DrissionPage采集抖音搜索结果详情信息及各视频的评论详情
目前正在做的一个项目,因为涉及到社交媒体的相关数据,在采集douyin数据的时候接触到了DrissionPage这个库,相对于该帖子发布的时间来说,该库的时效性较新,且目前在数据采集领域也属于较为新颖的方法。
DissionPage官网:概述 | DrissionPage官网 是国内大神开源的项目,有能力可以多多支持,目前作者还有在不断维护
代码参考:
参考了b站@时一十一姐呀 的讲解视频 p0一个暂时放弃逆向奔向爬虫自动化数据采集的故事_哔哩哔哩_bilibili
还有一个不知道是哪位老师的课:https://www.bilibili.com/video/BV1LJ4m1L7nB/?spm_id_from=333.337.search-card.all.click
话不多说,现在开始。
第一章 DrissionPage采集douyin搜索结果详情信息
目的:根据关键词在douyin搜索相关短视频,记录短视频的相关信息,包括视频ID、标题、点赞评论数,作者信息等。
实现:
1、一些需要了解的前置知识
①了解douyin搜索机制
这里有一个大坑,我个人在这里卡了好久;作者第一时间想到的是进入douyin首页,然后通过DrissionPage的ele().input()方法输入关键词,但是这里如果按照这种方法进入搜索结果详情页会导致接下来DrissionPage的scroll.to_bottom()方法失效;
解决方法:douyin搜索可以直接在地址后面加video/tag? 即可,如:将url设置为:https://www.douyin.com/video/黄山旅游? ;再通过DrissionPage的get方法获取该页面后,即可成功使用scroll.to_bottom()方法,具体原因作者才疏学浅也搞不懂为啥。
代码:
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.set.timeouts(3)
page.get('https://www.douyin.com/video/黄山旅游?')
page.wait(3)
page.scroll.to_bottom()
②了解搜索结果json数据包
douyin搜索结果的json数据包为aweme/v1/web/general/search/single/,使用DrissionPage监听数据包并采集,即可实现搜索结果数据采集。
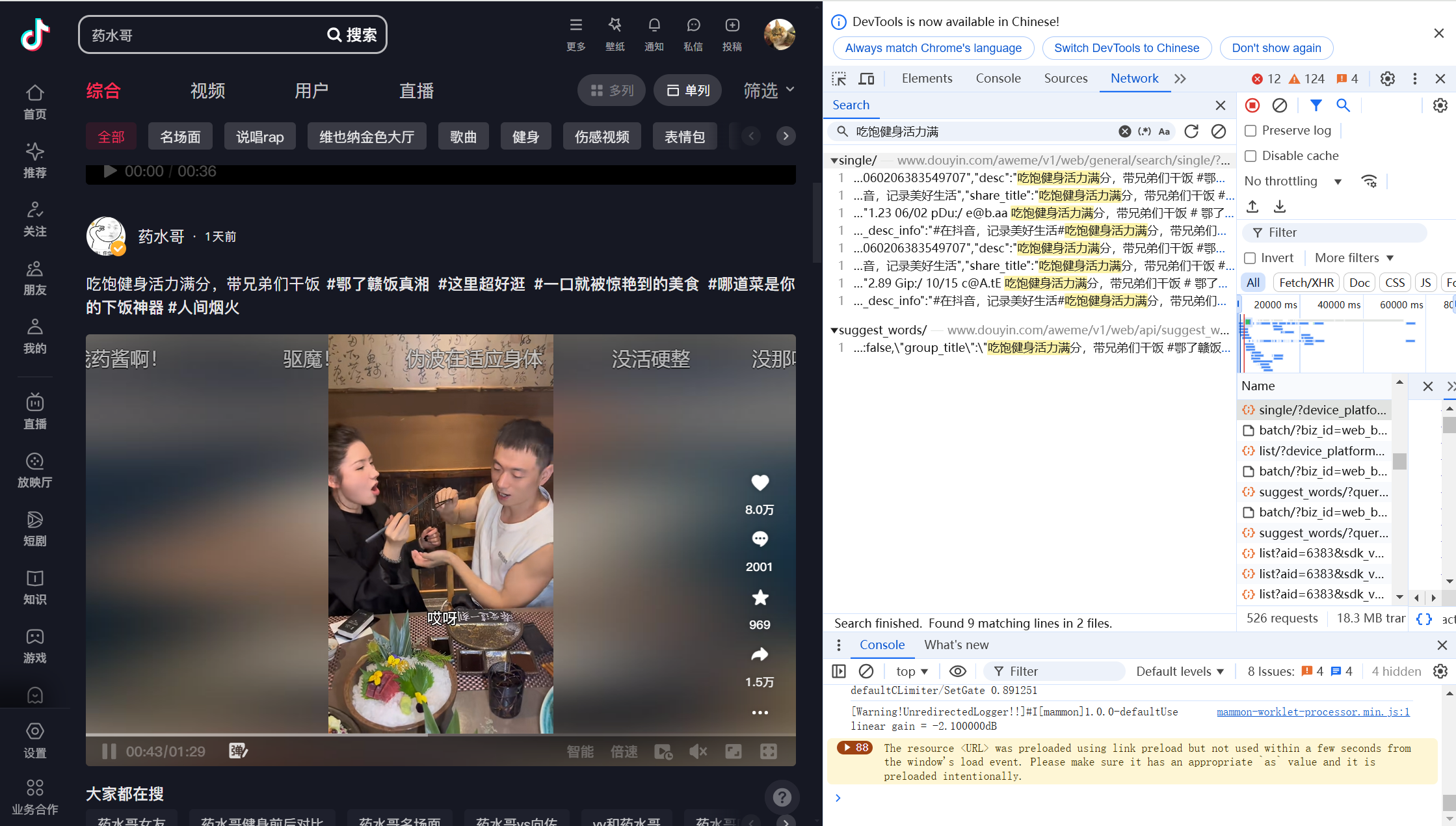
知道具体要监听的json数据包后,即可使用DrissionPage采集啦,然后解析一下数据包格式就可以获得想要的信息啦。
2、具体代码实现
不多说,直接上完整代码,这里只展示获取一个tag的搜索结果,想获取更多的话自己改改就行,不会改可以带价私我:
