AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
引言
在当今这个数据爆炸的时代,信息的快速存储与高效检索已经成为技术领域的核心挑战。随着人工智能(AI)和机器学习(ML)的迅猛发展,向量存储和相似性搜索技术逐渐崭露头角,成为处理海量数据的利器。对于使用 .NET 的开发者来说,掌握这些技术不仅意味着能够开发出更智能、更高效的应用,更是在信息洪流中保持竞争力的关键。借助向量存储,我们可以将复杂的数据(如文本、图像或音频)转化为高维向量,通过相似性搜索快速找到与查询最相关的内容,从而大幅提升信息检索的精度和效率。
向量存储和相似性搜索的应用潜力令人振奋。从智能推荐系统到图像检索工具,再到自然语言处理(NLP)中的语义搜索,这些技术正在重塑我们与数据的交互方式。通过在向量空间中使用距离度量(如余弦相似度或欧氏距离),开发者可以实现高效的匹配机制,为用户提供个性化的体验。然而,技术的实现并非一帆风顺,高维数据的存储、计算资源的优化、索引结构的构建以及实时性能的保障,都是开发者需要面对的难题。
本文将通过一个具体的实践任务——实现一个简单的文档相似性搜索系统,深入探讨如何在 .NET 中应用向量存储和相似性搜索技术。我们将从基础知识入手,逐步介绍向量存储的选择与使用,并通过清晰的代码示例,引导读者完成一个功能完备的搜索应用。
希望本文能为你打开向量存储的大门,激发你在 .NET 开发中探索智能技术的热情。
向量存储和相似性搜索基础知识
在进入实践之前,我们先来梳理向量存储和相似性搜索的基本概念及其工作原理。
什么是向量存储?
向量存储(Vector Store)是一种专门设计用于存储和检索高维向量的数据库系统。在 AI 和 ML 领域,数据通常被转化为高维向量(称为 embeddings),以捕捉其语义或特征信息。例如,一段文本可以通过预训练模型(如 BERT)转换为一个 384 维的向量,图像可以通过卷积神经网络提取特征向量。向量存储通过优化这些高维数据的存储结构和查询机制,支持快速的相似性搜索,帮助开发者高效地找到与查询最相关的内容。
什么是相似性搜索?
相似性搜索(Similarity Search)是一种旨在找到与查询项最相似的项的搜索技术。在向量空间中,相似性通常通过距离度量来衡量,常见的度量方法包括:
余弦相似度:计算两个向量夹角的余弦值,反映方向的相似性,广泛用于文本搜索。 欧氏距离:计算两个向量间的直线距离,常用于图像和数值数据的匹配。 曼哈顿距离:计算向量在各维度上的差值之和,适用于特定场景。
通过这些度量,相似性搜索能够在海量数据中快速定位与查询最接近的结果,极大地提升了搜索效率。
向量存储的工作原理
向量存储依赖以下核心技术来实现高效的存储和查询:
索引结构:如 KD-Tree、HNSW(层次可导航小世界图),用于加速相似性搜索。 近似最近邻(ANN):通过牺牲少量精度换取更高的搜索速度,适用于大规模数据集。 分布式架构:支持数据的并行处理和存储,满足高并发需求。
这些技术的结合使得向量存储能够应对高维数据的挑战,为实时应用提供强大支持。
选择和使用向量存储
在 .NET 中实现向量存储和相似性搜索,开发者可以选择多种工具和服务。以下是几个常见选项:
Milvus
Milvus 是一个开源的向量数据库,专为高维向量存储和搜索设计。它支持多种索引类型(如 HNSW、IVF)和距离度量,提供高性能的搜索能力。Milvus 可通过 RESTful API 或客户端 SDK 与 .NET 集成。
