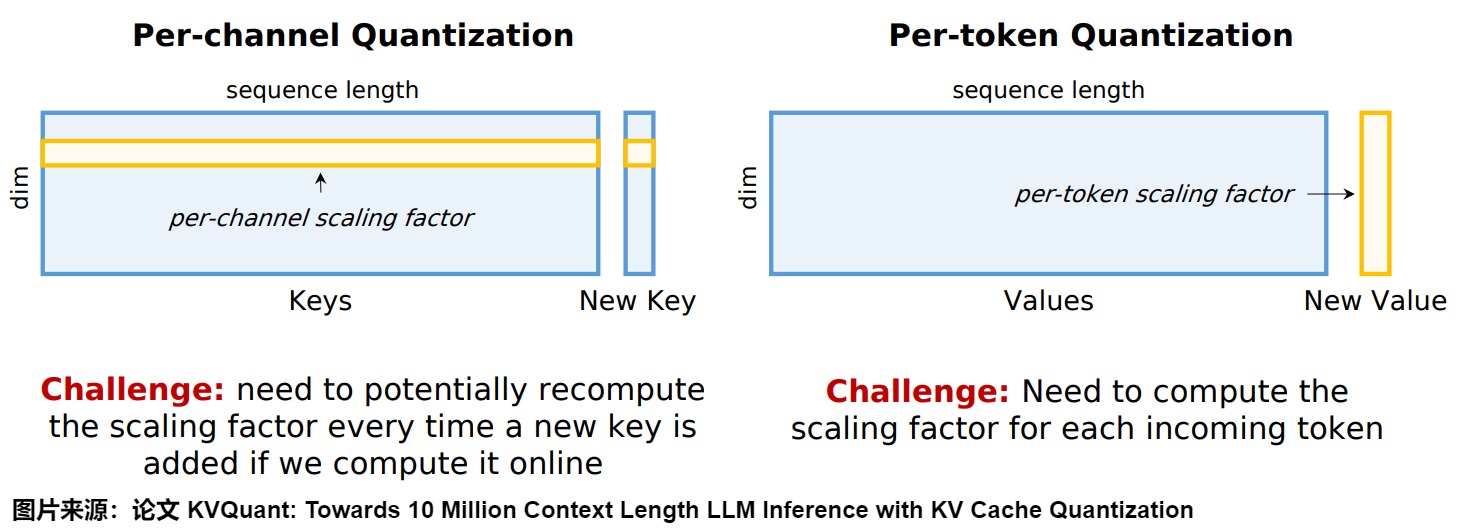
具体而言如下图所示,借鉴 AWQ 中识别重要 Channel 的方式,使用少量样本数据,通过 Offline 的方式识别哪些 Channel 更加重要。这里有几种不同的策略:
- Activation Outlier:根据 Activation 中的 Outlier 来识别重要的 Channel,红色部分。
- Q-Outlier:根据 Query 中的 Outlier 来识别重要的 Channel,绿色部分。
- K-Outlier:根据 Key 中的 Outlier 来识别重要 Channel,蓝色部分。
- QK-Outlier:根据 Query * Key 来识别重要 Channel,紫色部分。
实时计算
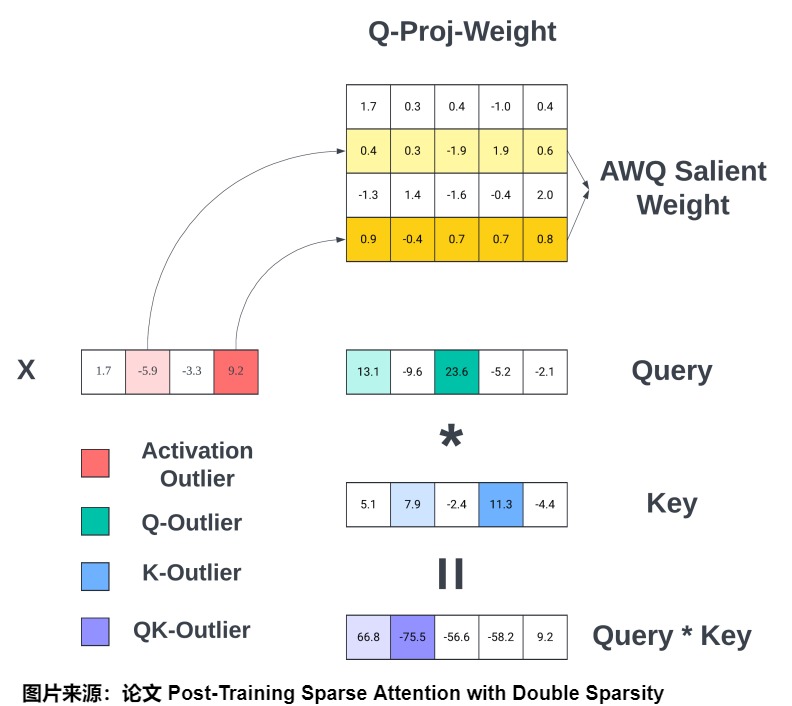
离线操作之后,会进行实际计算。具体分为 3 步:
- 根据重要 Channel 的 Index 提取 Query,同样要连续存储。
- 使用稀疏但连续存储的 Query 与 Key Cache 计算 Attention Score。
- 根据 Attention Score 选出 Top-k 的重要 Token(Key/Value Cache),然后使用这些重要的 Token 进行 Attention 计算。
如下图所示。
Double Sparsity-Offload
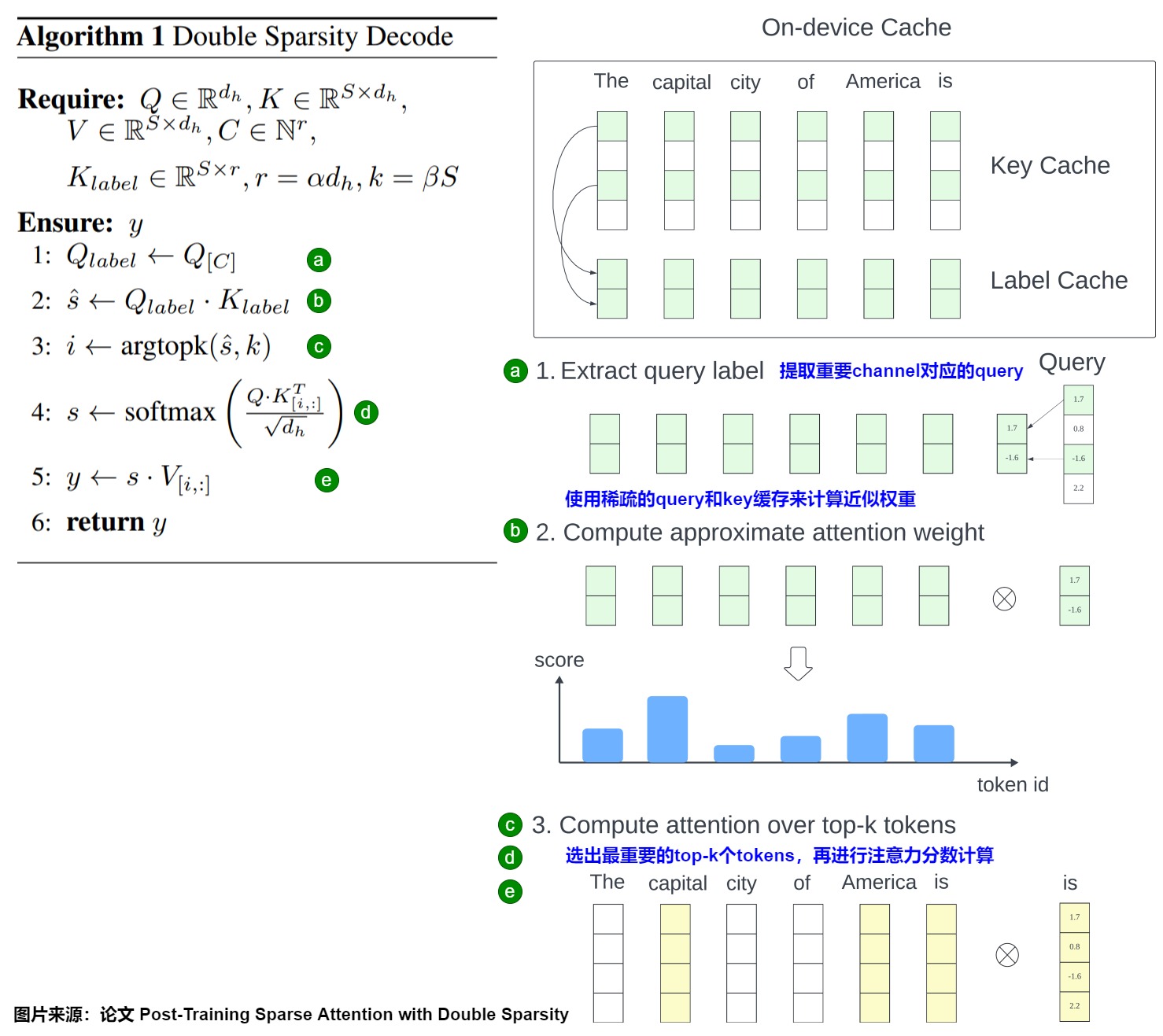
从上面也可以看出,Double Sparsity 方案虽然可以在一定程度上减少显存 IO,但需要额外存储 Label Cache,实际上是增加了显存占用。为了解决这个问题,作者提出了将全量的 Key/Value Cache Offload 到 CPU 内存中,在需要的时候动态的加载到显存中,也就是 Double Sparsity-Offload。
然而,如果每次使用 Label Cache 获得 Top-k 的 Token 后再去加载对应的 Key/Value Cache 到显存中,其延时可能比较大,并且无法与计算 overlap。为了解决这个问题,作者引入了 Double Buffer,其核心思想是:在计算当前 Transformer Layer 的时候可以异步的预取下一个 Layer 的相关 Token 的 Key/Value Cache。为什么可以提前加载下一层的 Key/Value Cache 呢?因为作者对比相邻层的 Attention Head 发现,除了前两层以及最后两层外,后续相邻层的相似性都很高,甚至达到 95% 以上,因此也就可以使用当前 Layer 来近似下一个 Layer。
3.4 减少Layers
3.4.1 总体思路
需要注意的是,此处不是真正的减少层数,而是只缓存模型部分层的KV,比如,逐层仅保留关键的上下文键和值,合并相邻层的KV Cache等。
对于层维度,基本假设是,一些任务可能不需要完整深度的计算,在预填充过程中跳过一些层可能会同时减少预填充的浮点运算次数和KV缓存的大小。我们接下来通过几个实际案例进行学习。
3.4.2 LayerSkip
LayerSkip的总体思路是跳过一些层然后验证,其实也是投机推理的思路。在训练阶段,LayerSkip对不同层应用不同的丢失率(dropout rate),所有Transformer层共享同一出口的提前退出损失(early exit loss)。在推理阶段,因为已经通过训练提高了早期层的提前退出准确性,因此无需增加辅助层;此外,LayerSkip引入一种自我推测解码方法,在早期层退出后,使用剩余层进行验证和纠正,从而减少内存占用并提高效率。
动机
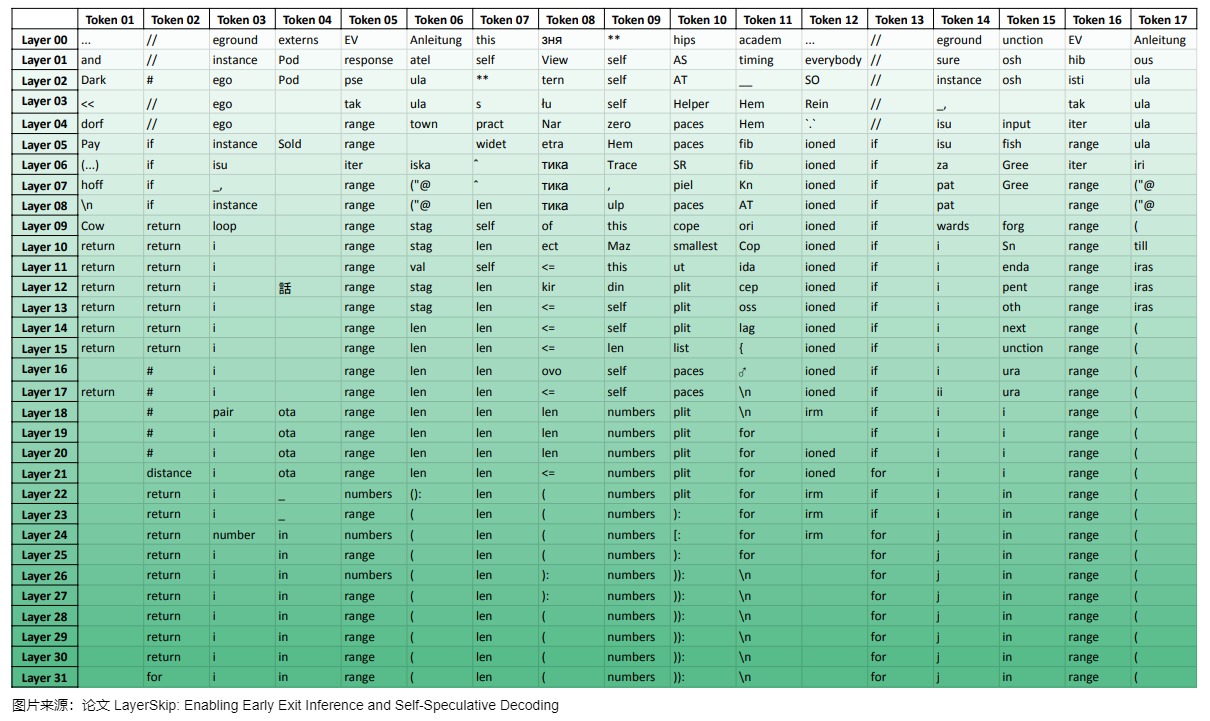
LayerSkip 作者在设计 LayerSkip 前做了一个实验,观察整个 Transformer 每一层到底完成什么事情。因为在压缩前,需要问自己一个问题:需要压缩的对象是否存在冗余信息?是否需要全量执行?如果可以,应该怎么在保证模型效果不会有大幅降低的前提下提升推理的性能?所以,LayerSkip实验的目的就是找出最关键的层。
作者使用 LLaMA 7B 测试 HumanEval 代码测试集来测试代码生成。作者在 LLaMA -7B 每层 TransformerLayer 后都接入 LM Head 层,统计整个生成过程中,每一层 TransformerLayer 生成每一个 Token 的概率分布。实验举例如下。

实验统计结果如下图所示。通过图上表格可以观察到两个现象:
- 前面层生成的结果大部分和最终结果几乎毫无关系,主要原因是前面的层的权重和 LM Head权重没有适配过,所以生成效果很差;越到后面的层,生成的结果越接近最终结果,最终不断收敛到最终结果。而且,中间层有时会“改变主意”,例如,在第07层时模型早已预测出标记“range”,但在第22至26层间改变了主意,之后又重新确定为“range”。
- 大部分情况下不需执行所有层,提前退出计算也可获得最终正确的结果。作者发现,大多数时候,最终的 token 在最终前几层就已经被预测出来。在32层的LLM中,一个token平均需要23.45层被预测出来。如果有一个零计算消耗的预测器能够完美预测在哪一层退出,我们可以降低26%的计算量。因此,有必要使LLM用更少的层来预测每个token以及如何“改变主意”。作者希望能够降低对模型后面层的依赖,只用后面这些层来预测困难的 token。避免像上面的例子中,用了32层来预测 for 循环的 “for”这种情况。