from DrissionPage import ChromiumPage
import datetime
import csv
#社交媒体
##douyin,按搜索结果收集涉及视频。
page = ChromiumPage()
page.set.timeouts(3) page.get('https://www.douyin.com/search/药水哥?')
page.listen.start('aweme/v1/web/general/search/single/') f = open('data.csv', mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['vd_id',"vd_title","create_time","author"])
csv_writer.writeheader() #采集多少页,循环多少次就行
for i in range(10):
print(f'正在采集{i+1}页内容')
resp = page.listen.wait()
json_data = resp.response.body
# print(json_data) for i in range(len(json_data['data'])): if json_data['data'][i]['type'] == 1: vd_id = json_data['data'][i]['aweme_info']['aweme_id']
vd_title = json_data['data'][i]['aweme_info']['desc'] create_time = str(datetime.datetime.fromtimestamp(json_data['data'][i]['aweme_info']['create_time'])) author_nickname = json_data['data'][i]['aweme_info']['author']['nickname']
enterprise_verify = json_data['data'][i]['aweme_info']['author']['enterprise_verify_reason'] vd_info = {
"vd_id":vd_id,
"vd_title":vd_title,
"create_time":create_time,
"author":{
"author_nickname":author_nickname,
"enterprise_verify":enterprise_verify
}
}
csv_writer.writerow(vd_info)
else:
continue