qDrant
qDrant 是一个轻量级向量数据库,适合中小规模应用。它支持实时数据插入和搜索,提供简单易用的 API,方便快速上手。
Azure AI Search
Azure AI Search 是微软提供的云端搜索服务,支持向量搜索和全文搜索。它与 Azure 生态无缝集成,适合企业级应用。
本文将以 Milvus 为例,展示如何在 .NET 中实现向量存储和搜索。Milvus 以其高性能和灵活性,成为许多 AI 项目的首选。
实现文档相似性搜索系统
为了帮助读者深入理解向量存储的实际应用,我们将实现一个简单的文档相似性搜索系统。该系统能够将文档转换为向量,存储到 Milvus 中,并支持用户查询相似文档。
系统设计
系统的核心组件包括:
文档向量化:使用预训练模型将文本转换为向量。 向量存储:将向量存储到 Milvus 并构建索引。 相似性搜索:根据用户查询生成向量并搜索相似结果。 结果展示:返回最相似的文档。
我们将使用 SentenceTransformers 生成向量,并通过 Milvus 实现存储和搜索。
准备工作
在开始之前,需要完成以下准备:
创建Milvus-Test文件夹,并新建如下文件夹:
下载milvus-standalone-docker-compose.yml,重命名成docker-compose.yml后移入到刚刚创建好的Milvus-Test文件夹中
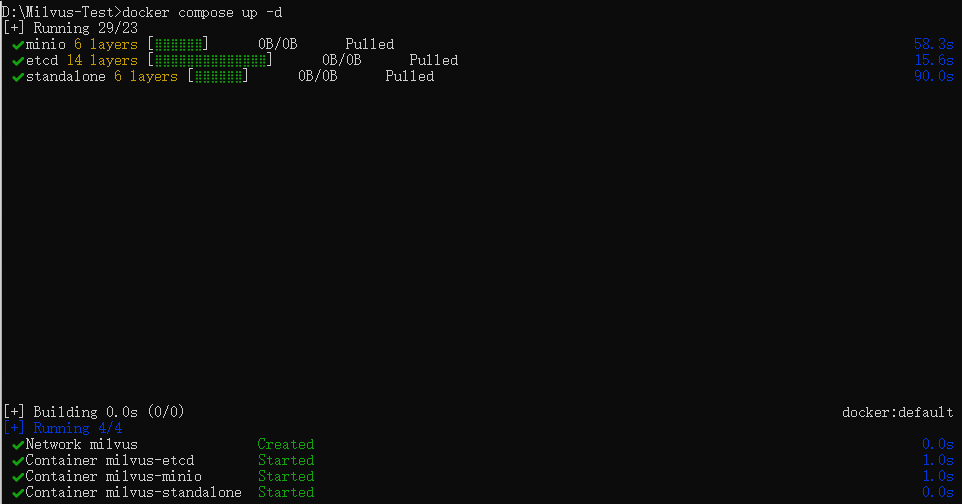
安装 Milvus:使用 Docker 部署 Milvus(
docker compose up -d)

实现步骤
1. 文档向量化
首先,使用 SentenceTransformers 将文档转换为向量(需 Python 环境):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = ["This is document one.", "This is document two.", "This is document three."]
embeddings = model.encode(documents)
embeddings 是包含每个文档向量的数组(维度为 384)。
2. 存储向量到 Milvus
安装Nuget包:
dotnet add package Milvus.Client --version 2.3.0-preview.1
使用 C# 检测 Milvus 是否正常运行的代码:
MilvusClient milvusClient = new MilvusClient("{Endpoint}", "{Port}", "{Username}", "{Password}", "{Database}(Optional)");
MilvusHealthState result = await milvusClient.HealthAsync();

使用 C# 调用 Milvus 创建集合代码:
string collectionName = "book";
MilvusCollection collection = milvusClient.GetCollection(collectionName);
//Check if this collection exists
var hasCollection = await milvusClient.HasCollectionAsync(collectionName);