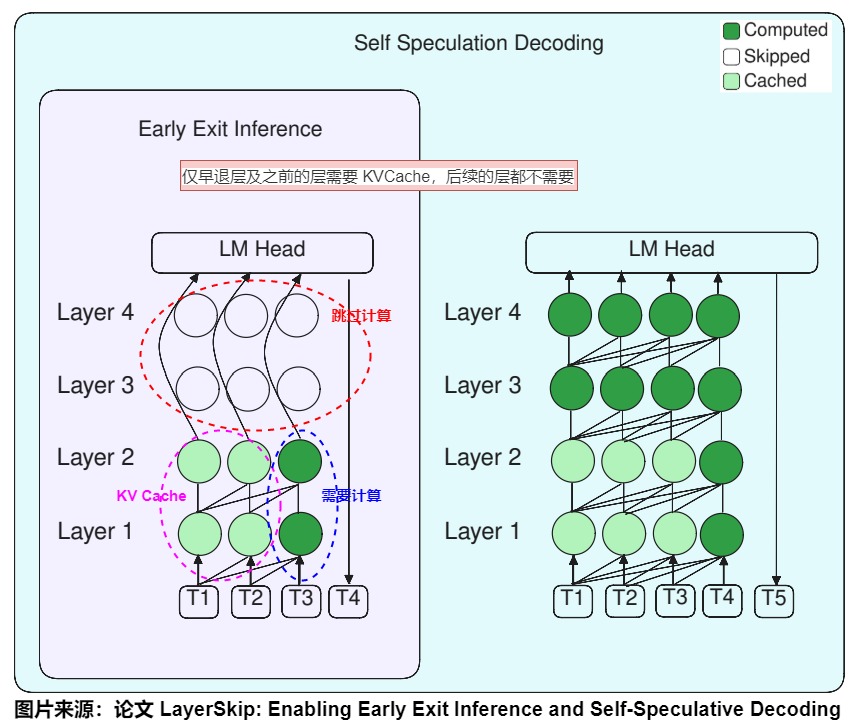
方案
所以,针对以上两个现象,作者提出 LayerSkip,利用“早退”+ 投机采样优化推理性能。其中,早退层(Early-exiting)是在模型的非最终的ransformer层进行 Unembedding 操作,相当于跳过了剩余的Transformer层。具体贡献为:
- 训练侧:早退层没有和 LMHead 适配,导致生成效果很差,所以在训练时候需要前面的层适应早退,让模型具有一定的直接生成 Token 的能力。具体而言,训练时针对早退层添加了一个 Early Exit Loss,增强早退层的生成能力。
- 推理侧:采用自投机解码策略,利用早退层推理速度快的特点来生成多个 draft tokens,然后验证阶段跑全量层,将通过验证的 draft tokens 返回。下图右侧所示的是自投机解码策略整体架构。浅绿色节点表示 缓存到显存的状态 KVCache,深绿色节点表示需要进行计算,透明节点表示跳过计算。通过下图可知,仅早退层及之前的层需要 KVCache,后续的层都不需要,所以 LayerSkip 有两大优化:加速预测性能;降低显存开销,潜在提升服务最大吞吐。
3.4.3 YOCO
LayerSkip主要是用“裁剪”层方式,仅用部分层的 KVCache 完成全量结果的计算。除了“裁剪”层方式,还可以通过“共享”层方式压缩 KVCache,或者说是跨层推理( Cross-Attention 机制)。
论文”You Only Cache Once: Decoder-Decoder Architectures for Language Models“提出了YOCO方案,进行KV Cache跨层共享。选择固定的前几层来产生KV Cache。
YOCO 构建了一个由两个解码器模块组成的双解码器架构:自解码器和交叉解码器。自解码器有效地对全局键值缓存进行编码,而交叉解码器通过交叉注意重用这些缓存。整个模型的执行过程和 Decoder Only 的 Transformer 模型类似,但选择固定的前几层来产生KV Cache,只保留一层全局的 KV Cache。YOCO的计算流程还使预填充能够提前退出,从而在不改变最终输出的情况下实现更快的预填充阶段,降低GPU内存使用。 这种设计可以大大降低 GPU 显存的需求,同时保持了全局注意力能力。
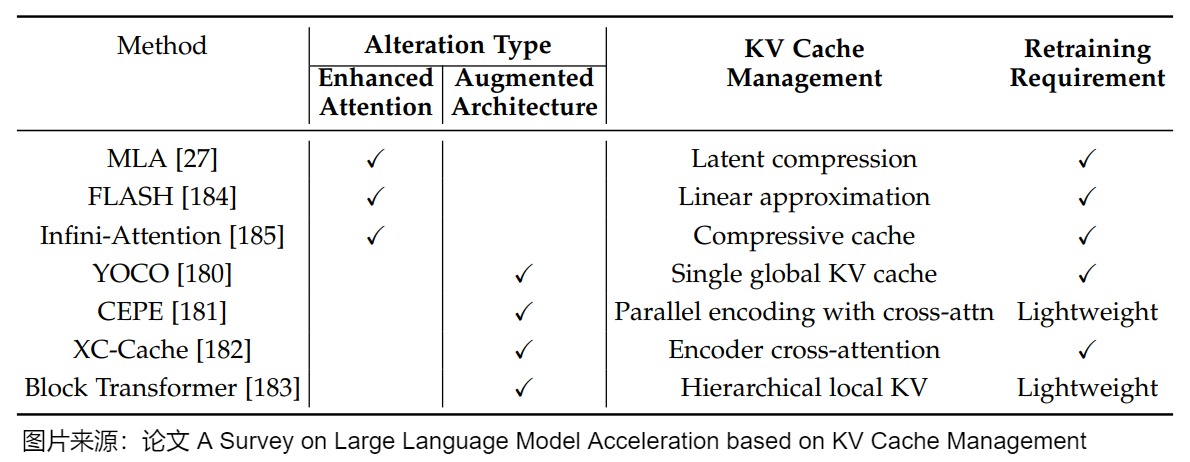
下图给出了论文“A Survey on Large Language Model Acceleration based on KV Cache Management”对层内模型改造方案的总结,可以看到YOCO的特点。
模型架构
与 LLaMa 等 Decoder Only 模型不同,YOCO 采用 Decoder-Decoder 模型架构,之所以命名为Decoder-Decoder架构,是因为这两个Decoder的含义不是完全一致的。模型架构如图所示。
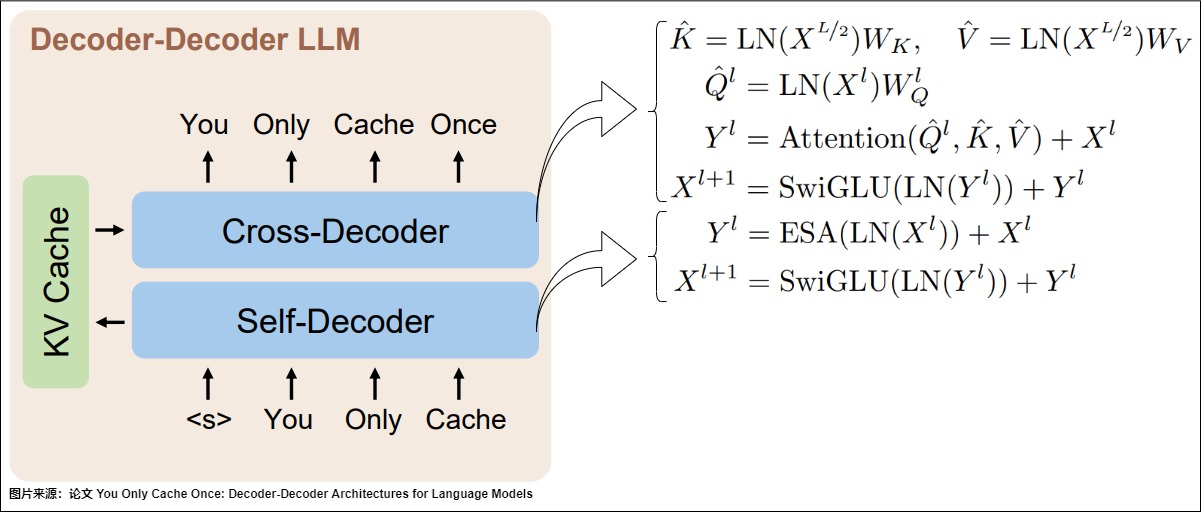
YOCO 的两大Decoder是:负责产生global KV Cache的Self-Decoder 和 负责使用global KV Cache的Cross-Decoder。
Self-Decoder的特点如下:
- YOCO 的前 L/2 层由 Self-Decoder 层堆叠,由最后一层(第 L/2 层)Self-Decoder 层输出 global KV Cache,也就是只有一层有全局 KV Cache。
- Self-Decoder和常见的Decoder是一样的。但是,如果仅是将后一半的 Transformer Block 替换为 Cross-Decoder,那么显存节约和计算节约的上限也是确定的,最多节约一半。因此 Self-Decoder 的设计也是非常关键的,要起到大幅节约显存和降低计算量的目的。YOCO选择了Efficient Self-Attention,比如Slide Window Attention和YOCO作者之前其它论文提出的 Multi-Scale Retention。其只用保存窗口内的 KV Cache 即可。其计算量和 KV Cache 大小与窗口大小或 Chunk Size 有关,而不是与序列长度有关。
- Self-Decoder产生的KV Cache会直接被后续的Cross-Decoder使用。
Cross-Decoder的特点如下:
- YOCO 的后 L/2 层由 Cross-Decoder 层堆叠。
- Cross-Decoder本身不产生KV Cache,而是由第一个 Cross-Decoder 层加载使用Self-Decoder产生的KVCache。也就是后续所有 L/2 层的 Cross Attention 的 KV Cache 都是相同的。在 Decoding Stage,每个 Step 中都会把第 L/2 层新生成的 KV Cache 扩充到 Global KV Cache 中。
- Cross-Decoder使用KV Cache做交叉注意力。
训练和推理
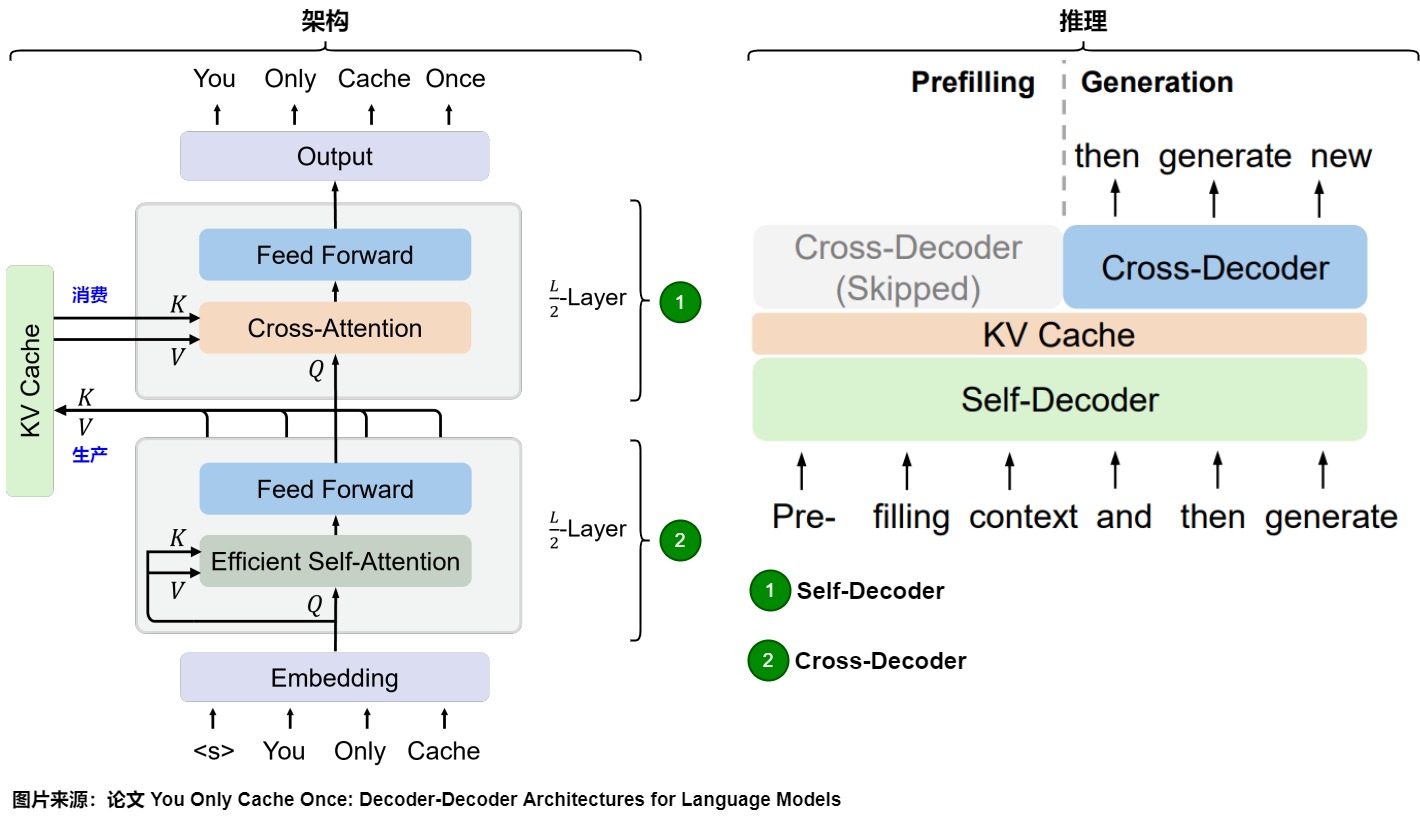
由于只有一层 KVCache,所以推理时 Prefill 和 Decode 流程均和传统的 Transformer 不同。YOCO在推理阶段,可以节省大量Prefill的耗时,