page.scroll.to_bottom()
print(f'A total of {i+1} data pieces were collected!————————————————————————————————————————————————————')
比较懒,不喜欢标注释,有问题直接评论找我。
第二章 DrissionPage采集douyin视频评论信息
上述实现按tag获取douyin搜索的结果,不包含视频下载,因为这次涉及的项目主要做的文本分析,所以上述代码中没涉及到视频获取,想要获取视频也比较简单,找到视频对应的地址下载就行,有兴趣的可以在网上找找看看。
接下来要介绍一下收集到的视频的评论数据如何获取,依旧按上述的讲解步骤进行。
目的:获取各视频的评论信息。
实现:
1、需要了解的前置知识
①视频评论数据获取不建议和检索结果一同采集
为什么会有这个见意呢?主要出于如下原因:1)如果从检索结果页点击进入视频详情页,视频详情页会较为复杂,且涉及局部滚动,有点点繁琐;2)直接从视频id进入详情页会简单些,且上一步我们已经获取到了检索结果的各视频id。
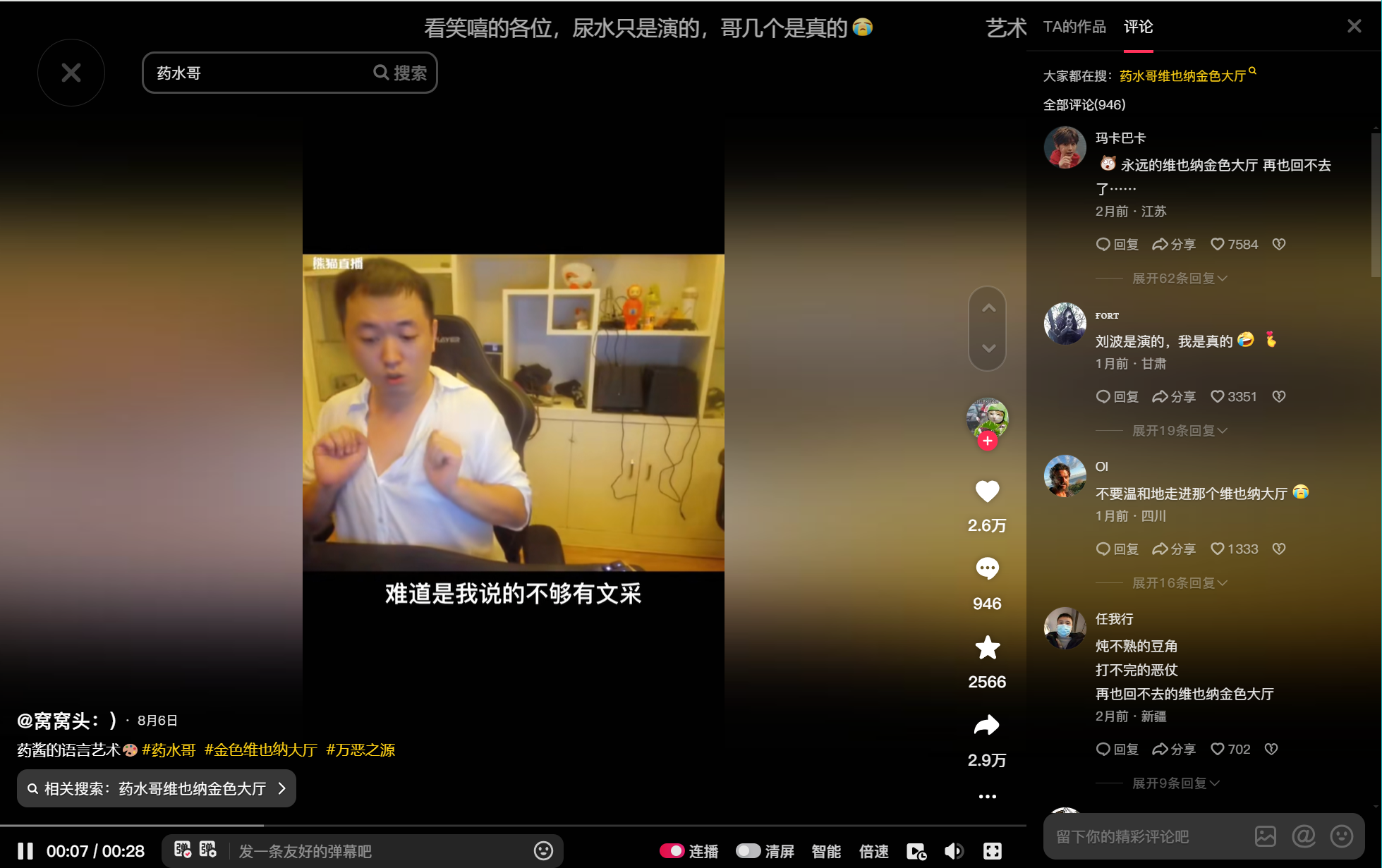
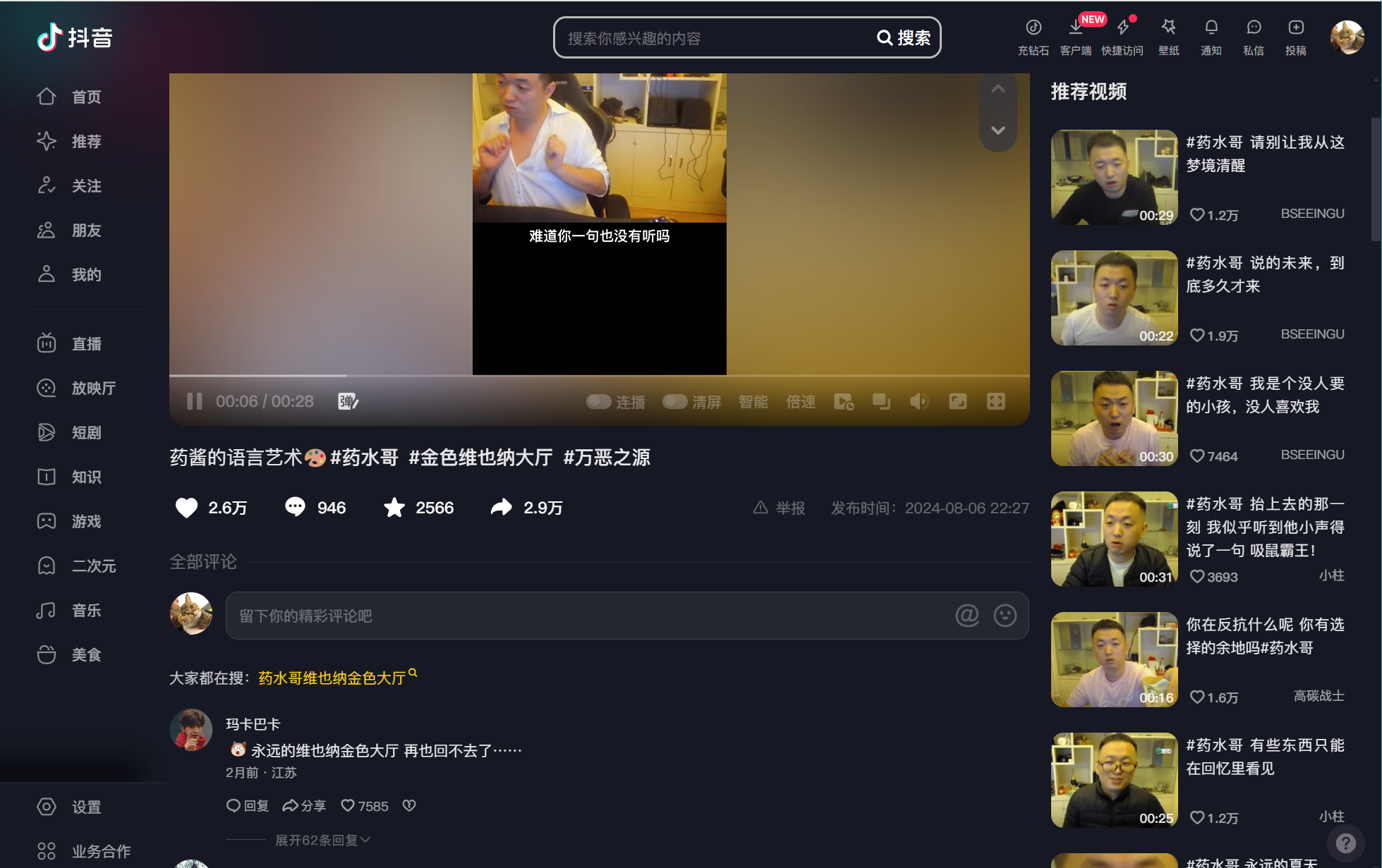
②评论数据的json数据包
获取方法和上面1中所述是一样的,就先在开发者模式下搜索评论,再找到对应的json,观察一下json的数据格式,按需提取想要的信息就行,不截图也不再演示了,直接给出需要监听的json地址:'aweme/v1/web/comment/list/'
③详情页滚动如何实现
进入详情页后,如果直接运行page.scroll.to_bottom()会发现根本无法实现评论也翻页,也就没法加载出新的评论Json数据,这里我在b站看的视频就是直接用的这行代码,不知道是因为douyin这边更新了还是说怎么滴,反正我按他视频里的方法就是没法实现翻页。于是我看了b站@时一十一姐呀 的视频,私信请教了她,她的回复解决了我疑问,我这边就不说为啥了,直接给出解决方案:找到滚动条定义为一个元素,然后再使用DrissionPage的actions.scroll()方法对定义的元素进行翻页操作即可;
button = page.ele('.:parent-route-container route-scroll-container IhmVuo1S')
page.actions.scroll(500,0,button)
但是这里的翻页操作只能定义翻页距离,不能像scroll.to_bottom() 方法那样直接翻页到底部,所以这里coding时就需要调整一下思路了,这里也是参考了十一姐的思路进行修改的。
2、代码实现
