Flink学习(十四) Flink 窗口、时间和水位线
Flink 框架中支持事件时间、摄入时间和处理时间三种。而当我们在流式计算环境中数据从 Source 产生,再到转换和输出,这个过程由于网络和反压的原因会导致消息乱序。因此,需要有一个机制来解决这个问题,这个特别的机制就是“水位线”。
Flink 的窗口和时间
根据窗口数据划分的不同,目前 Flink 支持如下 3 种:
滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
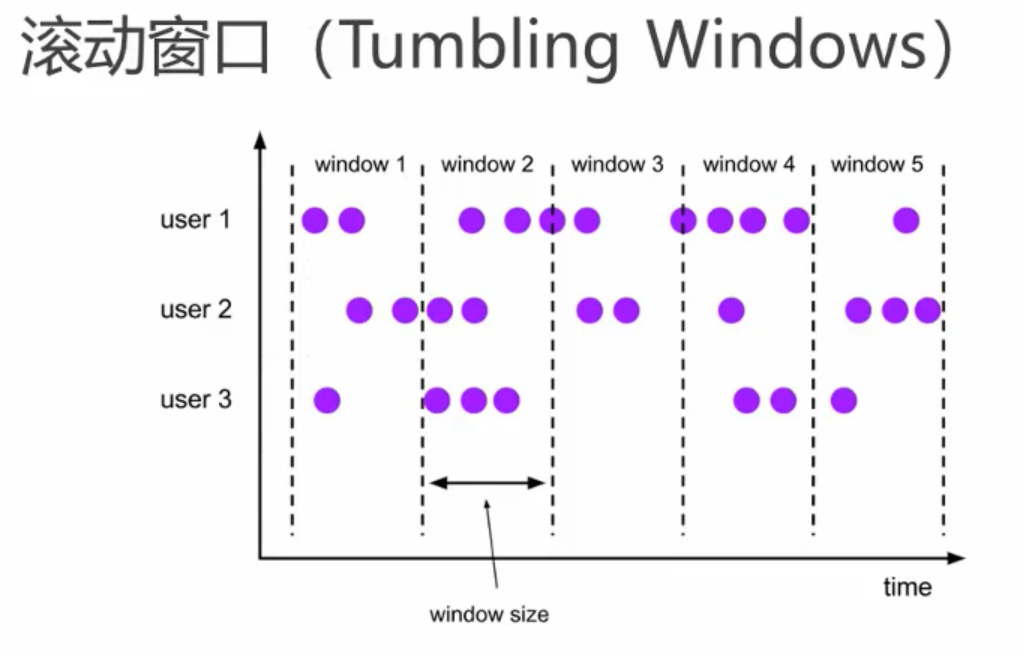
滑动窗口,窗口数据有固定的大小,并且有生成间隔;

会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加。


Flink 中的时间分为三种:
事件时间(Event Time),即事件实际发生的时间;
摄入时间(Ingestion Time),事件进入流处理框架的时间;
处理时间(Processing Time),事件被处理的时间。
下面的图详细说明了这三种时间的区别和联系:

事件时间(Event Time
事件时间(Event Time)指的是数据产生的时间,这个时间一般由数据生产方自身携带,比如 Kafka 消息,每个生成的消息中自带一个时间戳代表每条数据的产生时间。Event Time 从消息的产生就诞生了,不会改变,也是我们使用最频繁的时间。
利用 Event Time 需要指定如何生成事件时间的“水印”,并且一般和窗口配合使用,具体会在下面的“水印”内容中详细讲解。
我们可以在代码中指定 Flink 系统使用的时间类型为 EventTime:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置时间属性为 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props)); stream
.keyBy( (event) -> event.getUser() )
.timeWindow(Time.hours(1))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
Flink 注册 EventTime 是通过 InternalTimerServiceImpl.registerEventTimeTimer 来实现的
可以看到,该方法有两个入参:namespace 和 time,其中 time 是触发定时器的时间,namespace 则被构造成为一个 TimerHeapInternalTimer 对象,然后将其放入 KeyGroupedInternalPriorityQueue 队列中。
那么 Flink 什么时候会使用这些 timer 触发计算呢?答案在这个方法里:
InternalTimeServiceImpl.advanceWatermark。
public void advanceWatermark(long time) throws Exception {
currentWatermark = time; InternalTimer<K, N> timer; while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
eventTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onEventTime(timer);
}
}
这个方法中的 while 循环部分会从 eventTimeTimersQueue 中依次取出触发时间小于参数 time 的所有定时器,调用 triggerTarget.onEventTime() 方法进行触发。
这就是 EventTime 从注册到触发的流程。
处理时间(Processing Time)
处理时间(Processing Time)指的是数据被 Flink 框架处理时机器的系统时间,Processing Time 是 Flink 的时间系统中最简单的概念,但是这个时间存在一定的不确定性,比如消息到达处理节点延迟等影响。
我们同样可以在代码中指定 Flink 系统使用的时间为 Processing Time:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
同样,也可以在源码中找到 Flink 是如何注册和使用 Processing Time 的。