- Prefill 阶段:基于YOCO的特性,Prefill阶段可以跳过首Token的生成,也就是跳过Cross-Decoder。在传统的 Transformer 结构的模型中,每一层都会计算 KVCache,所以在 Prefill 阶段每一层都会运行,并且生成 KVCache;而 YOCO 只有 Self-Decoder 才会生成 KVCache,并且生成下一个 Token 取决于当前 Token 的值,所以在 Prefill 时所有输入的 Token 经过 Self-Decoder 计算后,仅最后一个 Token 需要运行后续 Cross-Decoder,完成首 Token 的生成。
- Decode 阶段:在该阶段,模型输入只有当前一个 Token,输出下一个 Token。所以在 Self-Decoder 仅对当前Token 进行 Attention 计算,类似对一个 Token 进行 Prefill,生成该 Token 的 KVCache,然后在 Cross-Decoder 进行Decode Attention计算,生成下一个 Token。
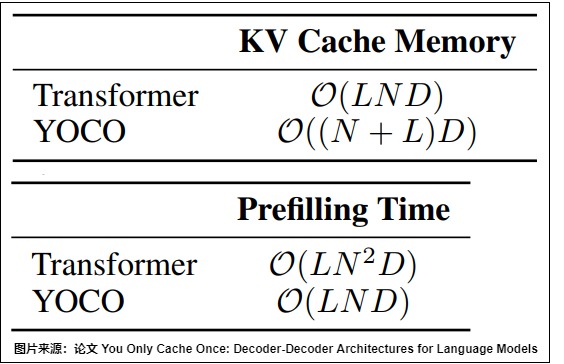
效果
下图为 YOCO 与原始 Transformer 相比 KV Cache 的占用对比,以及计算量对比,其中假设序列长度为 N,transformer层数为 L,D是隐状态维度。
- Prefill阶段的KV Cache显存需求从O(LND)下降到O((N+L)D)。其中,O(ND) 对应 Global KV Cache,只有一层,前 N/2 层使用了滑动窗口 Attention 或 Multi-Scale Retention,对应的 KV Cache 为 O(DL)。
- Prefill耗时则从O(LN^2D)下降为O(LND),即耗时从N平方复杂度变为线性复杂度。因为Prefill 阶段只用计算前一半的 Self-Decoder Layer 来产生 KV Cache,后一半的 Cross-Decoder Layer 直接生成即可,所以Prefill 阶段计算量降低一半。
3.4.4 CLA
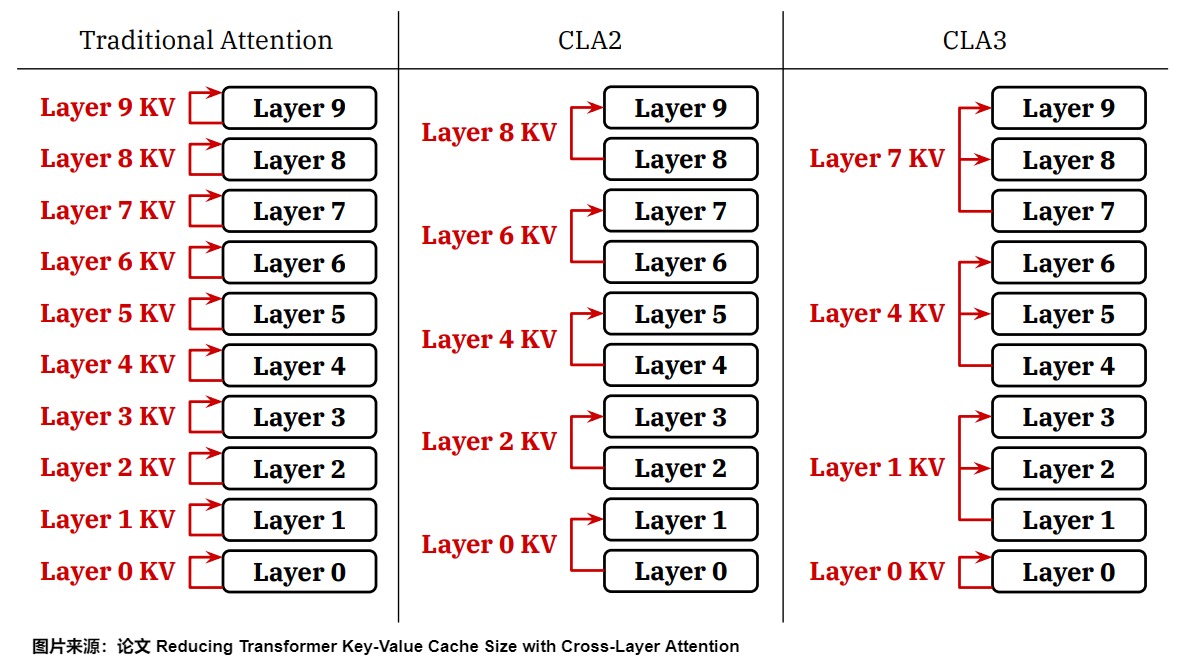
CLA(跨层注意力):该方法将产生KV Cache的层交替分布在模型不同深度的层,然后通过在相邻层之间共享键和值头来扩展GQA和MQA的思想,进一步减少了KV缓存中的冗余。与MQA相比,CLA可以再减少2倍KV Cache大小,在不改变计算复杂性的情况下显著提高了内存效率。
论文”Reducing Transformer Key-Value Cache Size with Cross-Layer Attention“提出了CLA( Cross-Layer Attention),即KV Cache跨层注意力,和YOCO思路不谋而合。和YOCO不一样的是,CLA并不是选择固定的前几层来产生KV Cache(比如YOCO,使用的是前L/2层),而是将产生KV Cache的层交替分布在模型不同深度的层,然后邻近层复用附近层产生的KV Cache进行Attention计算。
CLA可以选择多种跨层共享KV Cache的方式,比较灵活,也比较通用。如下图左所示。最简单的方式就是隔层共享,称作 CLA2。实际也可以每 3 层共享,称作 CLA3,如下图右所示。其中C表示多少层共享一份KV Cache,比如C=2表示CLA2模式,相邻的2个层共享一份KV Cache,则KV Cache总量可以节省一半。即,CLA2 显存减小 2x,CLA3 显存减小 3x。
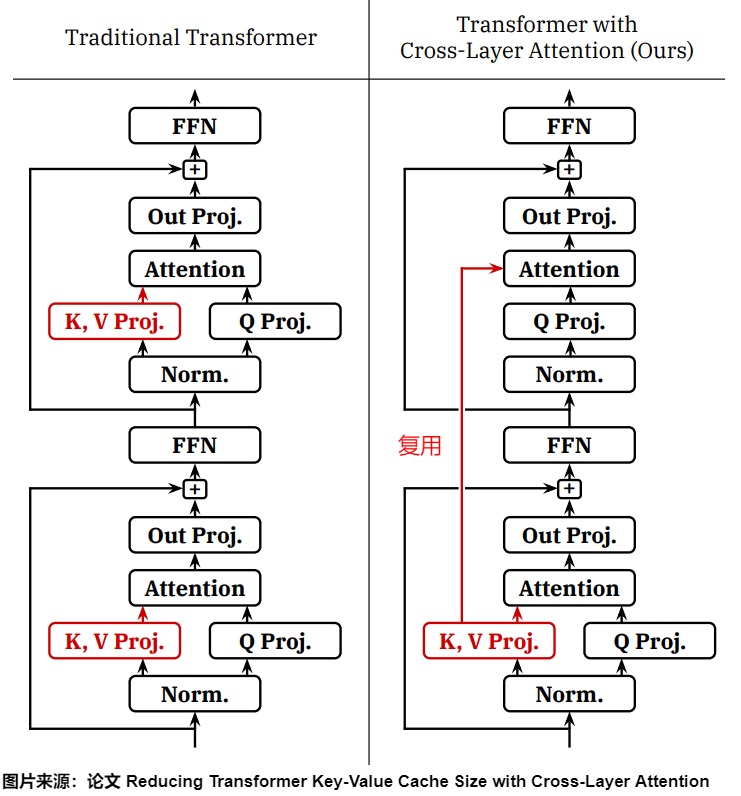
下图使用传统注意力设计的Transformer(左)和使用CLA的Transformer(右)中两个连续层的示意图。当使用传统注意力时,每一层都会计算自己单独的K和V激活,这些激活必须在自回归解码期间按层缓存。当使用CLA时,CLA仅计算模型中一部分层的键/值预测;没有键/值投影的层中的注意力块重用了先前层的KV激活。只有具有键/值投影的层的子集对KV缓存有贡献,与在每一层中应用单独键/值预测的传统架构相比,CLA可以减少内存占用。
另外,CLA提供的是一种通用的跨层KV Cache共享思路,其本质上和MQA/GQA等层内KV Cache共享的方式是不冲突的,即MQA和GQA是在单个层内跨查询头共享键/值头,而CLA为层间KV Cache共享。因此,CLA可以和MQA/GQA结合一起使用。
3.4.5 MLKV
MLKV(多层键值/Multi-Layer Key-Value)引入了一种跨多个transformer 层的简单KV头共享机制。MLKV在一个层内使用与MQA相同的单个KV头,但它也与多个层共享这个KV头。这种极端策略将缓存大小减少到正常GQA策略的近1%,实验表明MLKV仍然具有相当的性能。
从创新点上看,MLKV和YOCO都是CLA的特例。MLKV和CLA一样,都是做跨层的KV Cache共享,但MLKV主要是对MQA做更加极端的扩展,也就是MQA+跨层KV Cache共享,具体如下图所示。
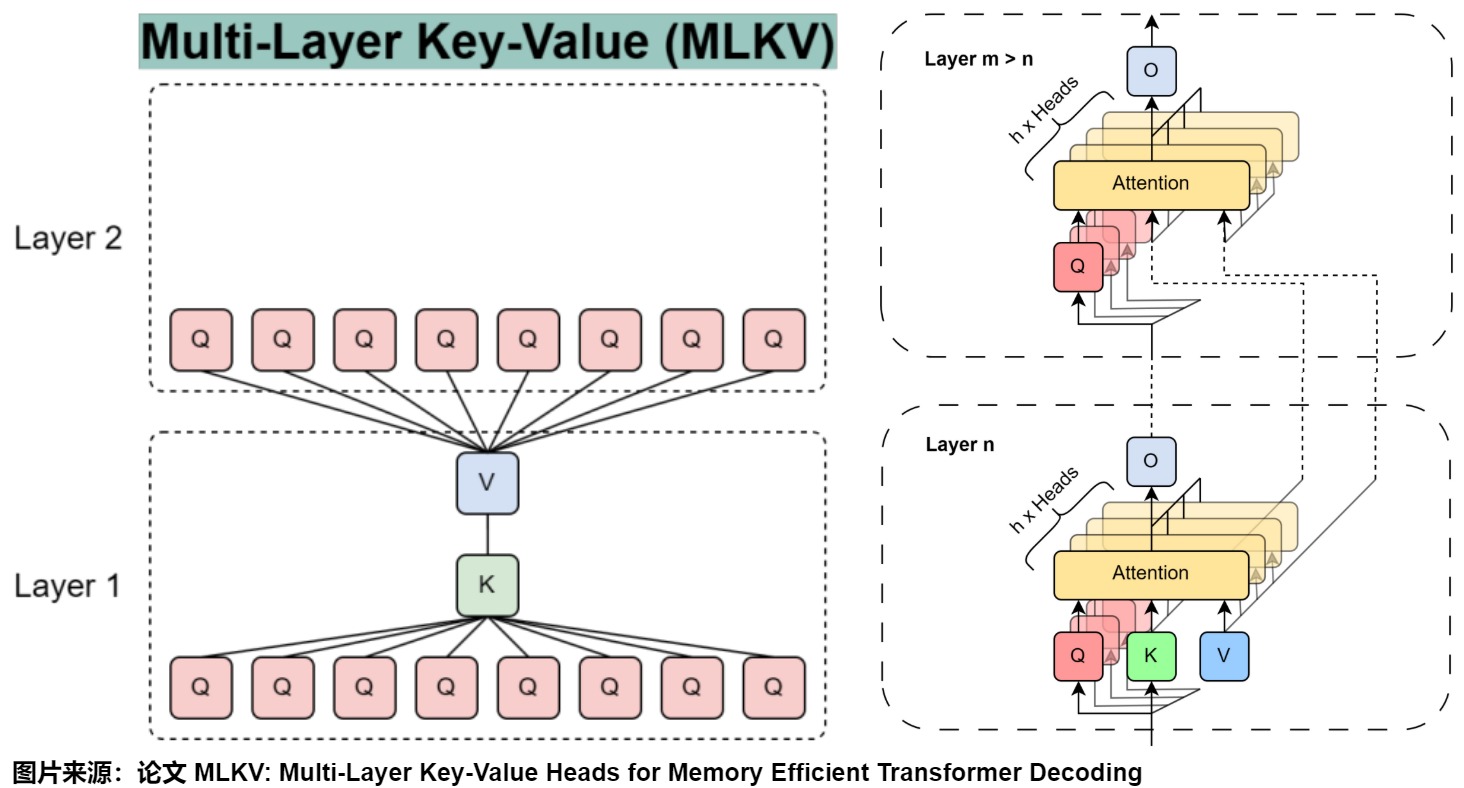
下图则给出了MLKV和其它几个方案的区别。
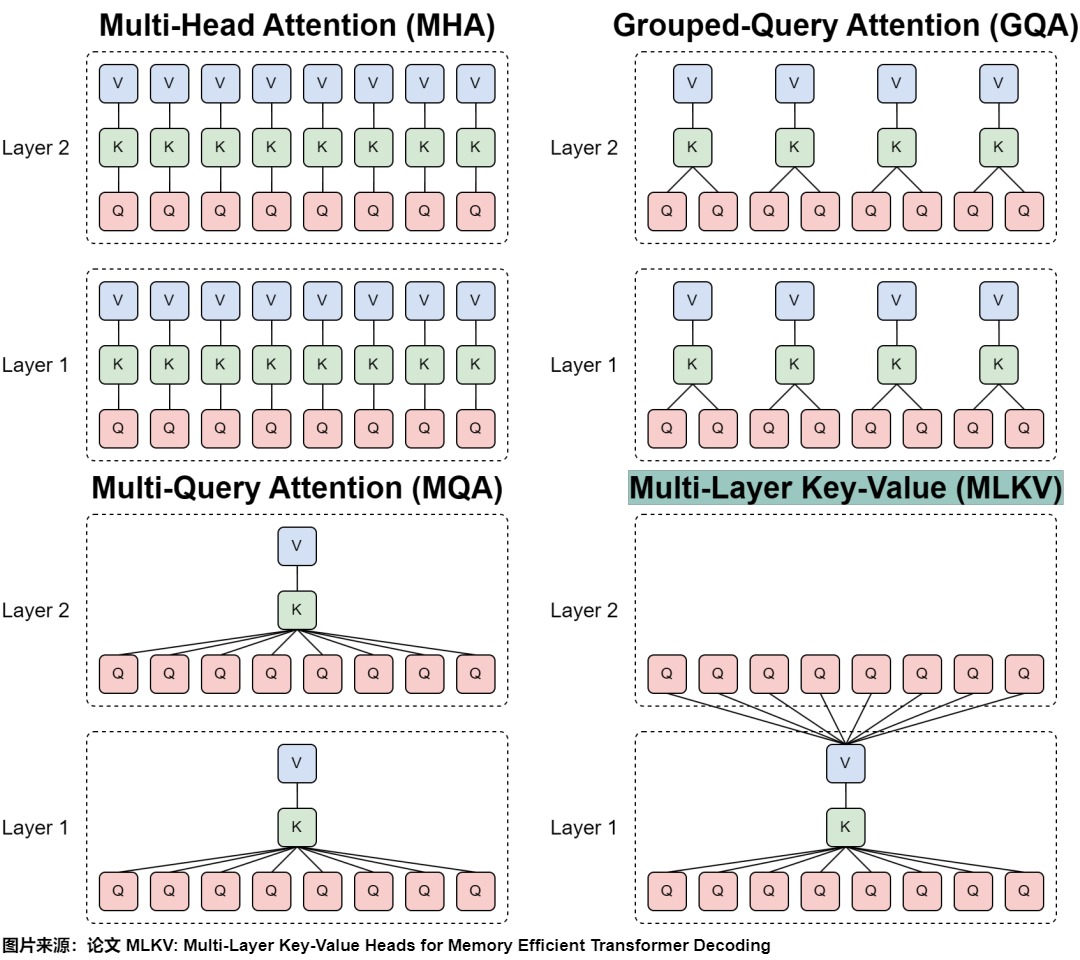
- MHA:原始的 Multi Head Attention,每一层的每一个 Head 都有独立的 K 和 V。
- MQA:Multi Query Attention,每一层的所有 Head 共享 K 和 V.
- GQA:Grouped Query Attention,MHA 和 MQA 的折衷,每一层的 Head 分为多组,每一组共享 K 和 V.