不说废话,直接上代码,这里也是仅展示提取一条视频评论时的代码,想要提取多条的话自己改改就行,不会改可以带价私信我。
##按视频编号收集评论数据
import pandas as pd data = pd.read_csv('./data.csv') page = ChromiumPage()
page.set.timeouts(3) url='https://www.douyin.com/video/'+str(data['vd_id'][0])
page.listen.start('aweme/v1/web/comment/list/')
button = page.ele('.:parent-route-container route-scroll-container IhmVuo1S') import time
time.sleep(5) # f = open('comments.csv', mode='a',encoding='utf-8',newline='')
# csv_writer = csv.DictWriter(f,fieldnames=['昵称',"地区","时间","评论"])
# csv_writer.writeheader() print(f'page 1 is collected')
resp = page.listen.wait()
json_data = resp.response.body
#print(json_data)
comments = json_data['comments']
comments_old = comments
for index in comments:
text = index['text']
nickname = index['user']['nickname']
create_time = index['create_time']
date = str(datetime.datetime.fromtimestamp(create_time))
ip_label = index['ip_label']
dit = {
"昵称": nickname,
"地区": ip_label,
"时间": date,
"评论": text
}
# csv_writer.writerow(dit)
print(dit) i=0
while True:
page.actions.scroll(500,0,button)
resp = page.listen.wait()
json_data = resp.response.body
#print(json_data)
comments = json_data['comments'] if comments == comments_old:
continue
else:
i += 1
for index in comments:
text = index['text']
nickname = index['user']['nickname']
create_time = index['create_time']
date = str(datetime.datetime.fromtimestamp(create_time))
ip_label = index['ip_label']
dit = {
"昵称": nickname,
"地区": ip_label,
"时间": date,
"评论": text
}
# csv_writer.writerow(dit)
print(dit)
if i >= 5:
#想要获取多少页可以在这里设置
print(f'已收集{i+1}页评论,现在停止!')
break
和上面一样,比较懒不喜欢注释,有问题可以直接问,想要定制带价私。
DrissionPage采集抖音搜索结果详情信息及各视频的评论详情的更多相关文章
- 【爬虫集合】抖音API分析
1. 分析接口 Charles注册码 Registered Name: https://zhile.io License Key: 48891cf209c6d32bf4 抖音API分析 抖音.猫眼网页 ...
- 刷抖音太累,教你用Python把高颜值的小姐姐都爬下来慢慢看
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 星安果.AirPython 目 标 场 景 相信大家平时刷抖音短视频 ...
- PHP根据抖音的分享链接来抓包抖音视频
现在抖音是个很火的短视频平台,上面有许多不错的小视频.今天教大家怎么用PHP技术来获取到抖音上的的内容. 1:打开抖音选中你认为好的视频点击分享,复制链接,然后你会获取到如下的内容: #科比 愿你去的 ...
- Python音视频开发:消除抖音短视频Logo和去电视台标
☞ ░ 前往老猿Python博文目录 ░ 一.引言 对于带Logo(如抖音Logo.电视台标)的视频,有三种方案进行Logo消除: 直接将对应区域用对应图像替换: 直接将对应区域模糊化: 通过变换将要 ...
- Vegas教程:教你制作抖音热门人物穿越门窗特效
抖音上经常会有很多特效视频,例如换妆.分镜.合拍.放大等,合适的特效总是会让视频更加出彩.这些特效,除了一部分是抖音自带以外,很多都是用的其他视频特效软件制作而成.这些视频编辑软件操作简单易上手,强大 ...
- Python音视频开发:消除抖音短视频Logo和去电视台标的实现详解
☞ ░ 前往老猿Python博文目录 ░ 一.引言 对于带Logo(如抖音Logo.电视台标)的视频,有三种方案进行Logo消除: 直接将对应区域用对应图像替换: 直接将对应区域模糊化: 通过变换将要 ...