registerProcessingTimeTimer() 方法为我们展示了如何注册一个 ProcessingTime 定时器:
每当一个新的定时器被加入到 processingTimeTimersQueue 这个优先级队列中时,如果新来的 Timer 时间戳更小,那么更小的这个 Timer 会被重新注册 ScheduledThreadPoolExecutor 定时执行器上。
Processing Time 被触发是在 InternalTimeServiceImpl 的 onProcessingTime() 方法中:

一直循环获取时间小于入参 time 的所有定时器,并运行 triggerTarget 的 onProcessingTime() 方法。
摄入时间(Ingestion Time)
摄入时间(Ingestion Time)是事件进入 Flink 系统的时间,在 Flink 的 Source 中,每个事件会把当前时间作为时间戳,后续做窗口处理都会基于这个时间。理论上 Ingestion Time 处于 Event Time 和 Processing Time之间。
与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成 watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的 watermark。
可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。如果需要处理此类问题,建议使用 EventTime。
Ingestion Time 的时间类型生成相关的代码在 AutomaticWatermarkContext 中。
水位线(WaterMark)
水位线(WaterMark)是 Flink 框架中最晦涩难懂的概念之一,有很大一部分原因是因为翻译的原因。
WaterMark 在正常的英文翻译中是水位,但是在 Flink 框架中,翻译为“水位线”更为合理,它在本质上是一个时间戳。
在上面的时间类型中我们知道,Flink 中的时间:
EventTime 每条数据都携带时间戳;
ProcessingTime 数据不携带任何时间戳的信息;
IngestionTime 和 EventTime 类似,不同的是 Flink 会使用系统时间作为时间戳绑定到每条数据,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。
所以,我们在处理消息乱序的情况时,会用 EventTime 和 WaterMark 进行配合使用。
首先我们要明确几个基本问题。
水印的本质是什么
水印的出现是为了解决实时计算中的数据乱序问题,它的本质是 DataStream 中一个带有时间戳的元素。
如果 Flink 系统中出现了一个 WaterMark T,那么就意味着 EventTime < T 的数据都已经到达,窗口的结束时间和 T 相同的那个窗口被触发进行计算了。
也就是说:水印是 Flink 判断迟到数据的标准,同时也是窗口触发的标记。
在程序并行度大于 1 的情况下,会有多个流产生水印和窗口,这时候 Flink 会选取时间戳最小的水印。

水位线是如何生成的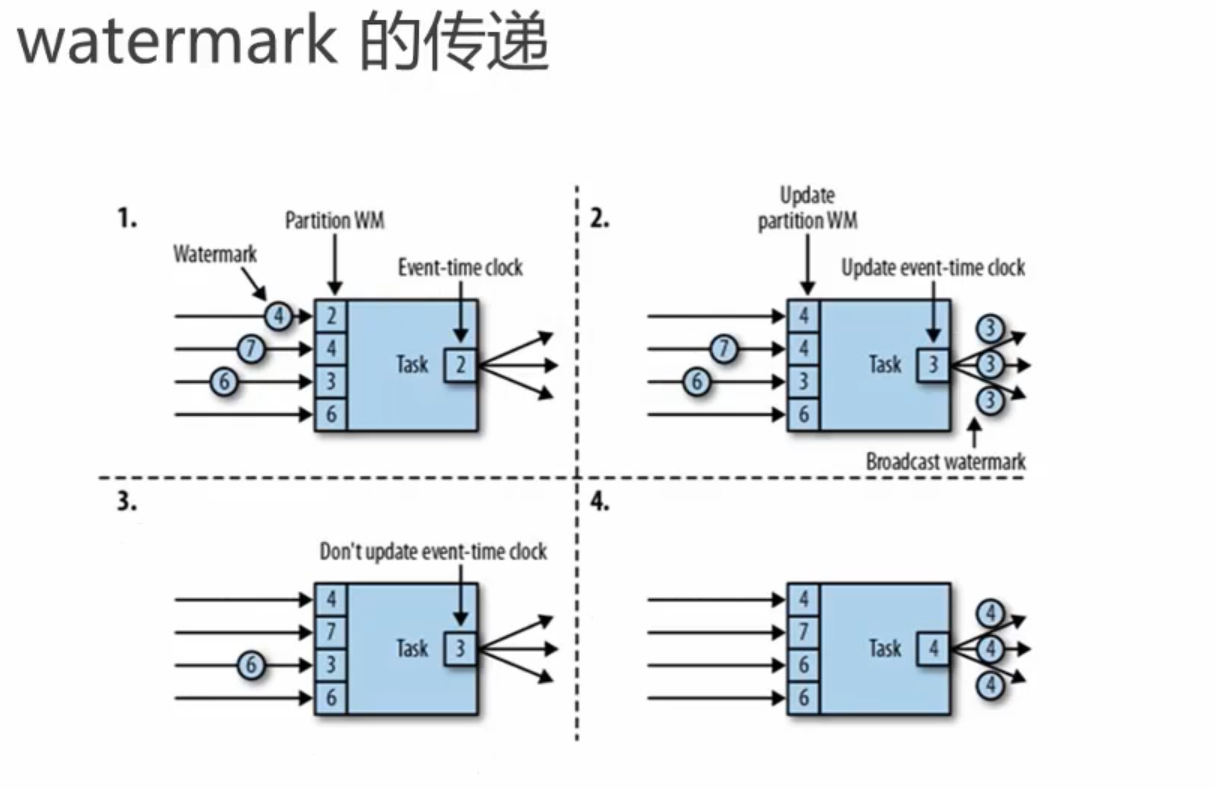
Flink 提供了 assignTimestampsAndWatermarks() 方法来实现水印的提取和指定,该方法接受的入参有 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 两种。
整体的类图如下:

水位线种类

周期性水位线
我们在使用 AssignerWithPeriodicWatermarks 周期生成水印时,周期默认的时间是 200ms,这个时间的指定位置为:
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
是否还记得上面我们在讲时间类型时会通过 env.setStreamTimeCharacteristic() 方法指定 Flink 系统的时间类型,这个 setStreamTimeCharacteristic() 方法中会做判断,如果用户传入的是 TimeCharacteristic.eventTime 类型,那么 AutoWatermarkInterval 的值则为 200ms ,如上述代码所示。当前我们也可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法来指定自动生成的时间间隔。
在上述的类图中可以看出,我们需要通过 TimestampAssigner 的 extractTimestamp() 方法来提取 EventTime。
Flink 在这里提供了 3 种提取 EventTime() 的方法,分别是:
AscendingTimestampExtractor
BoundedOutOfOrdernessTimestampExtractor
IngestionTimeExtractor
这三种方法中 BoundedOutOfOrdernessTimestampExtractor() 用的最多,需特别注意,在这个方法中的 maxOutOfOrderness 参数,该参数指的是允许数据乱序的时间范围。简单说,这种方式允许数据迟到 maxOutOfOrderness 这么长的时间。
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
public abstract long extractTimestamp(T element);
@Override
public final Watermark getCurrentWatermark() {
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
return timestamp;
}
PunctuatedWatermark 水位线
这种水位线的生成方式 Flink 没有提供内置实现,它适用于根据接收到的消息判断是否需要产生水位线的情况,用这种水印生成的方式并不多见。
举个简单的例子,假如我们发现接收到的数据 MyData 中以字符串 watermark 开头则产生一个水位线:
data.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<UserActionRecord>() {
@Override
public Watermark checkAndGetNextWatermark(MyData data, long l) {
return data.getRecord.startsWith("watermark") ? new Watermark(l) : null;
}
@Override
public long extractTimestamp(MyData data, long l) {
return data.getTimestamp();
}
});
class MyData{
private String record;
private Long timestamp;
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
public Timestamp getTimestamp() {
return timestamp;
}
public void setTimestamp(Timestamp timestamp) {
this.timestamp = timestamp;
}
}
案例
我们上面讲解了 Flink 关于水位线和时间的生成,以及使用,下面举一个例子来讲解。
模拟一个实时接收 Socket 的 DataStream 程序,代码中使用 AssignerWithPeriodicWatermarks 来设置水位线,将接收到的数据进行转换,分组并且在一个10
秒,间隔是5秒的滑动窗口内获取该窗口中第二个元素最小的那条数据。
package com.wyh.windowsApi import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.functions.{AssignerWithPeriodicWatermarks, AssignerWithPunctuatedWatermarks}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time object WindowTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//周期性生成watermark 默认是200毫秒
env.getConfig.setAutoWatermarkInterval(100L) /**
* 从文件中读取数据
*
*
*/
//val stream = env.readTextFile("F:\\flink-study\\wyhFlinkSD\\data\\sensor.txt") val stream = env.socketTextStream("localhost", 7777) //Transform操作
val dataStream: DataStream[SensorReading] = stream.map(data => {
val dataArray = data.split(",")
SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble)
})
//===到来的数据是升序的,准时发车,用assignAscendingTimestamps
//指定哪个字段是时间戳 需要的是毫秒 * 1000
// .assignAscendingTimestamps(_.timestamp * 1000)
//===处理乱序数据
// .assignTimestampsAndWatermarks(new MyAssignerPeriodic())