- MLKV:多个层共享 K 和 V,并且可以与上述 MQA 和 GQA 兼容。
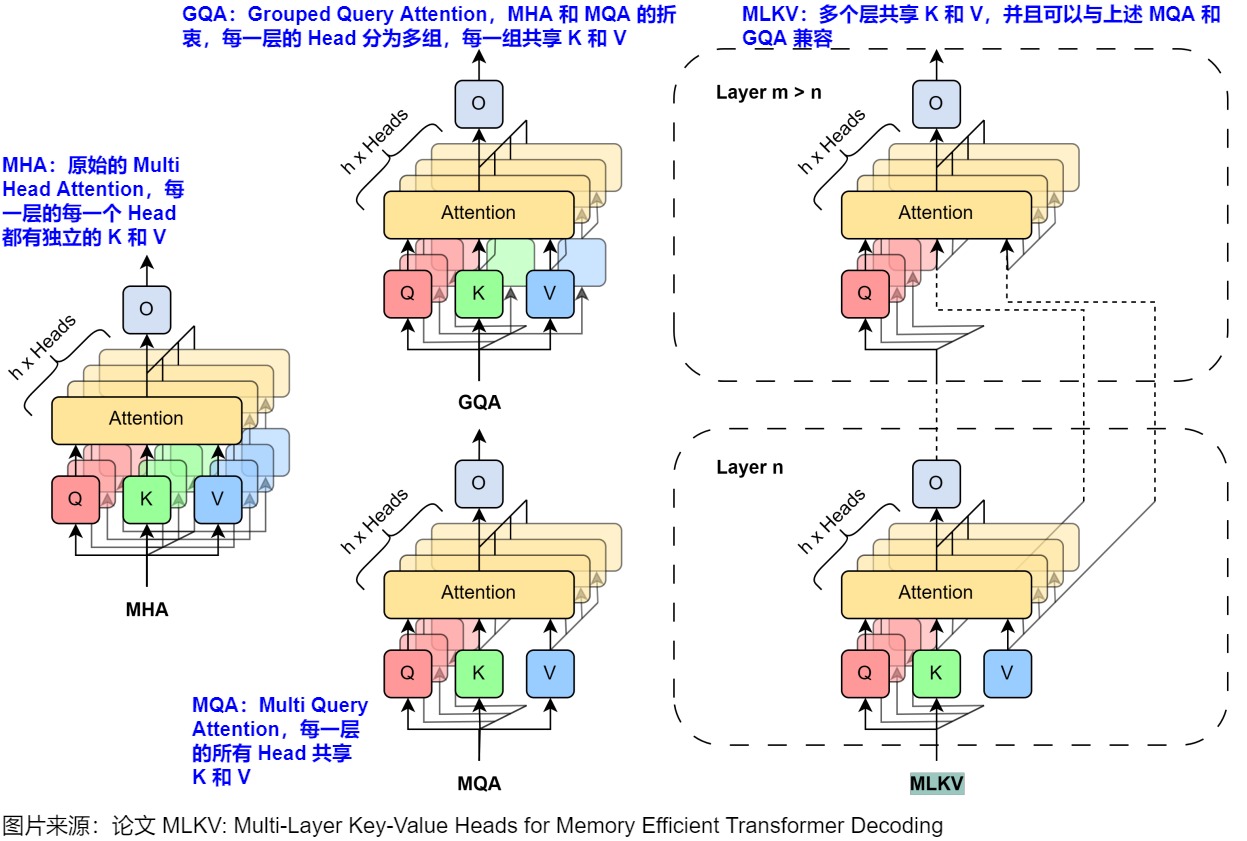
下图则做了进一步细化。
3.5 减少序列长度
因此这个方向内容较多,我们将在本文的下一节来介绍如何减少序列长度。
0x04 按照特性进行优化
我们在本节来对“按照特性进行优化”进行深入学习。
4.1 针对Prefill特性进行优化
相比于更耗时的Decode阶段,Prefill有一个更加突出的问题:长上下文。过长的prompt会给显存带来压力。因此,研究人员针对此特性进行相关优化。
4.1.1 Chunking
Chunking把prompt切成若干chunk,每次只喂给模型1个chunk,更新1次KV Cache。因为没有把所有token一起计算,Chunking牺牲了Prefill计算的并行性。但是却可以缓解显存压力。
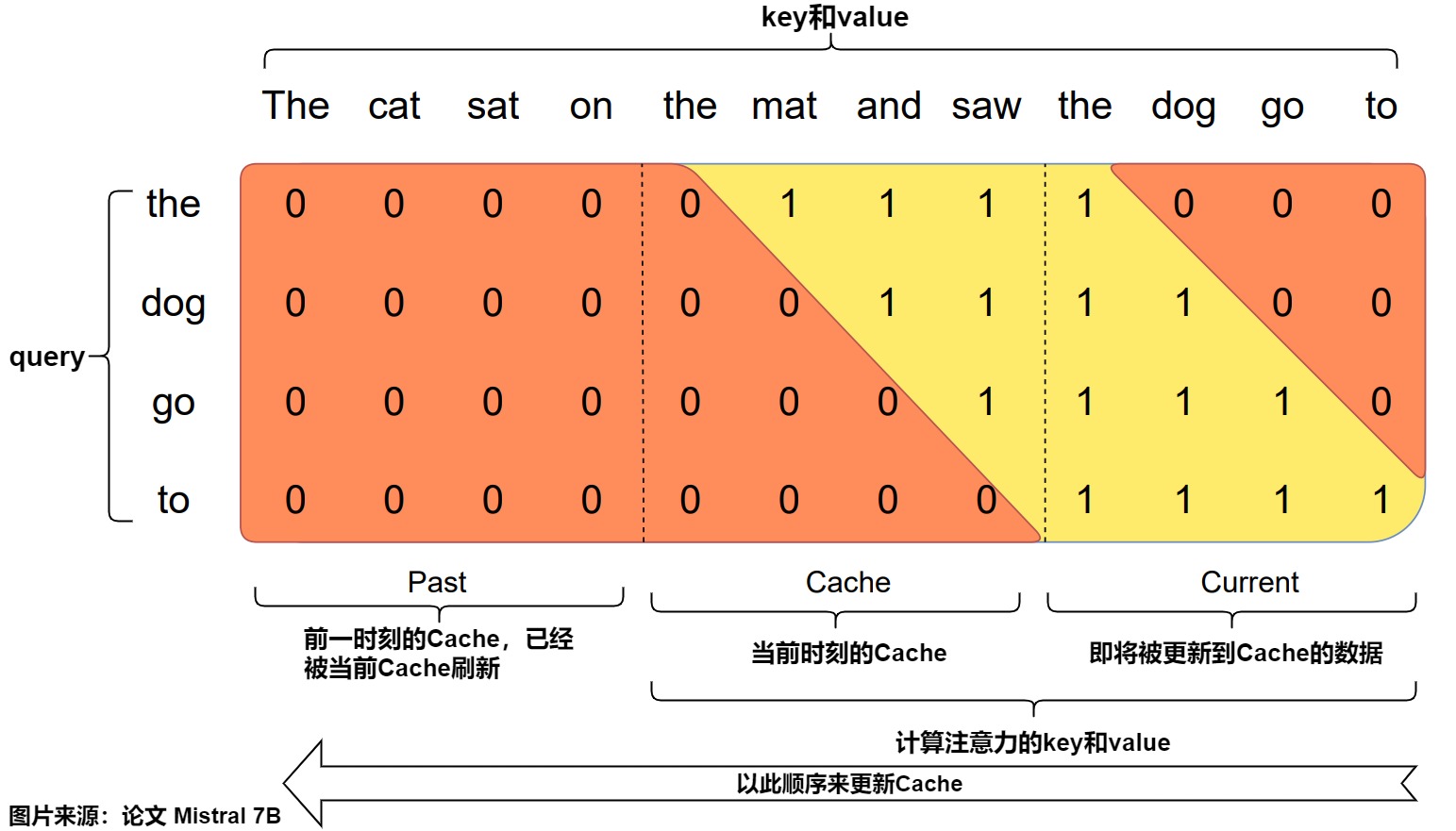
下图是chunking的展示,输入的prompt为The cat sat on the mat and saw the dog go to,同时chunk_size = cache_window = sliding_window = 4,即chunk、cache的尺寸都和滑动窗口的尺寸保持一致。这样无论是从计算逻辑还是空间利用率上,都是更好的选择。句子就被分成三块:"the cat sat on","the mat and saw”,“the dog go to”。
图上的行方向表示query,列方向表示key和value,整个0/1数据块表示mask矩阵,即行方向的query和列方向的key、value是否做注意力计算。图下方的Past表示前一个时刻的cache,已经被当前cache刷新。Cache表示当前真正的cache,Current表示即将被更新进cache的Xk, Xv值。
当我们遍历到某个chunk时,我们取出当前的cache和这个chunk做attention计算,然后再把这个chunk相关的KV值按Rolling Buffer Cache的方式更新进这个cache中。
4.1.2 KV-Runahead
KV-Runahead的主要思路就是让前面的层多做点,后面层少做点,借此加速提示阶段。
动机
KV-Runahead的关键观察是,由于键值缓存(KV-cache),扩展阶段生成标记的速度比提示阶段更快。因此,KV-Runahead通过协调多个进程来填充 KV-cache 并最小化第一个标记时间 (TTFT),从而并行化提示阶段。
双重利用KV Cache方案有几个主要好处。
- 由于KV Cache旨在利用因果注意力图,我们自动最小化了计算和通信。
- 由于KV Cache已经存在于扩展阶段,因此KV-Runahead易于实现。
- 我们进一步提出了上下文级负载平衡,以处理因果注意力导致的不均匀KV Cache生成,并优化TTFT。
方案
下图展示了KV-Runahead与张量/序列并行推理(TSP/Tensor+Sequence Parallel Inference)的比较。
- TSP:TSP的重点是并行化。通过均匀的上下文划分,(Q, K, V) 在每个进程上独立计算。然后,执行collective操作all-gather以交换K和V到所有进程,使得QKT可以均匀分布。层中的所有计算都是对称的,全局同步的,但是TSP没有利用LLM推理中的因果性。
- KV-Runahead:以不均匀的上下文分区开始,(Q, K, V)在每个进程上独立计算。因此,每个进程计算(Q, K, V)中的不同数量的条目。KV-Runahead简单地从每个进程填充KV Cache并交给链中的下一个进程,以模拟扩展阶段。结果是,只有最后一个进程将拥有完整的(K, V),但每个进程仍然可以输出与Q形状相同的A,驱动下一层。由于后续进程等待KV缓存就绪,各层将异步通信,并且用户上下文被不均匀地划分(用于负载平衡)以最小化TTFT。由于KV Cache本身是建立在因果性之上的,KV-Runahead可以自动最小化上三角的计算并减少QKT的点积数量。
KV-Runahead通过利用多个进程来为最后一个进程填充KV Cache,从而实现并行推理。因此,KV-Runahead需要良好的上下文分区(建议进行离线搜索以找到最佳分区方案,然后将结果存储在分区查找表中)来平衡每个计算进程的KV Cache量并最小化TTFT。一旦分区完成,每个进程将基于前一个进程的KV Cache进行计算。具体来说,当前进程必须等待前一个进程传来的所需KV Cache(即注意图(b)中的层错位),通过本地点对点通信而不是通过all-gather进行全局同步,形成依赖链。
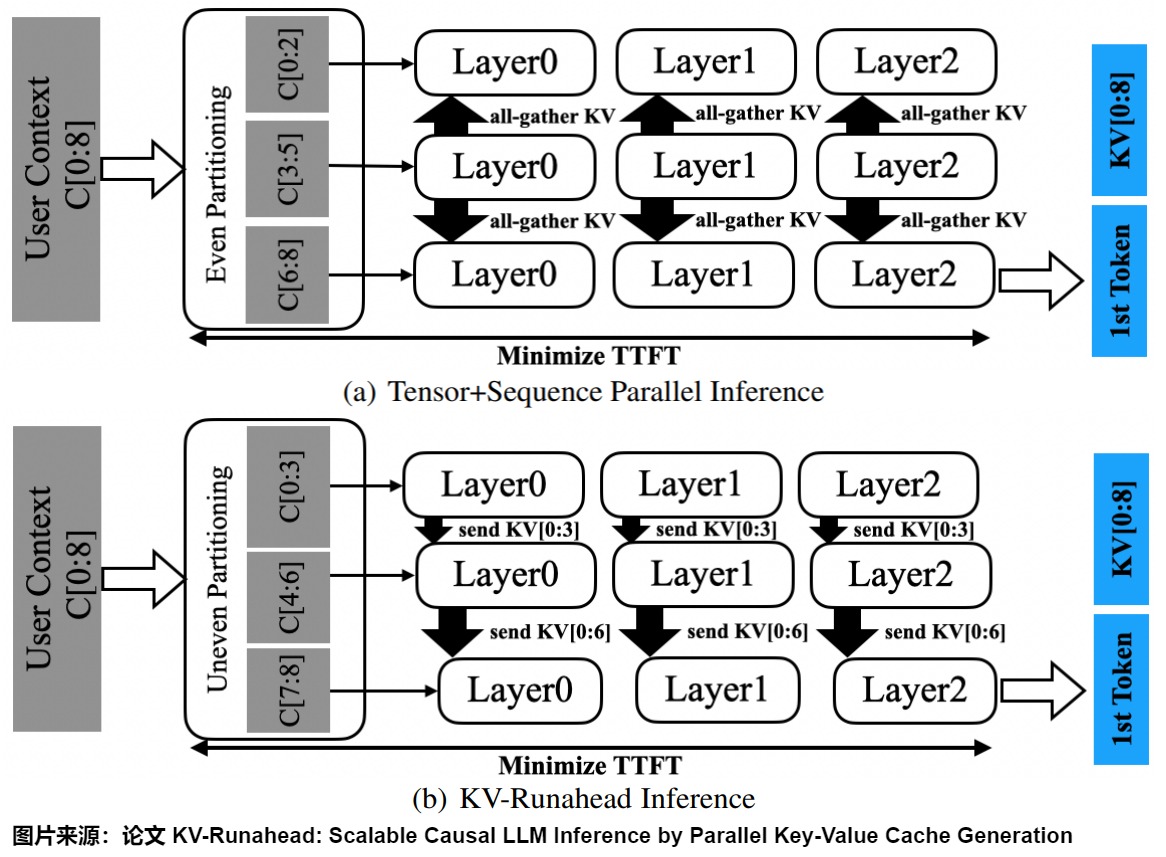
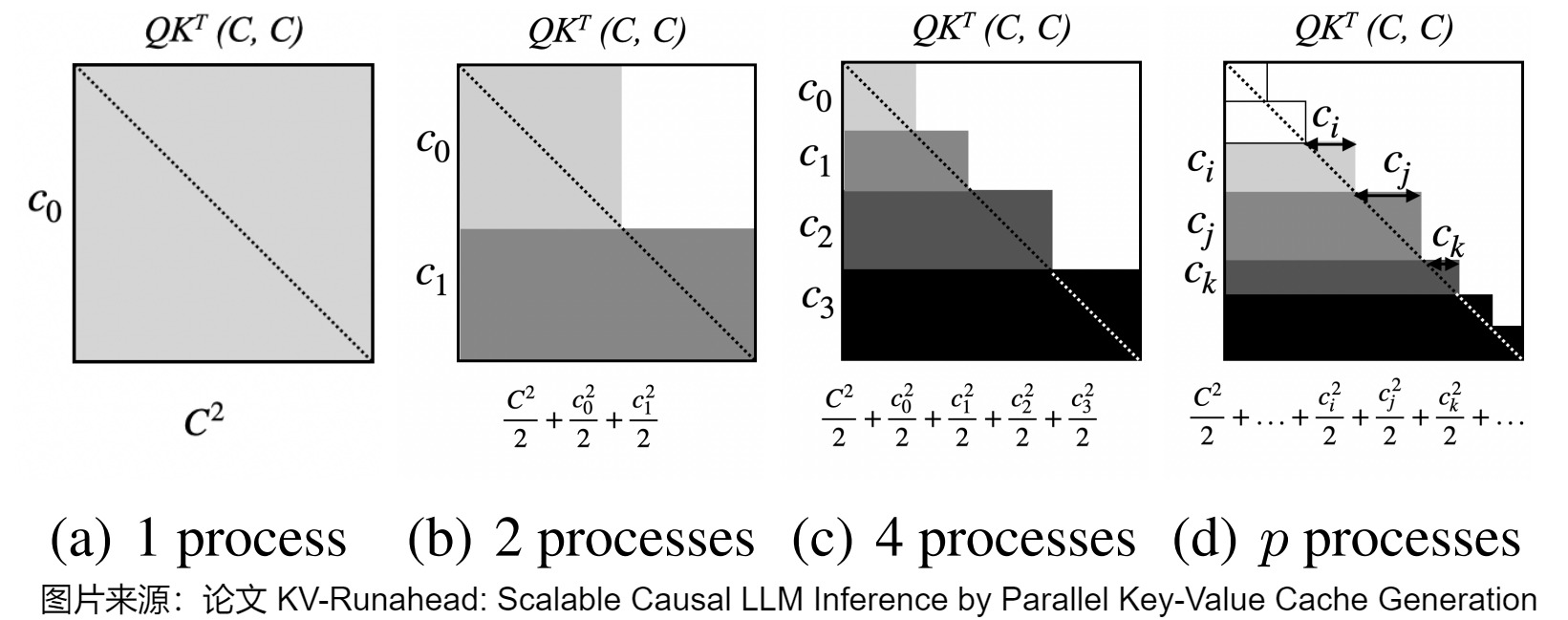
下图是使用BLAS矩阵矩阵乘法的QKT计算覆盖率。通过将每个上下文分区链接到KV缓存,我们可以逼近(approximate )下三角部分并最小化不必要的点积。注意力的上三角部分将被掩盖,以强制因果关系。
4.2 内存管理优化
4.2.1 问题
现有的大语言模型(LLM)服务系统在管理KV缓存内存方面效率不高。这主要是因为它们把KV缓存存储在连续的内存空间中(大多数深度学习框架要求张量必须存储在连续的内存中)。然而,与传统深度学习工作负载中的张量不同,KV缓存有其独特的特点(每个请求都需要大量的内存,且这些内存的需求是动态变化的):
- 它随着模型生成新词而动态增长和收缩。而且,每个请求的KV缓存增长缓慢,即每次迭代增加一个token。
- 它的生命周期和长度是未知的。无法预先预判KV缓存的总大小。
这些特点使得现有系统的管理方式显得非常低效。在现有系统的块预分配方案中,具体存在以下几种主要的内存浪费来源:为潜在最大序列长度过度分配导致的内部碎片化,为未来token保留的插槽、以及来自内存分配器(如伙伴分配器)的外部碎片化。
- 为潜在最大序列长度过度分配导致的内部碎片化。对应下图上的圆形标号1。
- 由于请求的总序列长度事先不确定,为了在连续空间中存储请求的KV缓存,这些系统通常会预测请求的最大可能序列长度,从而提前为一个请求静态分配一块连续的存储空间,以容纳最大的序列长度。而不管实际的输入或最终的输出长度。因为请求的实际长度往往比最大长度短很多,这种分配中的一部分几乎肯定永远不会被使用,并且也无法被其他请求利用,最终被浪费(即内部内存碎片化)。由于内部碎片而浪费了大量的GPU内存。因此,这些系统的吞吐量较差,无法支持大批量大小。
- KV缓存是矩形的:你分配一个大的矩形内存,其中一个维度是批量大小(模型一次可以处理的最大序列数),另一个维度是允许用户使用的最大序列长度。当一个新序列进入时,你会为这个用户分配整行内存,假设预测每个用户最大上下文长度是2048,则需要为每个用户预先分配一个可支持 2048 个 tokens 缓存的显存空间。如果用户实际使用的上下文长度低于2048,这种方法显然会造成存储资源的大量浪费。
- 提前为未来token保留的插槽。对应下图上的圆形标号2。即使实际序列长度事先已知,预分配的方式仍然低效。因为每个请求的KV-cache每次增加一个标记,而在请求的生命周期内,整个内存块都会被保留,由于内存逐渐被消耗,但内存块被保留到请求的整个生命周期,较短的请求仍然无法使用尚未使用的内存块。
- 来自内存分配器(如伙伴分配器)的外部碎片化和其它损耗。对应下图上的圆形标号3。
- 由于KV Cache是一个巨大的矩阵,且必须占用连续内存,操作系统只分配大的连续内存,如果不同请求的预分配大小不同,势必有很多小的内存空间被浪费掉,导致外部内存碎片化。
- 在 Paged Attention 之前,业界主流 LLM 推理框架在 KV Cache 管理方面均存在一定的低效。HuggingFace Transformers 库中,KV Cache 是随着执行动态申请显存空间,由于 GPU显存分配耗时一般都高于 CUDA kernel 执行耗时,因此动态申请显存空间会造成极大的时延开销,且会引入显存碎片化。
- 现有系统无法利用内存共享的机会。LLM服务常常使用高级解码算法,比如并行采样和束搜索,这些算法会为每个请求生成多个输出。在这些场景中,请求包含的多个序列可以部分共享其KV缓存。然而,现有系统中,序列的KV缓存存储在不同的连续空间中,无法实现内存共享。
另外,尽管已经提出了压缩作为解决碎片化的潜在方案,但在一个对性能敏感的LLM服务系统中执行压缩是不现实的,因为KV缓存非常庞大。即使有压缩,每个请求的预分配块空间也阻碍了现有内存管理系统中特定解码算法的内存共享。

4.2.2 Paged Attention
PagedAttention (vLLM) 借鉴了操作系统中的分页(Page)方式进行存储,将KV Cache分为固定大小块,存储在非连续的物理内存中,这样可以为vLLM提供更灵活的分页内存管理。通过使用相对较小的小块并按需分配,PagedAttention缓解了内部内存碎片化问题。此外,由于所有小块大小相同,它还消除了外部内存碎片化问题。PagedAttention也可以使同一请求的不同序列甚至不同请求之间可以在小块级别共享内存,实现了内存共享。
下图给出了因为内部碎片造成的内存浪费,阴影框表示KVtoken占用的内存,而白色框表示已分配但未使用的内存。
- Orca(顶部)提前为KV缓存保留一块连续的虚拟内存。分配的大小对应于模型支持的最大序列长度,例如32K。由于模型生成的 token 通常远少于最大限制,因此由于内部碎片而浪费了大量GPU内存。
- vLLM(底部)通过动态内存分配减轻碎片化。

实现
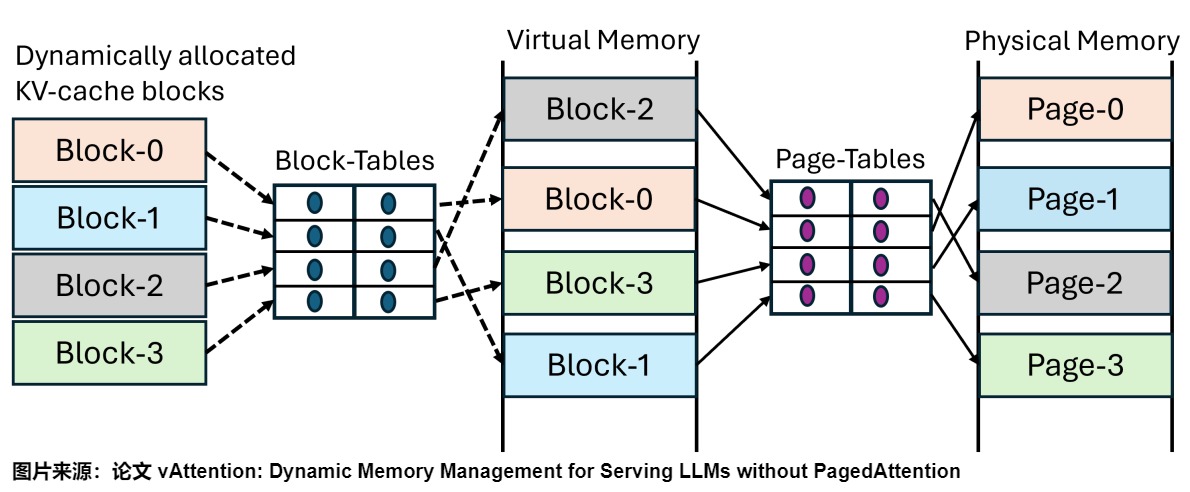