- 关于个人项目(臻美MV【仿抖音App】)滑动切换视频的分析(前端角度)
我们知道你天天刷抖音的时候可以上滑切换视频,互不影响.那么我们站在前端的角度能否可以实现这种效果呢?这是我的个人项目:臻美MV 下面我是用Vue写的,现在我把它开源. Vue: 初始界面 <te ...
- 1、找出url汇总页,过滤出满足条件的详情页url;2、去详情页采集信息
1.找出url汇总页,过滤出满足条件的详情页url:2.去详情页采集信息 package main import ( "fmt" "github.com/gocolly/ ...
- 手机APP例如抖音,让 people‘s 注意力集中到了 社会进化的 优胜部分 (优胜劣汰,什么是优) + 真善美,的 “美” , 促进了2极分化, 会产生强者俞强,弱者越弱,确实促进了信息的流通,传播了有用的东东 产生了独特的价值 而 如何 能计算出这些价值呢, 需要 数学 金融 财务 货币 量化吗
手机APP例如抖音,让 people‘s 注意力集中到了 社会进化的 优胜部分 (优胜劣汰,什么是优) + 真善美,的 “美” , 促进了2极分化, 会产生 ...
- Python实现抖音关键词热度搜索小程序(附源码)
今天给大家带来一个抖音热词小程序,废话不多说,直接上代码 import requests import json import urllib.parse import time ''' python知 ...
随机推荐
- RFID实践——NET IoT程序读取高频RFID卡或者标签
这篇文章是一份RFID实践的保姆级教程,将详细介绍如何用 Raspberry Pi 连接 PN5180 模块,并开发 .NET IoT 程序读写ISO14443 和 ISO15693协议的卡/标签. ...
- Bean的原始版本与最终版本不一致?记一次Spring IOC探索之旅
前言 在这个信息技术发展迅速的时代,万万没想到,Spring自2003年发展至今,仍是技术选型中的首选,某些项目甚至有Spring全家桶的情况. 在Java开发者面试当中,Spring的原理也常被面试 ...
- Minecraft server.properties 参数含义 1.18.1,Java版
服务器搭建 参照: https://www.spigotmc.org/wiki/buildtools/#latest 参数含义 #Fri Feb 11 15:20:40 CST 2022 # 启用jm ...
- curl使用总结
1.请求源码 curl http://wttr.in/ 天气网站 2.文件下载 -o :保存文件 -s:禁用进度表 --progress-bar:让进度显示为进度条 -C - :断点连续下载 --l ...
- AWVS安装使用
AWVS安装使用 1.双击exe文件,然后点击下一步. 2.选择我接受,然后下一步. 3.选择路径(我选择的默认路径)然后下一步. 4.还是下一步. 5.设置邮箱,用户名密码,用户名12345678@ ...
- 错误修正记录: [Vivado 12-8300] Launch HLS failed! Please see vitis_hls.log for details.
起因 使用了Vivado Video Frame Buffer Read和Vivado Video Frame Buffer Write,按out of context模式综合失败.vivado版本2 ...
- mac ssh 密钥登陆远程服务器
第一步 创建ssh文件目录 打开终端 执行: mkdir ~/.ssh 第二步 将密钥对移到ssh目录下 mv ~/Downloads/MyKeyPair.pem ~/.ssh/MyKeyPair.p ...
- go 定时任务库 cron
简介 在Linux中,Cron是计划任务管理系统,通过crontab命令使任务在约定的时间执行已经计划好的工作,例如定时备份系统数据.周期性清理缓存.定时重启服务等. 本文介绍的cron库是一个用于管 ...
- 算法分析-回溯算法-求解N皇后问题
一.题目需求 n皇后问题是一道比较经典的算法题.它研究的是将n个皇后放置在一个n×n的棋盘上,使皇后彼此之间不相互攻击. 即任意两个皇后都不能处于同一行.同一列或同一斜线上. 二.算法思想 1.构建棋 ...
- AntennaMagus中文培训教程
AntennaMagus中文培训教程 链接:https://pan.baidu.com/s/1Svc613HvfUtIMB3uOXILkg 提取码:0s2c