if(hasCollection){
await collection.DropAsync();
Console.WriteLine("Drop collection {0}",collectionName);
}
await milvusClient.CreateCollectionAsync(
collectionName,
new[] {
FieldSchema.Create<long>("book_id", isPrimaryKey:true),
FieldSchema.Create<long>("word_count"),
FieldSchema.CreateVarchar("book_name", 256),
FieldSchema.CreateFloatVector("book_intro", 2L)
}
);
使用 C# 调用 Milvus 插入向量代码:
Random ran = new ();
List<long> bookIds = new ();
List<long> wordCounts = new ();
List<ReadOnlyMemory<float>> bookIntros = new ();
List<string> bookNames = new ();
for (long i = 0L; i < 2000; ++i)
{
bookIds.Add(i);
wordCounts.Add(i + 10000);
bookNames.Add($"Book Name {i}");
float[] vector = new float[2];
for (int k = 0; k < 2; ++k)
{
vector[k] = ran.Next();
}
bookIntros.Add(vector);
}
MilvusCollection collection = milvusClient.GetCollection(collectionName);
MutationResult result = await collection.InsertAsync(
new FieldData[]
{
FieldData.Create("book_id", bookIds),
FieldData.Create("word_count", wordCounts),
FieldData.Create("book_name", bookNames),
FieldData.CreateFloatVector("book_intro", bookIntros),
});
// Check result
Console.WriteLine("Insert count:{0},", result.InsertCount);
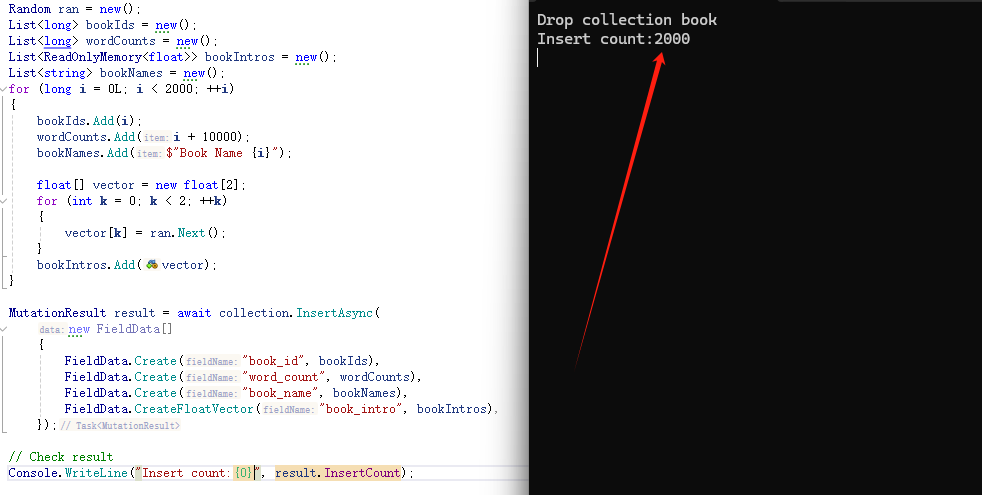
3. 构建索引
为加速搜索,需在集合上构建索引:
MilvusCollection collection = milvusClient.GetCollection(collectionName);
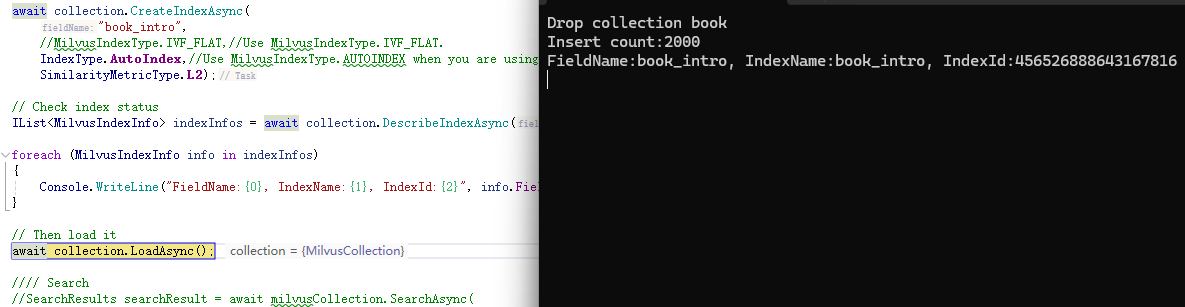
await collection.CreateIndexAsync(
"book_intro",
//MilvusIndexType.IVF_FLAT,//Use MilvusIndexType.IVF_FLAT.