PagedAttention的灵感来源于操作系统中的虚拟内存和分页技术。操作系统将内存划分为固定大小的页面,并将用户程序的逻辑页面映射到物理页面。连续的逻辑页面可以对应非连续的物理内存页面,使得用户程序可以像访问连续内存一样访问内存。PagedAttention将KV缓存组织成固定大小的KV块,类似于虚拟内存中的页面。而vLLM实现了一个类似虚拟内存的系统,通过复杂的映射机制管理这些块。这种架构将逻辑和物理KV块分开,通过跟踪映射关系和填充状态的块表实现动态内存分配和灵活的块管理。具体特点如下。
- 为了能够动态分配物理内存,PagedAttention 将 KV Cache 的布局从连续的虚拟内存更改为非连续的虚拟内存 。
- PagedAttention将KV缓存分割为固定大小且相对较小的内存块,称为块,每个块可以包含固定数量的词元的键和值。这些块类似于进程虚拟内存中的页面,因此我们可以像操作系统管理虚拟内存那样灵活地管理KV缓存。PagedAttention每次为一个块分配内存。这些小块不需要存储在连续的空间中,可以在GPU和CPU内存之间进行交换,并且必要时可以在不同的请求之间共享。
- vLLM不是预先保留KV缓存内存的最大序列长度,而是只在需要时分配请求所需的内存,即允许生成过程中不断为用户追加显存,而不是提前分配。通过 token 块粒度的显存管理,系统可以精确计算出剩余显存可容纳的 token 块的个数,配合 Dynamic Batching 技术,即可避免系统发生显存溢出的问题。
- PagedAttention实现一个块表来将这些非连续的分配拼接在一起。也实现了一个高效的显存管理器,通过精细化管理显存,实现了在物理非连续的显存空间中以极低的成本存储、读取、新增和删除键值向量。
PagedAttention涉及两层地址转换。首先,该框架通过块表跟踪KV Cache块的虚拟内存地址。其次,GPU通过操作系统管理的页表执行虚拟到物理地址的转换。具体如下图所示。
架构
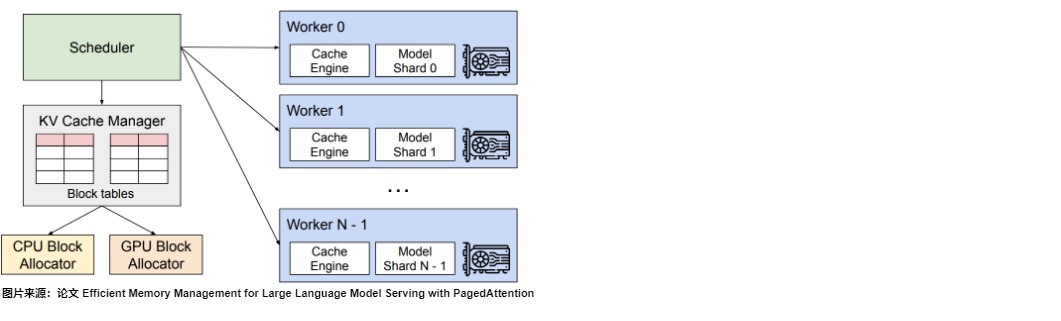
vLLM的架构如下图所示,具体分为量部分:
- Scheduler。vLLM采用集中式调度器来协调分布式GPU worker的执行和对应的物理KV缓存内存。
- KV Cache Manager。KV缓存管理器通过PagedAttention以分页方式有效地管理KV缓存。
KV Cache管理器
PagedAttention首先加载模型,这样就知道剩余多少空间给KV Cache,后续会用内存块填充这些空间。这些块可以包含最多16或32个token。
系统会动态维护一个显存块的链表——每个请求的逻辑和物理KV块之间的映射关系。每个块表条目记录了逻辑块的相应物理块及其填充位置的数量,通过该方式即可实现将地址不连续的物理块串联在一起统一管理。当一个请求来到之后,系统会为这个请求分配一小块显存,这一小块显存通常只够容纳 8 个字符,当请求生成了 8 个字符之后,系统会追加一块显存,请求可以把结果再写到这块显存里面。当生成的长度不断变长时,系统会不断地给用户追加显存块的分配,并动态更新显存块列表。将逻辑和物理KV块分开使得vLLM可以动态增长KV缓存内存,而无需提前为所有位置预留空间,这消除了现有系统中大部分的内存浪费。
下图是算法。PagedAttention将每个序列的键值(KV)缓存划分为KV块。每个块包含一定数量的token的键和值向量。例如,键块\(K_j\)包含的是第j个块中的键向量,而值块\(V_j\)包含的是第j个块中的值向量。在注意力计算过程中,PagedAttention内核分别识别和获取不同的KV块。例如,当处理查询标记为“forth”时,内核将查询向量\(q_i\)与每个块中的键向量\(K_j\)相乘,以计算注意力得分\(A_{ij}\)。然后,它将这些得分与每个块中的值向量\(V_j\)相乘,得出最终的注意力输出。
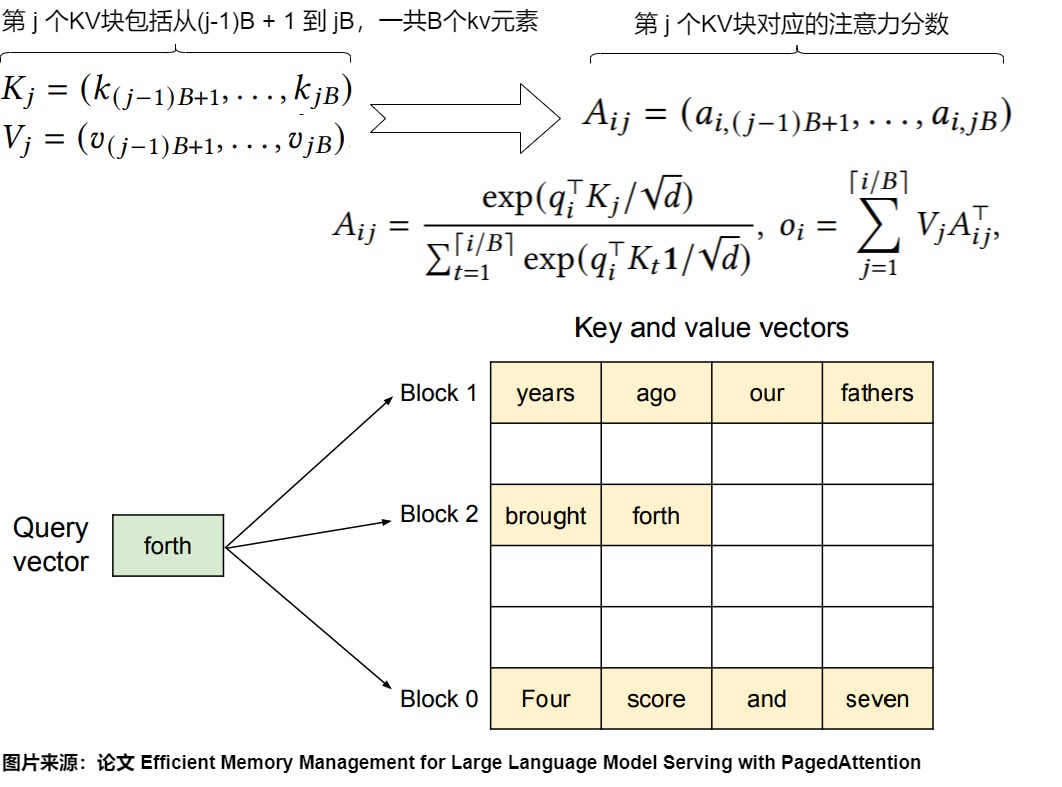
基本场景的解码算力
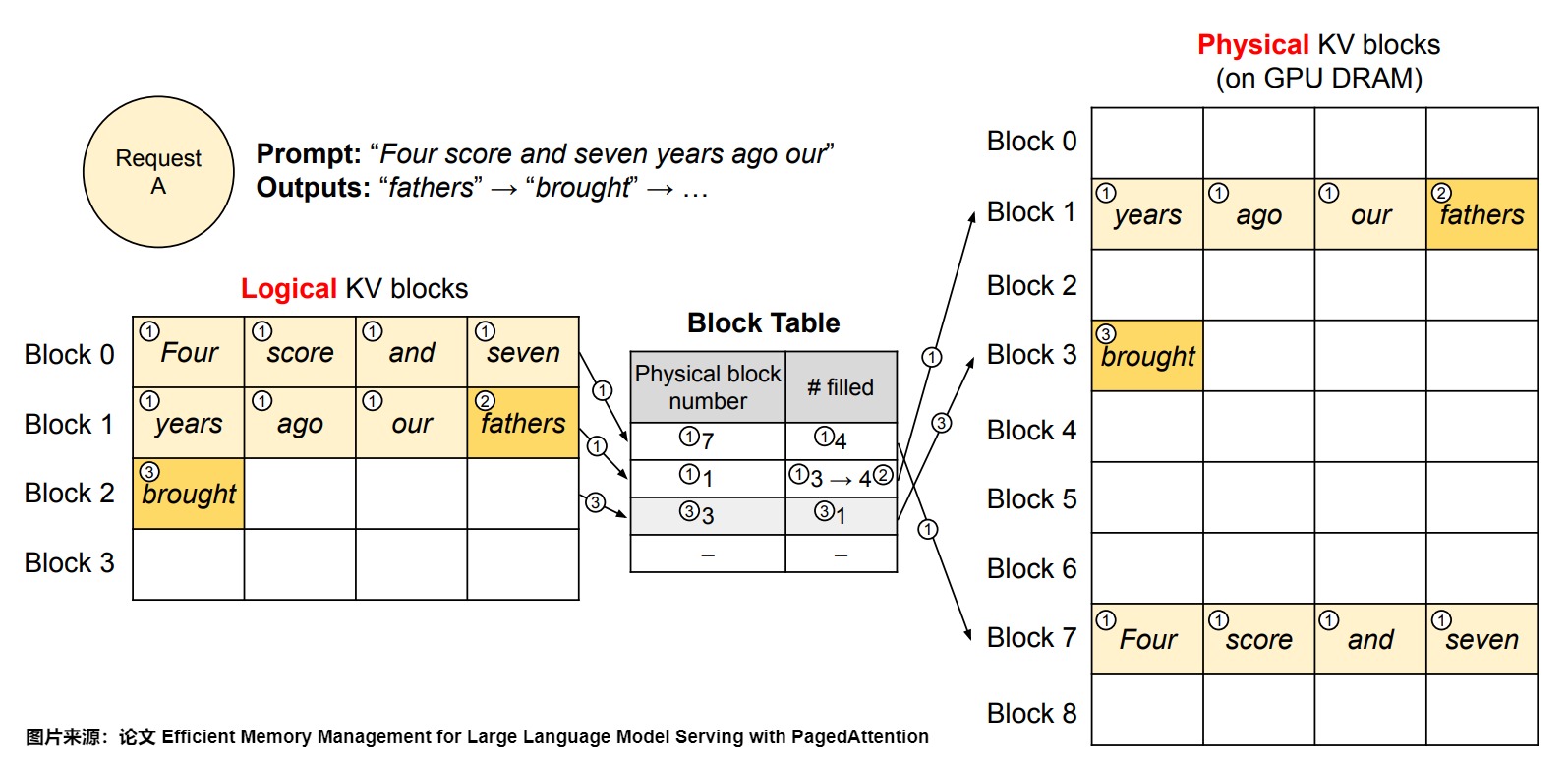
下图是vLLM是如何执行PagedAttention,并在单个输入序列的解码过程中管理内存的示例。总的来说,对于每个解码迭代,vLLM首先选择一组候选序列进行批处理,并为新需求的逻辑块分配物理块。然后,vLLM将当前迭代的所有输入标记(即提示阶段请求的所有标记和生成阶段请求的最新标记)串联为一个序列,并将其输入到LLM中。
- vLLM在初始阶段不需要为最大可能生成的序列长度预留内存。相反,它只保留了足够容纳提示计算期间生成的KV缓存所需的KV块。在本例中,提示有7个标记,因此vLLM将前两个逻辑KV块(0和1)映射到两个物理KV块(7和1)。在预填充步骤中,vLLM使用传统的自注意力算法生成提示和第一个输出标记的KV缓存。然后,vLLM将前4个标记的KV缓存存储在逻辑块0中,后续3个标记存储在逻辑块1中。剩余的位置留待后续自回归生成阶段使用。此处对应下图上标号1。
- 在第一个自回归解码步骤中,vLLM使用PagedAttention算法在物理块7和1上生成新的标记。由于最后一个逻辑块中还有一个空位,新生成的KV缓存被存储在那里,并且更新了块表中的已填充记录。
- 在第二个自回归解码步骤中,由于最后一个逻辑块已满,vLLM将新生成的KV缓存存储在一个新的逻辑块中;vLLM为其分配一个新的物理块(物理块3)并将此映射存储在块表中。
劣势
然而,为了能够动态分配物理内存,PagedAttention也增加了软件复杂性、导致可移植性问题、冗余和低效。
- 需要重新编写注意力核心(GPU代码),以便注意力核心通过索引查找到KV缓存(虚拟连续对象)的所有元素。
- 增加了软件复杂性和冗余(CPU代码)。PagedAttention还迫使开发人员在服务框架中实现内存管理器,使其负责(解)分配KV缓存并跟踪动态分配的KV缓存块的位置。这种方法实质上是在用户代码中重新实现了按需分页-这是一个操作系统功能。
- 引入了性能开销。PagedAttention在关键路径上增加了运行时开销。首先,它需要GPU核心执行与从非连续内存块获取KV缓存相关的额外代码。我们展示了这在许多情况下可能会使注意力计算速度减慢超过10%。其次,用户空间内存管理器可能会增加CPU开销,导致额外的10%成本。
4.2.3 vAttention
vAttention作者认为保留KV Cache的虚拟内存连续性对于减少LLM部署中的软件复杂性和冗余至关重要,并主张利用操作系统中现有的虚拟内存抽象来管理动态KV Cache内存,从而实现简化部署和更高性能。基于这些思考,vAttention作者提出了vAttention,其特点如下。
- 将KV Cache存储在连续的虚拟内存中,而不是事先分配物理内存。作为对比,PagedAttention在虚拟地址上是不连续的。
- 为KV Cache保留连续的虚拟空间,并按需分配物理内存。
- 在不需要在服务系统中实现内存管理器的情况下,实现了更高的可移植性,同时可以无缝重用现有的GPU核心。使注意力核心开发人员不必显式支持分页,并避免在服务框架中重新实现内存管理,实现了对各种注意力核的无缝动态内存管理。
洞察
vAttention对LLM服务系统有一些洞察。
观察1:在每次迭代中,KV Cache的内存需求是可以预先知道的。这是由于自回归解码每次只生成一个标记。因此,随着每次迭代,请求的KV Cache内存占用量会均匀地增加一个标记,直到请求完成。
观察2:KV Cache不需要高内存分配带宽。在所有层中,单个标记的内存占用通常为几十到几百KB。此外,每次迭代持续10到100毫秒,这意味着每秒最多需要几兆字节的内存。虽然批处理可以提高系统的吞吐量,但每秒生成的标记数量在达到一定批大小后就会趋于平稳。这意味着内存分配带宽需求在大批大小下也会饱和。
设计概述
vAttention目标是通过为现有的kernel添加动态内存分配支持来提高效率和可移植性。为了实现这一目标,vAttention利用系统支持的动态内存分配,而不是在用户空间中实现分页。
vAttention基于将虚拟内存和物理内存分别分配的能力进行构建。具体来说,vAttention预先在虚拟内存中为KV-cache分配一个大的连续缓冲区(类似于基于保留的分配器),而将物理内存的分配推迟到运行时,即只在需要时分配物理内存(类似于PagedAttention)。这样,vvAttention在不浪费物理内存的情况下保留了KV Cache的虚拟连续性。这种方法之所以可行,是因为内存容量和碎片化仅对物理内存构成限制,而虚拟内存是充裕的,例如,现代64位系统为每个进程提供128TB的用户管理虚拟地址空间。
预留虚拟内存。由于虚拟内存是丰富的,我们预先分配足够大的虚拟内存空间,以容纳所需支持的最大批次大小的KV-cache(可配置)。虚拟内存缓冲区的数量:每个LLM中的每个层都维护自己的K和V张量:我们将它们分别称为K-cache和V-cache。我们为K-cache和V-cache分别分配单独的虚拟内存缓冲区。
按需分配物理内存。vAttention优先按页一次性分配物理内存,仅当一个请求使用完其先前分配的所有物理内存页时才分配。
下图展示了vAttention如何通过按需分配物理内存来动态管理 KV Cache 的内存,同时通过延迟回收策略优化内存使用,以便在新的请求到达时可以高效地重新利用已经分配的物理内存。此处是处理模型的一层中的K-cache(或V-cache),假设最大批次大小为两个。其余的K-cache和V-cache缓冲区在所有层中以相似的方式进行管理。具体分为五个步骤:
- (a):虚拟内存中包含了两个请求(R1和R2)的虚拟张量,但还没有进行任何物理内存分配。浅色阴影区域代表了没有任何物理页支持的虚拟张量部分。
- (b):R1被分配了一页物理内存。这个分配使得虚拟张量的一部分(浅色阴影区域)映射到了实际的物理内存上(深色阴影区域)。
- (c):R1被分配了两页物理内存,而R2被分配了一页物理内存。此时,R1的虚拟张量有两部分映射到了物理内存上,而R2的虚拟张量有一部分映射到了物理内存上。
- (d):R1已经完成了它的任务,但vAttention没有立即回收其内存(延迟回收)。因此,R1的虚拟张量依旧占据物理内存。
- (e):当新的请求R3到达时,vAttention将R1的张量分配给R3,因为这些张量已经有物理内存支持。
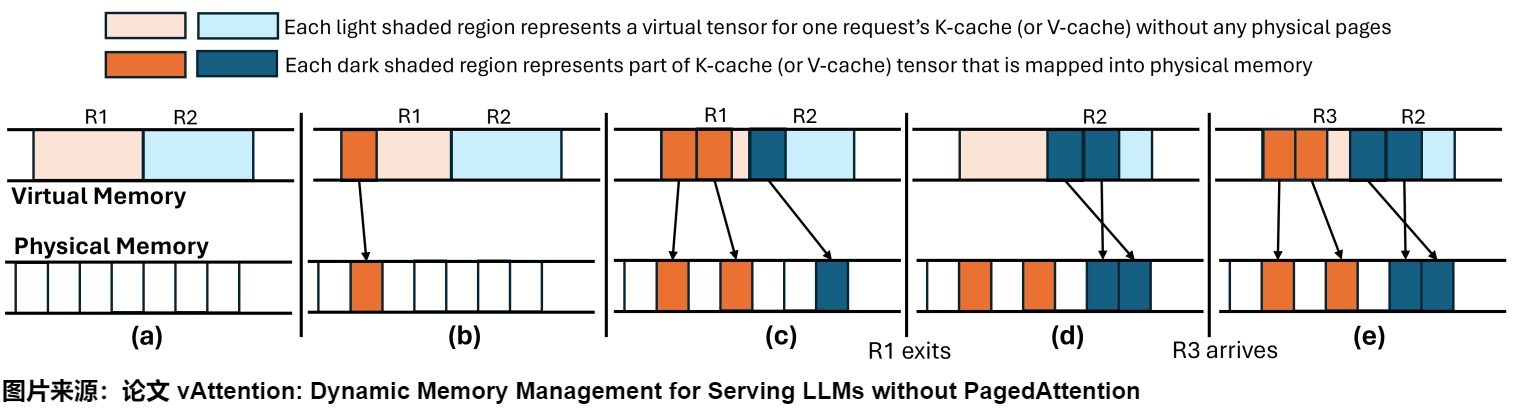
4.3 调度
这部分主要是针对KV Cache特点实施的一些调度策略,主要是三种途径:
前缀感知调度策略。
抢占式和面向公平的调度。
特定于层的分层调度方法。
下图给出了一些常见方案的特点。

4.3.1 Prefix-aware Scheduling
在传统的基于LRU的缓存管理系统中,共享的KV上下文可能会被过早地被驱逐,或在内存中不必要地扩展。Prefix-aware Scheduling则会基于前缀进行调度,即具有相同前缀的请求被放在一起调度。
- BatchLLM通过全局前缀识别和基于共享公共KV缓存内容的动态规划算法来将共享前缀的请求放在一起调度,这样可以最大化KV Cache复用,减少缓存生命周期。
- RadixAttention围绕基数树结构实现了缓存的快速匹配、插入和替换。在RadixAttention中,缓存的令牌和正在运行的请求共享同一个内存池,然后结合LRU驱逐和引用计数来管理内存池。
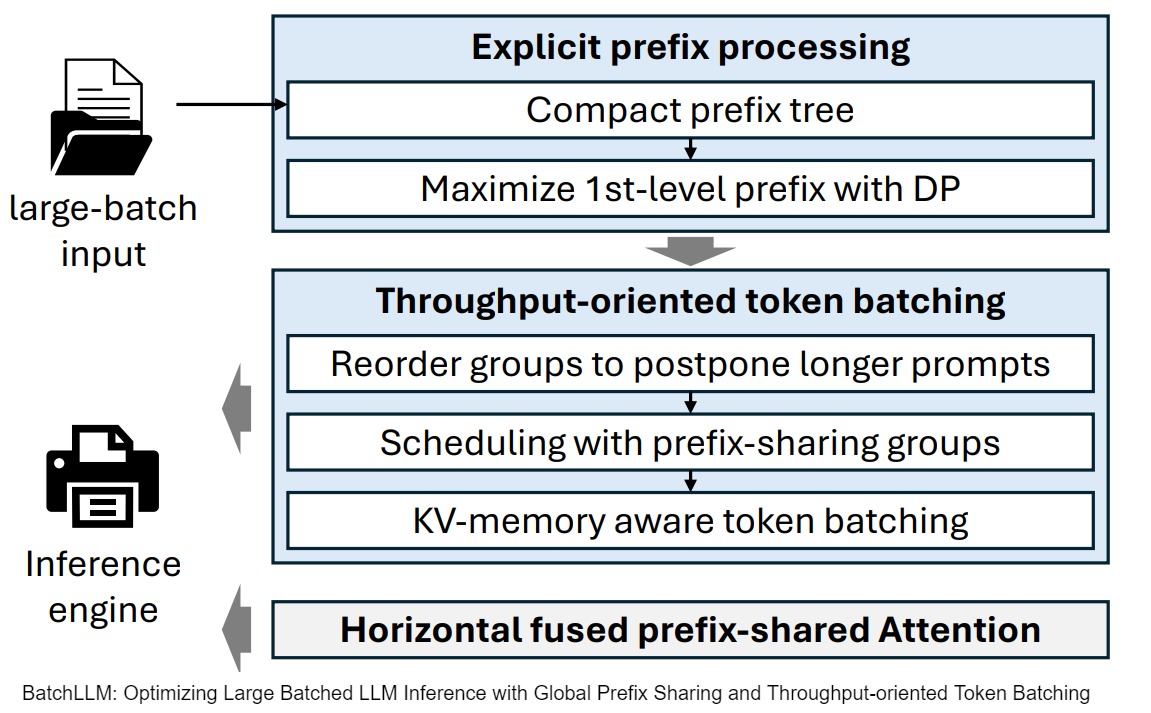
下图给出了BatchLLM的总体流程。
首先,对大批量输入 Prompt 进行分析,并识别出共同的前缀部分,这一步骤在 Request 调度之前完成。
BatchLLM 利用前缀树来识别和表示 Prompt 之间的共同前缀。然而,直接使用前缀树的第一层前缀作为共同前缀可能导致前缀复用效果不佳。因此,BatchLLM 设计了一种基于前缀树的动态规划算法,以最大化一级 Token 的复用。
随后,为了简化 KV 复用并缩短公共前缀在内存中的生命周期,BatchLLM 将共享相同前缀的请求集中调度。具体而言,Batch LLM将 Request 分组,一个前缀组对应一组共享相同前缀的 Request 的集合。这些组将成为 Request 调度的基本单元。在调度各组之前,BatchLLM 还会根据前缀 Prefill 长度与估计的 Decoding 长度的比例对组进行重新排序,并推迟那些前缀 Prefill 较长而 Decoding 较短的组。
接着,充分考虑 KV 内存使用情况来实现 Batching,旨在更好地混合 Decoding 步骤与前缀 Prefill Chunk,以增大整体 Token Batch 规模。
此外,BatchLLM 还实现了融合 Attention Kernel,以减少长尾效应及 Kernel 启动开销。
4.3.2 Preemptive and Fairness-oriented scheduling
FastServe实施了一种主动的(proactive )KV缓存管理策略。FastServe 的特色如下:
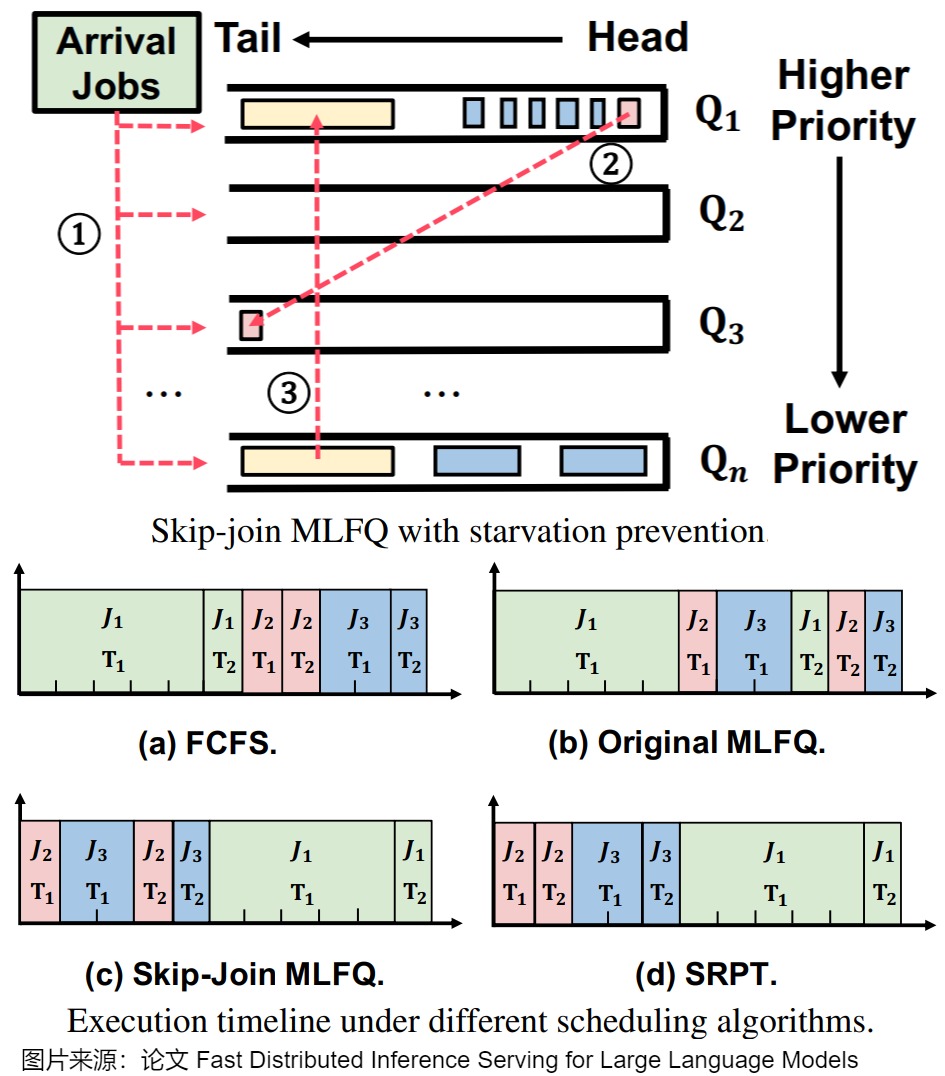
- 创新调度策略:FastServe 引入了 Skip-Join Multi-Level Feedback Queue(MLFQ)调度器,利用 LLM 推理的半信息无关特性,有效避免头阻塞问题。
- 优先级跳过机制:根据输入长度和初始化阶段的时间,将任务分配到合适的队列,减少了不必要的降级操作。
- 高效内存管理:为了应对 GPU 内存限制,FastServe 设计了主动 KV 缓存管理机制,在低优先级任务的缓存即将满时,主动将状态卸载到主机内存,并在需要时重新加载。
- 数据传输优化:通过异步内存操作和流水线技术,显著提高了数据传输效率。
下图给出了FastServe的架构。
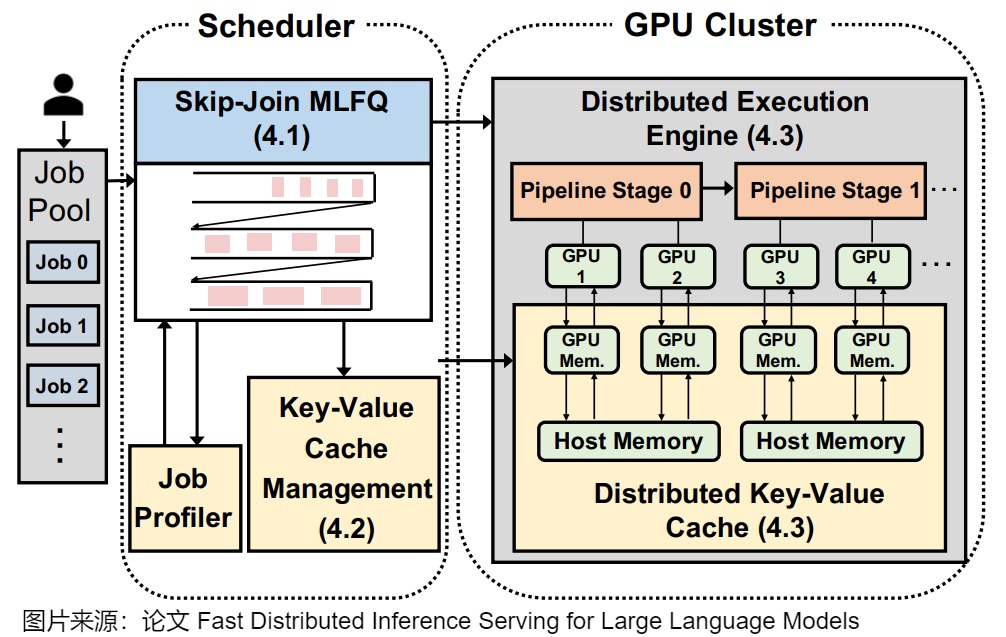
下图上方给出了MLFQ,下方给出了各个调度算法的执行时间流。
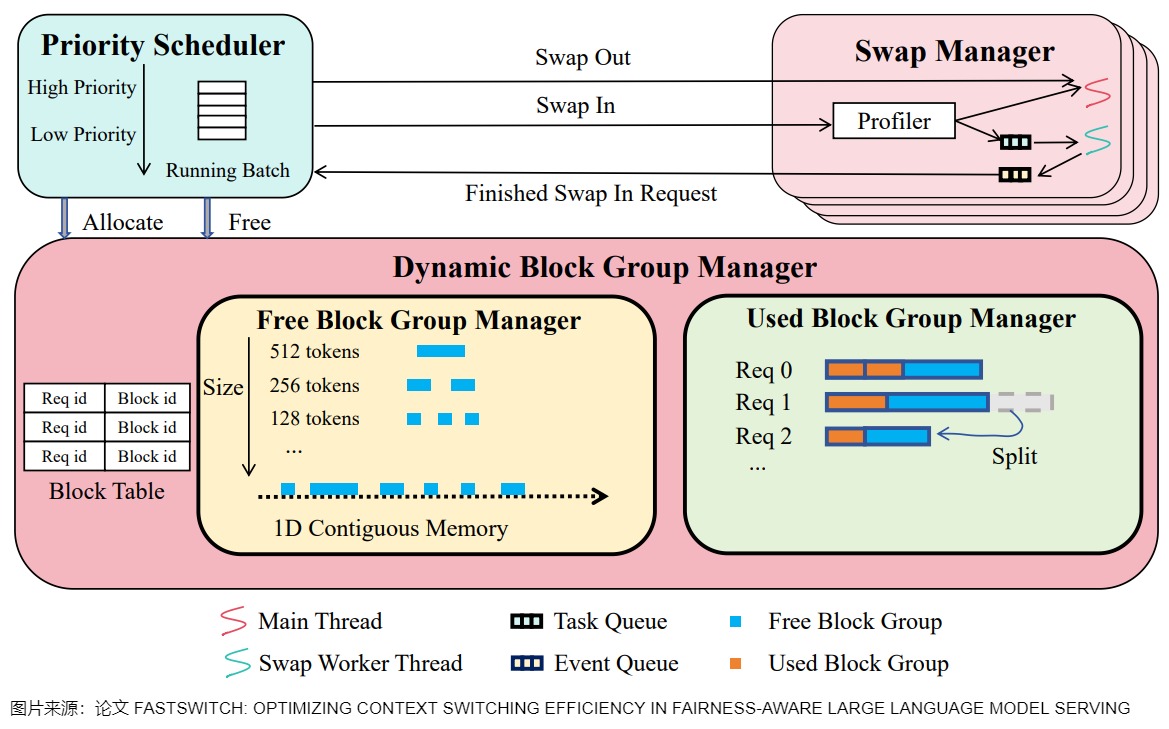
FastSwitch 引入了一个公平导向的 KV 缓存调度系统,解决了在 LLM 服务中抢占式调度的开销挑战。FastSwitch 有三个关键机制:通过智能缓存移动调度提高 I/O 利用率,在上下文切换期间最小化 GPU 空闲时间,以及在多轮对话中消除冗余 I/O 操作。FastSwitch 与传统的基于块的 KV 缓存内存策略不同,传统策略优先考虑内存效率,但是该策略以碎片化和粒度限制为代价。FastSwitch 实施了一种平衡的方法,在促进更平滑的上下文切换的同时保持高效的内存使用。这种集成调度方法实现了动态优先级调整以确保公平性,同时最小化上下文切换对性能的影响。
下图给出了FastSwitch 的总体结构。
4.3.3 Layer-specific and Hierarchical Scheduling
LayerKV
为了解决在大上下文 LLM 服务中日益增长的首次令牌生成时间(TTFT)延迟挑战,LayerKV 引入了一种逐层(layer-wise)KV 缓存调度方法,其贡献在于其细粒度的、层特定(layer-specific)的 KV 缓存块分配和管理策略,与传统的整体缓存管理方法不同。通过实施层特定的 KV 块调度和卸载机制,LayerKV 实现了更高效的内存利用,并减少了在长上下文窗口中竞争有限的 GPU KV 缓存块时通常发生的排队延迟。LayerKV 还使用了一个 SLO 感知调度器,该调度器根据服务水平目标优化缓存分配决策,允许跨模型层动态管理内存资源。下图给出了LayerKV的总体结构。
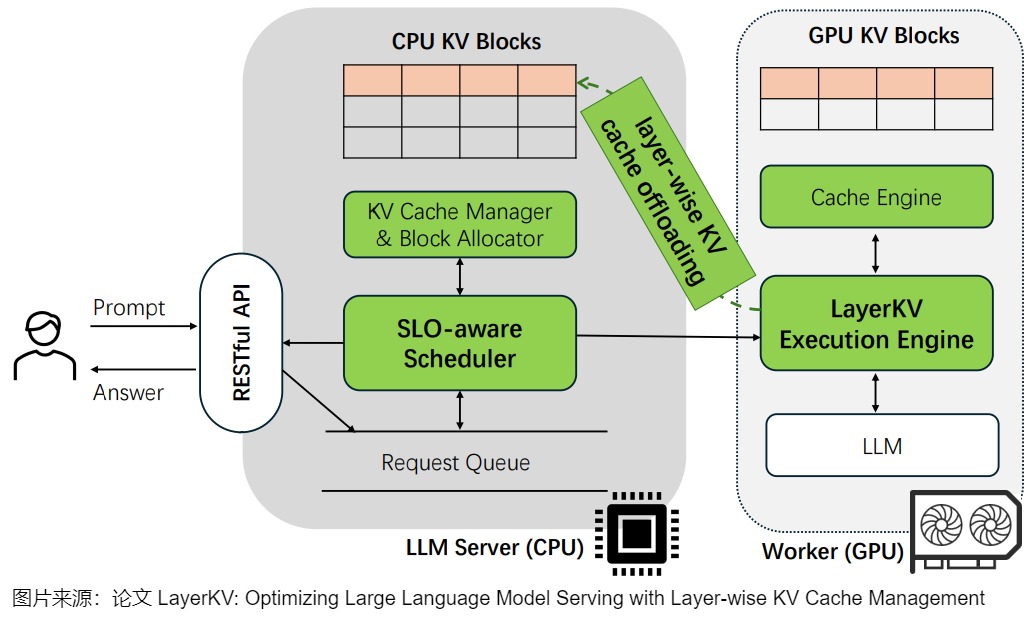
CachedAttention
因为多轮对话的时候每一轮都会重复使用前面所有的缓存数据,为了解决这个问题,让KVCache 缓存最大限度地留在显存中,减少offload再reload的过程,CachedAttention 引入了一种分层调度方法。该方法具体包括三层策略:
- 层特定的预加载。通过调度器感知的获取和淘汰策略协调 KV 缓存在存储层次结构中的移动。
- 异步保存。使 I/O 操作与 GPU 计算重叠。
- 智能缓存放置决策。该策略基于调度器提示,以确保频繁访问的 KV 缓存位于更快的内存层。
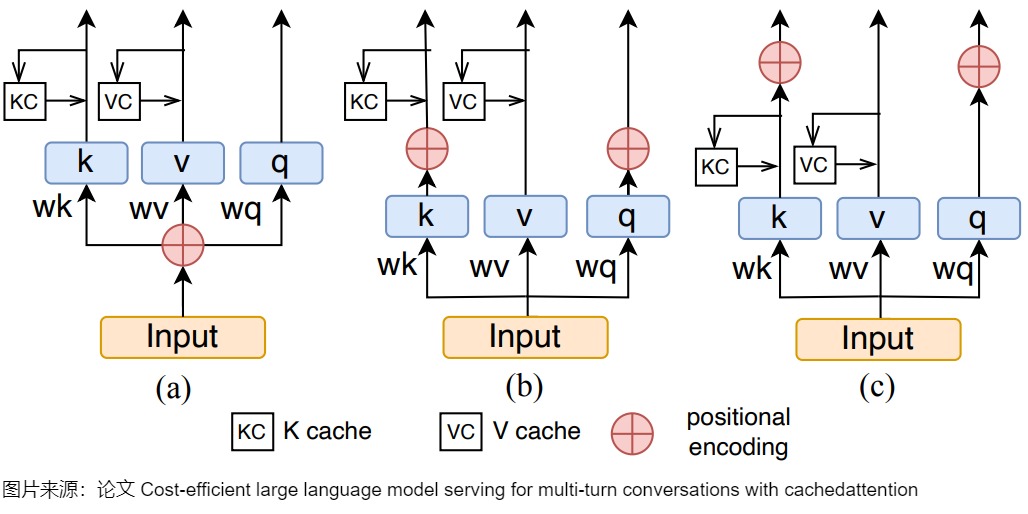
CachedAttention 还提出了一种新颖的位置编码解耦机制,通过有效的截断策略防止在上下文窗口溢出期间 KV 缓存失效。
下图给出了总体架构。
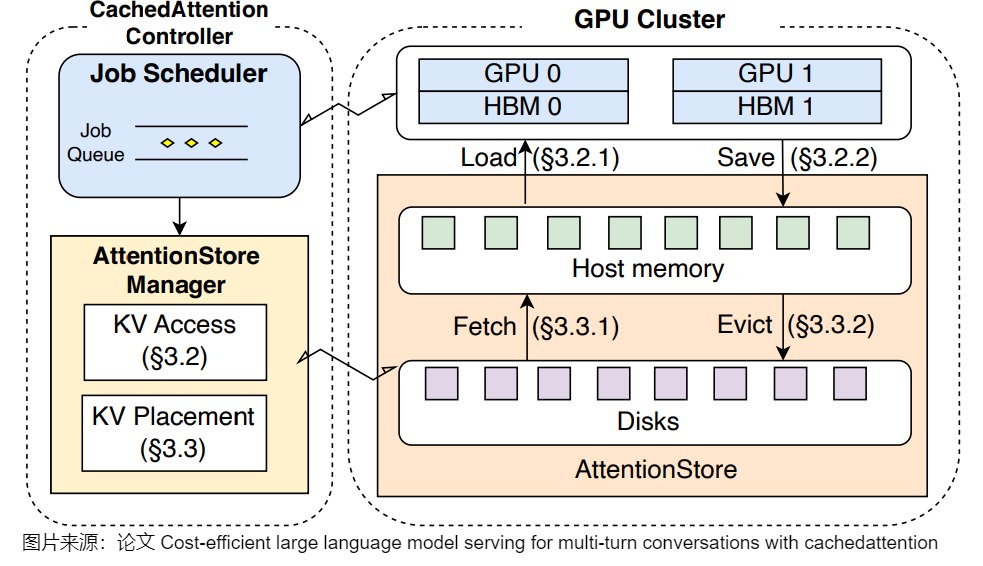
下图展示了分层预加载。
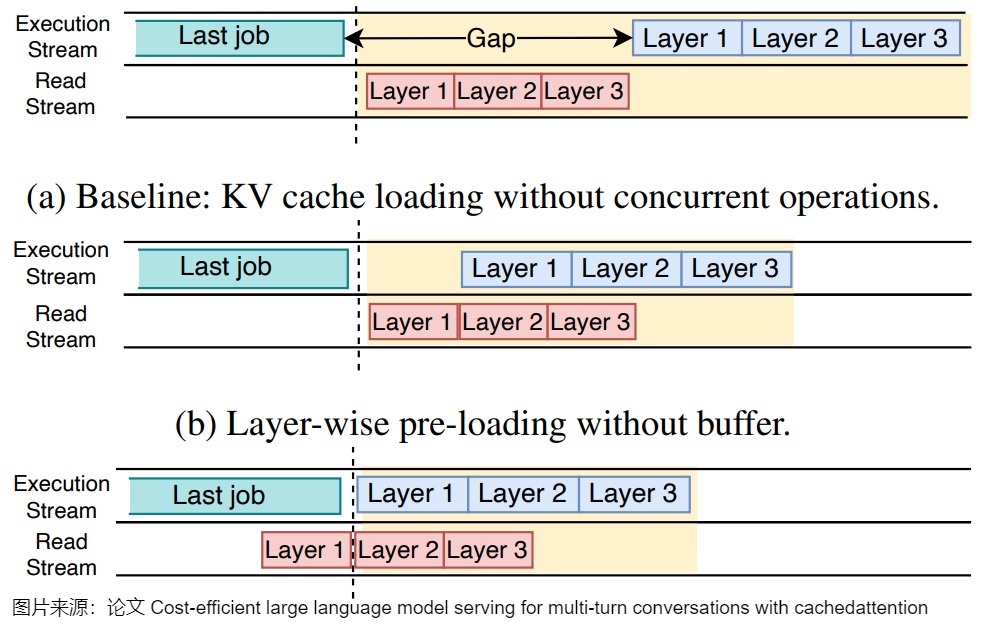
下图展示了异步保存。
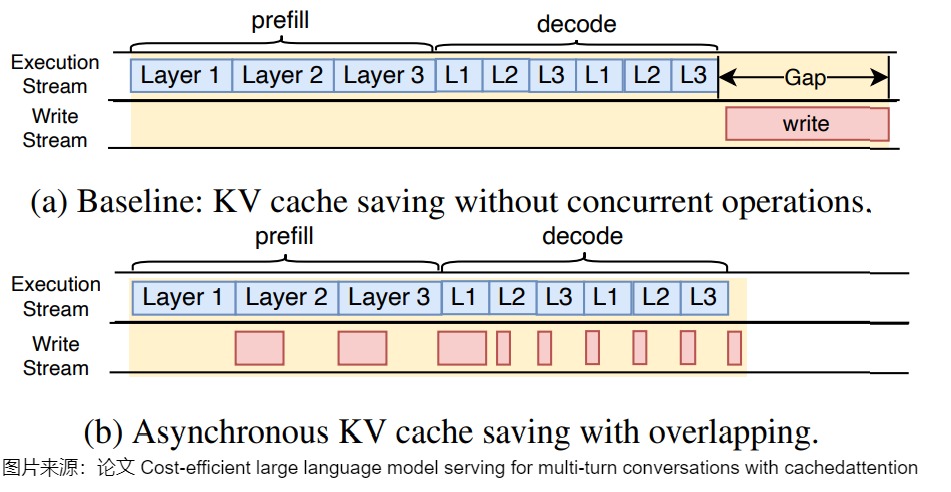
下图给出了位置编码解耦。
(a) 是绝对位置编码,绝对位置编码 Key 和 Query 直接永远都是一样的位置编码。
(b) 是相对位置编码。
(c) 是可以解耦合 Key 和 Query 的位置编码。通过在RPE中嵌入位置编码之前简单地移动缓存KV的时间,CachedAttention可以将没有嵌入位置编码的KV存储在AttentionStore中。在CachedAttention中重用KV时,KV嵌入了新的位置编码,并进一步用于以下推理。
ALISA
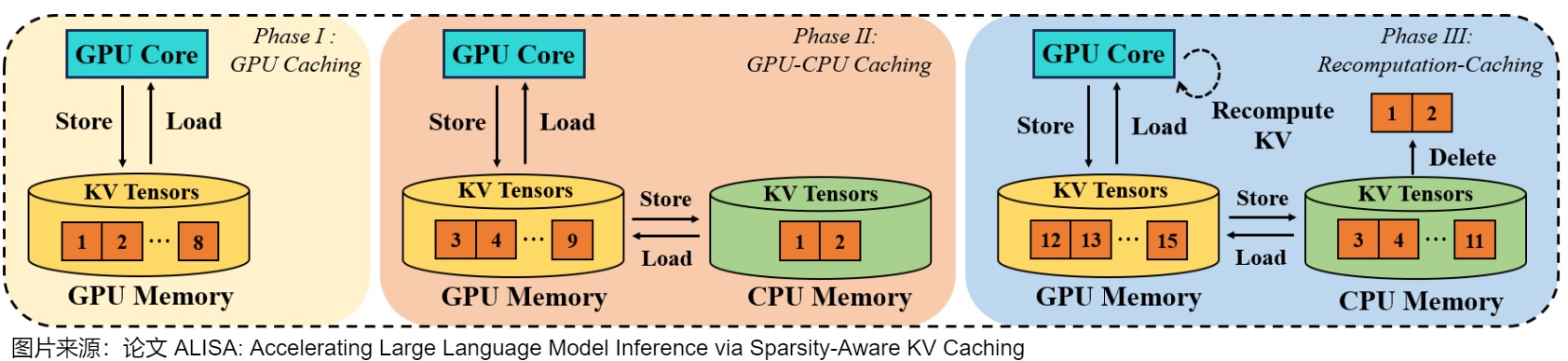
ALISA 引入了一个双层 KV 缓存调度框架,将算法稀疏性与系统级优化相结合。在算法级别,稀疏窗口注意力机制识别并优先考虑用于注意力计算的最重要令牌,创建全局动态和局部静态稀疏模式的混合,显著减少 KV 缓存内存需求。在系统级别,其三相(three-phase)令牌级动态调度器管理 KV 张量分配并优化缓存与重新计算之间的权衡。调度器根据令牌的重要性和系统资源约束动态决定在 GPU 内存中缓存哪些令牌以及重新计算哪些令牌。
下图给出了稀疏窗口注意力(Sparse Window Attention)的计算。
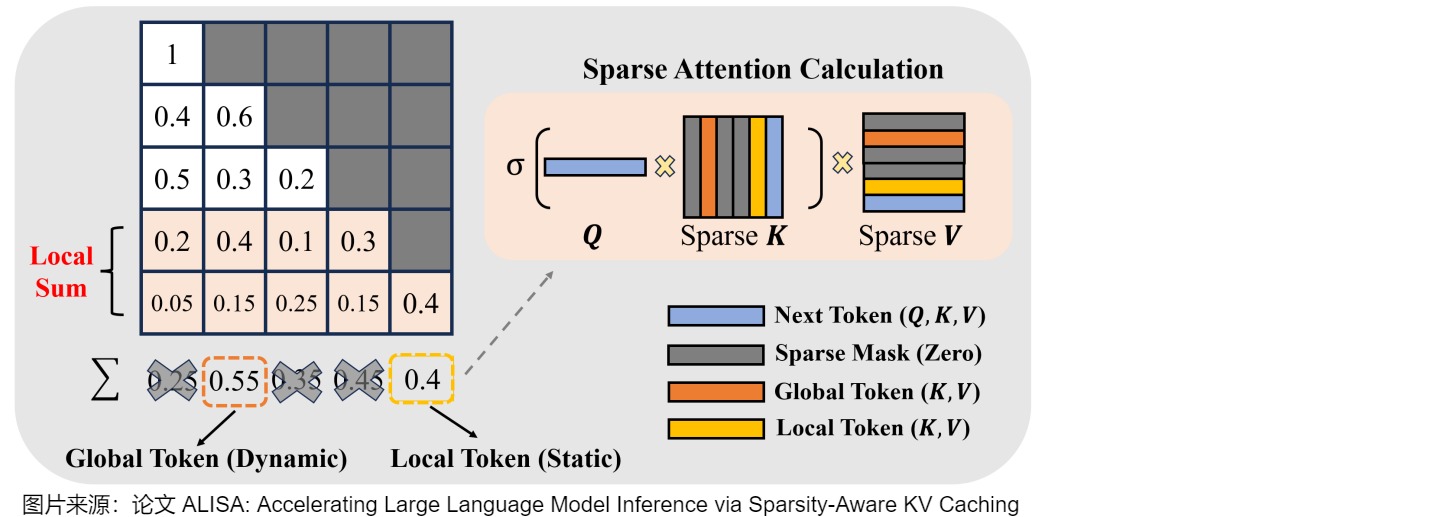
下图给出了动态调度机制。
0xFF 参考
聊聊大模型推理内存管理之 CachedAttention/MLA 刀刀宁
Y. Xiong, H. Wu, C. Shao, Z. Wang, R. Zhang, Y. Guo, J. Zhao, K. Zhang, and Z. Pan, “Layerkv: Optimizing large language model serving with layer-wise kv cache management,” 2024. [Online]. Available: https://arxiv.org/abs/2410.00428
B. Gao, Z. He, P. Sharma, Q. Kang, D. Jevdjic, J. Deng, X. Yang, Z. Yu, and P. Zuo, “Cost-efficient large language model serving for multi-turn conversations with cachedattention,” 2024. [Online]. Available: https://arxiv.org/abs/2403.19708