IndexType.AutoIndex,//Use MilvusIndexType.AUTOINDEX when you are using zilliz cloud.
SimilarityMetricType.L2);
// Check index status
IList<MilvusIndexInfo> indexInfos = await collection.DescribeIndexAsync("book_intro");
foreach(var info in indexInfos){
Console.WriteLine("FieldName:{0}, IndexName:{1}, IndexId:{2}", info.FieldName , info.IndexName,info.IndexId);
}
// Then load it
await collection.LoadAsync();
}
4. 实现相似性搜索
根据用户查询搜索相似文档:
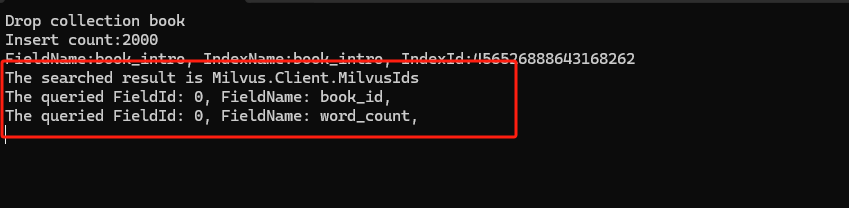
List<string> search_output_fields = new() { "book_id" };
List<List<float>> search_vectors = new() { new() { 0.1f, 0.2f } };
SearchResults searchResult = await collection.SearchAsync(
"book_intro",
new ReadOnlyMemory<float>[] { new[] { 0.1f, 0.2f } },
SimilarityMetricType.L2,
limit: 2);
// Query
string expr = "book_id in [2,4,6,8]";
QueryParameters queryParameters = new ();
queryParameters.OutputFields.Add("book_id");
queryParameters.OutputFields.Add("word_count");
IReadOnlyList<FieldData> queryResult = await collection.QueryAsync(
expr,
queryParameters);
5. 集成到应用
❝
后面要做的事情就很多了,大家可以自行发挥,当然有兴趣的朋友还可以安装attu ui界面作为
Milvus的客户端,小编并没有安装,因此我截取官方图片让大家看一下,地址为:https://github.com/zilliztech/attu/releases。
实际应用中的意义与挑战
意义
提升用户体验:语义搜索提供更精准的结果。 多模态支持:可扩展到图像、音频等领域。 效率优化:加速信息检索和决策。
挑战
资源需求:高维数据需要大量计算和存储资源。 索引优化:需平衡速度与精度。 实时性:高并发场景下的性能保障。
结语
本文通过理论与实践结合,展示了在 .NET 中实现向量存储和相似性搜索的方法。希望你能从中获得启发,在智能应用的浪潮中找到自己的位置。向量存储的潜力无限,让我们共同探索这一领域,在技术的海洋里尽情驰骋!
参考链接:
https://www.nuget.org/packages/Milvus.Client/ https://github.com/zilliztech/attu/blob/main/.github/images/collection_overview.png
AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现的更多相关文章
- 技术实操丨HBase 2.X版本的元数据修复及一种数据迁移方式
摘要:分享一个HBase集群恢复的方法. 背景 在HBase 1.x中,经常会遇到元数据不一致的情况,这个时候使用HBCK的命令,可以快速修复元数据,让集群恢复正常. 另外HBase数据迁移时,大家经 ...
- (DT系列五)Linux kernel 是怎么将 devicetree中的内容生成plateform_device
Linux kernel 是怎么将 devicetree中的内容生成plateform_device 1,实现场景(以Versatile Express V2M为例说明其过程)以arch/arm/ma ...
- 【转】(DT系列五)Linux kernel 是怎么将 devicetree中的内容生成plateform_device
原文网址:http://www.cnblogs.com/biglucky/p/4057495.html Linux kernel 是怎么将 devicetree中的内容生成plateform_devi ...
- (DT系列五)Linux kernel 是怎么将 devicetree中的内容生成plateform_device【转】
转自:https://blog.csdn.net/lichengtongxiazai/article/details/38942033 Linux kernel 是怎么将 devicetree中的内容 ...