Y. Zhao, D. Wu, and J. Wang, “Alisa: Accelerating large language model inference via sparsity-aware kv caching,” 2024. [Online]. Available: https://arxiv.org/abs/2403.17312
R. Shahout, C. Liang, S. Xin, Q. Lao, Y. Cui, M. Yu, and M. Mitzenmacher, “Fast inference for augmented large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2410.18248
BatchLLM:离线大 Batch 场景 LLM 推理优化 程序猿李巡天
GPU加速LLM论文夸赞|InfiniGen通过动态KV Cache管理高效实现LLM的生成式推理:动机 GPUer
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition 赵尚春
Modular Attention Reuse for Low-Latency Inference(@yale.edu)
论文: 《Efficiently Programming Large Language Models using SGLang》
ZigZagKV,KVCache80%的压缩率可以达到近乎无损的效果
Efficient Prompt Caching via Embedding Similarity(@UC Berkeley)
Modular Attention Reuse for Low-Latency Inference(@yale.edu)
33 倍 LLM 推理性能提升:Character.AI 的最佳实践
[CLA] Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
[GQA] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
[KV Cache优化]MQA/GQA/YOCO/CLA/MLKV笔记: 层内和层间KV Cache共享 DefTruth
[LLM 推理服务优化] DistServe速读——Prefill & Decode解耦、模型并行策略&GPU资源分配解耦 阿杰
[LLM]KV cache详解 图示,显存,计算量分析,代码 莫笑傅立叶
[MLKV] MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
[MQA] Fast Transformer Decoding: One Write-Head is All You Need
[Prefill优化][万字]原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首Token时延优化 DefTruth
[YOCO] You Only Cache Once: Decoder-Decoder Architectures for Language Models
A Survey on Efficient Inference for Large Language Models
Cascade Inference: Memory Bandwidth Efficient Shared Prefix Batch Decoding
Continuous Batching:一种提升 LLM 部署吞吐量的利器 幻方AI
DejaVu:KV Cache Streaming For LLM
Efficient Streaming Language Models with Attention Sinks
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
https://lmsys.org/blog/2024-01-17-sglang/
Hydragen: High-Throughput LLM Inference with Shared Prefixes(@Stanford University)
Inference without Interference:混合下游工作负载的分离式LLM推理服务 竹言见智
kimi chat大模型的200万长度无损上下文可能是如何做到的? [GiantPandaCV](javascript:void(0)
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
LaViT:这也行,微软提出直接用上一层的注意力权重生成当前层的注意力权重 | CVPR 2024 VincentLee
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
LLaMa 原理+源码——拆解 (KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLU) Yuezero_
LLM Inference Series: 3. KV caching unveiled
LLM 推理优化探微 (2) :Transformer 模型 KV 缓存技术详解 Baihai IDP
LLM 推理优化探微 (3) :如何有效控制 KV 缓存的内存占用,优化推理速度? Baihai IDP
LLM推理入门指南②:深入解析KV缓存 OneFlow
LLM推理加速3:推理优化总结Mooncake/AttentionStore/vllm0.5/cache优化 etc
MiniCache 和 PyramidInfer 等 6 种优化 LLM KV Cache 的最新工作 AI闲谈
MLSys 2024 Keyformer:选择关键token,降低50%KV 缓存 MLSys2024 [MLSys2024](javascript:void(0)
MODEL TELLS YOU WHAT TO DISCARD: ADAPTIVE KV CACHE COMPRESSION FOR LLMS
Mooncake (1): 在月之暗面做月饼,Kimi 以 KVCache 为中心的分离式推理架构 ZHANG Mingxing
Mooncake (2):Kimi “泼天的流量”怎么接,分离架构下基于预测的调度策略 ZHANG Mingxing
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving 手抓饼熊
Orca: How to Serve Large-scale Transformer Models WXB506
OSDI22 ORCA:LLM Serving系统优化经典之作,动态batch,吞吐提升36倍 MLSys2024
OSDI24最新力作:InfiniGen大模型推理高效KV缓存管理框架,吞吐提升3倍,准确性提升32% MLSys2024
SnapKV: KV Cache 稀疏化,零微调加速长序列 LLM 推理 AI闲谈
SnapKV: LLM Knows What You are Looking for Before Generation
Token 稀疏化 + Channel 稀疏化:16 倍 LLM 推理加速 AI闲谈
Transformers KV Caching Explained
TriForce:KV Cache 稀疏化+投机采样,2.3x LLM 无损加速
vAttention:用于在没有Paged Attention的情况下Serving LLM BBuf
YOCO:长序列优化,1M 长文本10x LLM 推理加速 AI闲谈
You Only Cache Once: Decoder-Decoder Architectures for Language Models
ZHANG Mingxing:Mooncake (1): 在月之暗面做月饼,Kimi 以 KVCache 为中心的分离式推理架构
【手撕LLM- KV Cache】为什么没有Q-Cache ?? 小冬瓜AIGC
一文读懂KVCache 游凯超
为什么加速LLM推断有KV Cache而没有Q Cache? DefTruth
刀刀宁:笔记:Llama.cpp 代码浅析(一):并行机制与KVCache
刀刀宁:笔记:Llama.cpp 代码浅析(二):数据结构与采样方法
分析 GPT 模型自回归生成过程中的 KV Cache 优化技术 sudit
图解Mixtral 8 * 7b推理优化原理与源码实现 猛猿
图解大模型计算加速系列:分离式推理架构1,从DistServe谈起 猛猿
图解大模型计算加速系列:分离式推理架构2,模糊分离与合并边界的chunked-prefills 猛猿
图解大模型计算加速系列:分离式推理架构2,模糊分离与合并边界的chunked-prefills 猛猿
大模型并行推理的太祖长拳:解读Jeff Dean署名MLSys 23杰出论文 方佳瑞
大模型推理优化--Prefill阶段seq_q切分 kimbaol
大模型推理优化实践:KV cache复用与投机采样 米基 [阿里技术](javascript:void(0)
大模型推理优化技术-KV Cache [吃果冻不吐果冻皮](https://www.zhihu.com
/people/liguodong-iot)
大模型推理加速:KV Cache Sparsity(稀疏化)方法 歪门正道
大白话解说Continous Batching Gnuey Iup
微软 MInference:百万 Token 序列,10x 加速
思辨|H2O: 从缓存视角解决LLM长上下文问题 DSTS Center [数据空间技术与系统](javascript:void(0)
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率 哆啦不是梦
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率 哆啦不是梦
月之暗明的月饼:以KVCache为中心,分离式推理架构,LLM吞吐能力飙升75%
极限探索:LLM推理速度的深度解析 MLSys2024
符尧博士-全栈Transformer推理优化第二季:部署长上下文模型-翻译 强化学徒
阿杰:vLLM & PagedAttention 论文深度解读(一)—— LLM 服务现状与优化思路
Efficient Streaming Language Models with Attention Sinks
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
ZigZagKV,KVCache80%的压缩率可以达到近乎无损的效果 杜凌霄
SnapKV: LLM Knows What You are Looking for Before Generation
FastGen:Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
[Prompt Cache]: Modular Attention Reuse for Low-Latency Inference(@yale.edu)
[Cache Similarity]: Efficient Prompt Caching via Embedding Similarity(@UC Berkeley)
[Shared Prefixes]: Hydragen: High-Throughput LLM Inference with Shared Prefixes(@Stanford University)
[ChunkAttention]: ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition(@microsoft.com)
ClusterKV,接近无损的KV Cache压缩方法 杜凌霄
图解大模型计算加速系列:分离式推理架构2,模糊分离与合并边界的chunked-prefills 猛猿
《基于KV Cache管理的LLM加速研究综述》精炼版 常华Andy
[KV Cache优化]MQA/GQA/YOCO/CLA/MLKV笔记: 层内和层间KV Cache共享 DefTruth
Venkat Raman. Essential math & concepts for llm inference, 2024. URL https://venkat.e u/essential-math-concepts-for-llm-inference#heading-insights-from-model-lat ency-amp-understanding-hardware-utilization-on-modern-gpus.
Yao Fu. Challenges in deploying long-context transformers: A theoretical peak performance analysis. arXiv preprint arXiv:2405.08944, 2024
A Survey on Large Language Model Acceleration based on KV Cache Management
探秘Transformer系列之(24)--- KV Cache优化的更多相关文章
- Library Cache优化与SQL游标
Library Cache主要用于存放SQL游标,而SQL游标最大化共享是Library Cache优化的重要途径,可以使SQL运行开销最低.性能最优. 1 SQL语句与父游标及子游标 在PL/SQL ...
- Mysql高手系列 - 第24篇:如何正确的使用索引?【高手进阶】
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 欢迎大家加我微信itsoku一起交流java.算法.数据库相关技术. 这是Mysql系列第24篇. 学习索引,主要是 ...
- c/c++性能优化--- cache优化的一点杂谈
之前写了一篇关于c/c++优化的一点建议,被各种拍砖和吐槽,有赞成的有反对的,还有中立的,网友对那篇博客的的评论和吐槽,我一个都没有删掉,包括一些具有攻击性的言论.笔者有幸阅读过IBM某个项目的框架代 ...
- 程序员收藏必看系列:深度解析MySQL优化(二)
程序员收藏必看系列:深度解析MySQL优化(一) 性能优化建议 下面会从3个不同方面给出一些优化建议.但请等等,还有一句忠告要先送给你:不要听信你看到的关于优化的“绝对真理”,包括本文所讨论的内容,而 ...
- java高并发系列 - 第24天:ThreadLocal、InheritableThreadLocal(通俗易懂)
java高并发系列第24篇文章. 环境:jdk1.8. 本文内容 需要解决的问题 介绍ThreadLocal 介绍InheritableThreadLocal 需要解决的问题 我们还是以解决问题的方式 ...
- [转帖]TPC-C解析系列05_TPC-C基准测试之存储优化
TPC-C解析系列05_TPC-C基准测试之存储优化 http://www.itpub.net/2019/10/08/3332/ 蚂蚁金服科技 2019-10-08 11:27:02 本文共3664个 ...
- [转帖]TPC-C解析系列03_TPC-C基准测试之SQL优化
TPC-C解析系列03_TPC-C基准测试之SQL优化 http://www.itpub.net/2019/10/08/3330/ TPC-C是一个非常严苛的基准测试模型,考验的是一个完备的关系数据库 ...
- 编译器优化丨Cache优化
摘要:本文重点介绍几种通过优化Cache使用提高程序性能的方法. 本文分享自华为云社区<编译器优化那些事儿(7):Cache优化>,作者:毕昇小助手. 引言 软件开发人员往往期望计算机硬件 ...
- SSE图像算法优化系列二十二:优化龚元浩博士的曲率滤波算法,达到约1000 MPixels/Sec的单次迭代速度
2015年龚博士的曲率滤波算法刚出来的时候,在图像处理界也曾引起不小的轰动,特别是其所说的算法的简洁性,以及算法的效果.执行效率等方面较其他算法均有一定的优势,我在该算法刚出来时也曾经有关注,不过 ...
- 移动端重构系列-移动端html页面优化
对于访问量大的网站来说,前端的优化是必须的,即使是优化1KB的大小对其影响也很大,下面来看看来自ISUX的米随随讲讲移动手机平台的HTML5前端优化,或许对你有帮助和启发. 概述 1. PC优化手段在 ...
随机推荐
- 一点区块链资料-copy
1. 场景描述 (1)今天找资料,无意中看到15年底-16年初弄的关于区块链的资料,当时写了个交流汇报区块链的ppt,感觉挺好的,共享下,希望能帮助朋友们理解区块链. (2)背景:15年底,老板从朋友 ...
- ZUC-S盒输入输出测试
问题 实现以二进制.十进制.十六进制的形式输入,经过S盒,输出十六进制 输入: 1.二进制:10001010010011110000011110111101 2.十进制:2320435133 3.十六 ...
- Win10 20H2 家庭版 环境变量
20H2 家庭版设置环境变量,此电脑--->属性,弹出的是新版本的设置界面,选择左侧的"关于",在最右侧的"相关设置"里面,选择"高级系统设置& ...
- 智算引领 AI启航,中国电信天翼云助推辽宁数智发展!
近日,中国电信辽宁公司"智算引领 AI启航"新质生产力赋能辽宁新时代"六地"建设大会在沈阳圆满落幕.辽宁省工业和信息化厅,省国资委,省数据局,省农业农村厅,沈阳 ...
- 基于开源Drasi 实时监控和自动响应系统
Drasi 是微软使用MIT协议开源的一个项目,已经提交到CNCF孵化,github:https://github.com/drasi-project/drasi-platform/ ,他提供了一个集 ...
- mysql之事务范例
package com.yeyue.lesson04; import com.yeyue.lesson02.JdbcUtils; import java.sql.Connection; import ...
- 在 GitLab CI/CD 中使用内置的容器镜像库
配置 Docker-in-Docker Docker-in-Docker (dind) means: 你应该注册一个 Docker executor 或 Kubernetes executor 执行器 ...
- LLM探索:离线部署Ollama和one-api服务
前言 之前已经在Linux服务器上使用Ollama部署了DeepSeek 这次在没有外网(应该说是被限制比较多)的服务器上部署,遇到一些坑,记录一下 ollama ollama 自然无法使用在线安装脚 ...
- Vue3 数据响应式原理与高效数据操作全解析
一.Vue3 数据响应式原理 (一)Proxy 替代 Object.defineProperty 在 Vue2 中,数据响应式是通过 Object.defineProperty 实现的.这种方法虽然能 ...
- [JXOI2017] 加法 题解
最小值最大,考虑二分答案,问题转为判断最小值是否能 \(\ge x\). 假如 \(a_i\ge x\),那我们肯定不管:假如 \(a_i<x\),那最好能让选择的区间 \(r\) 值更大,用优 ...