- 原创:vsphere概念深入系列五:存储
1.vSphere支持的存储文件格式: 类似于linux下挂载文件系统,需要有驱动器设备,驱动. 挂载后有挂载路径. vSphere 也是一样处理. 挂载名:挂载后可以给存储设备起名,默认为datas ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- .net基础学java系列(四)Console实操
上一篇文章 .net基础学java系列(三)徘徊反思 本章节没啥营养,请绕路! 看视频,不实操,对于上了年龄的人来说,是记不住的!我已经看了几遍IDEA的教学视频: https://edu.51cto ...
- Linux基础实操五
实操一:nginx服务 二进制安装nginx包1) 1)#yum clean all 2)#yum install epel-release -y 3)#yum install nginx -y 1) ...
- 如何练习python?有这五个游戏,实操经验就已经够了
现在学习python的人越来越多了,但仅仅只是学习理论怎么够呢,如何练习python?已经是python初学者比较要学会的技巧了! 其实,最好的实操练习,就是玩游戏. 也许你不会信,但这五个小游戏足够 ...
- Istio的流量管理(实操一)(istio 系列三)
Istio的流量管理(实操一)(istio 系列三) 使用官方的Bookinfo应用进行测试.涵盖官方文档Traffic Management章节中的请求路由,故障注入,流量迁移,TCP流量迁移,请求 ...
随机推荐
- 解决用netty去做web服务时,post长度过大的问题
原文地址 http://my.oschina.net/momohuang/blog/114552 先说一下,本来是想自己写socket ,启动一个简单点的web服务用于接收数据的.写完之后,发现会有各 ...
- Uninstall or delete MariaDB completely for re-installation
I am new to this forum so pse forgive me if I am asking a question which already has been answered. ...
- GenericObjectPool 避免泄漏
GenericObjectPool GenericObjectPool 是 Apache Commons Pool 提供的对象池,使用的时候需要调用 borrowObject 获取一个对象,使用完以后 ...
- IntelliJ IDEA生成jar包运行报Error:A JNI error has occurred,please check your installation and try again
首先介绍一下IntelliJ IDEA生成jar包的方式: 1.打开项目,打开FIile->Project Structure...菜单.如下图: 选中Artifacts,点+号,选择JAR,再 ...
- Qt交叉编译整理的几点说明
关于交叉编译,对于初学者来说是个极难跨过去的砍(一旦跨过去了,以后遇到需要交叉编译的时候都是顺水推舟.信手拈来.),因为需要搭建交叉编译环境,好在现在厂家提供的板子基本上都是测试好的环境,尤其是提供的 ...
- Qt编写地图综合应用2-迁徙图
一.前言 在很多web系统中,尤其是大屏系统中,经常可以看到类似于飞机迁徙图的效果,这个在echart中也是最常用的一个效果,迁徙图既可以是一个飞机也可以是其他形状,然后有一条动态的移动轨迹来表示流向 ...
- Qt音视频开发15-mpv事件订阅
一.前言 在使用libmpv的过程中,通过对mpv事件订阅,可以更准确和准时的得知一些事件,比如文件打开成功,播放状态的改变等,而不需要定时器去读取状态,尤其是打开成功这个事件,如果不采用事件订阅,有 ...
- 主动式AI(代理式)与生成式AI的关键差异与影响
大型语言模型(LLMs)如GPT可以生成文本.回答问题并协助完成许多任务.然而,它们是被动的,这意味着它们仅根据已学到的模式对接收到的输入作出响应.LLMs无法自行决策:除此之外,它们无法规划或适应变 ...
- IM开发技术学习:揭秘微信朋友圈这种信息推流背后的系统设计
本文由徐宁发表于腾讯大讲堂,原题"程序员如何把你关注的内容推送到你眼前?揭秘信息流推荐背后的系统设计",有改动和修订. 1.引言 信息推流(以下简称"Feed流" ...
- token、jwt、oauth2、session对比总结
什么是认证(Authentication) 通俗地讲就是验证当前用户的身份,证明"你是你自己"(比如:你每天上下班打卡,都需要通过指纹打卡,当你的指纹和系统里录入的指纹相匹配时,就 ...