//==底层也是周期性生成的一个方法 处理乱序数据 延迟1秒种生成水位 同时分配水位和时间戳 括号里传的是等待延迟的时间
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
override def extractTimestamp(t: SensorReading): Long = {
t.timestamp * 1000
}
}) //统计10秒内的最小温度
val minTemPerWindowStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(0)
// .timeWindow(Time.seconds(10)) //开时间窗口 滚动窗口 没有数据的窗口不会触发
//左闭右开 包含开始 不包含结束 延迟1秒触发的那个时间的数据不包含
//可以直接调用底层方法,第三个参数传offset代表时区
//.window(SlidingEventTimeWindows.of(Time.seconds(15),Time.seconds(5),Time.hours(-8)))
.timeWindow(Time.seconds(15), Time.seconds(5)) //滑动窗口,每隔5秒输出一次
.reduce((data1, data2) => (data1._1, data1._2.min(data2._2))) //用reduce做增量聚合 minTemPerWindowStream.print("min temp") dataStream.print("input data") env.execute("window Test") } } //设置水位线(水印) 这里有两种方式实现
//一种是周期性生成 一种是以数据的某种特性进行生成水位线(水印)
/**
* 周期性生成watermark 默认200毫秒
*/
class MyAssignerPeriodic() extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound: Long = 60 * 1000
var maxTs: Long = Long.MaxValue override def getCurrentWatermark: Watermark = {
//定义一个规则进行生成
new Watermark(maxTs - bound)
} //用什么抽取这个时间戳
override def extractTimestamp(t: SensorReading, l: Long): Long = {
//保存当前最大的时间戳
maxTs = maxTs.max(t.timestamp)
t.timestamp * 1000
}
} /**
* 乱序生成watermark
* 每来一条数据就生成一个watermark
*/
class MyAssignerPunctuated() extends AssignerWithPunctuatedWatermarks[SensorReading] {
override def checkAndGetNextWatermark(t: SensorReading, l: Long): Watermark = {
new Watermark(l)
} override def extractTimestamp(t: SensorReading, l: Long): Long = {
t.timestamp * 1000
}
}
Flink学习(十四) Flink 窗口、时间和水位线的更多相关文章
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- Scala学习十四——模式匹配和样例类
一.本章要点 match表达式是更好的switch,不会有意外调入下一个分支 如果没有模式能够匹配,会抛出MatchError,可以用case _模式避免 模式可以包含一个随意定义的条件,称做守卫 你 ...
- JavaWeb学习 (十四)————JSP基础语法
一.JSP模版元素 JSP页面中的HTML内容称之为JSP模版元素. JSP模版元素定义了网页的基本骨架,即定义了页面的结构和外观. 二.JSP表达式 JSP脚本表达式(expression)用于将 ...
- spring boot 学习(十四)SpringBoot+Redis+SpringSession缓存之实战
SpringBoot + Redis +SpringSession 缓存之实战 前言 前几天,从师兄那儿了解到EhCache是进程内的缓存框架,虽然它已经提供了集群环境下的缓存同步策略,这种同步仍然需 ...
- android学习十四(android的接收短信)
收发短信是每一个手机主要的操作,android手机当然也能够接收短信了. android系统提供了一系列的API,使得我们能够在自己的应用程序里接收和发送短信. 事实上接收短信主要是利用我们前面学过的 ...
- Java学习十四
学习内容: 1.Junit 2.maven安装配置环境 一.Junit实例演示步骤 1.引入jar包 junit包需要引入hamcrest-core包,否则会报错 2.测试如下代码 package c ...
- Java开发学习(十四)----Spring整合Mybatis及Junit
一.Spring整合Mybatis思路分析 1.1 环境准备 步骤1:准备数据库表 Mybatis是来操作数据库表,所以先创建一个数据库及表 create database spring_db cha ...
随机推荐
- Fleck:一个轻量级的C#开源WebSocket服务端库
推荐一个简单易用.轻量级的C#开源WebSocket服务端库,方便我们快速实现WebSocket的开发. 01 项目简介 Fleck 是一个用 C# 编写的轻量级 WebSocket 服务器库.它提供 ...
- Python 和 Podman
1. Windows 10 上安装 Python 开始在 Windows 上使用 Python(初学者) 2. 使用 pip Python 的 Microsoft Store 安装包括 pip(标准包 ...
- Qt/C++音视频开发62-电子放大/按下选择区域放大显示/任意选取区域放大
一.前言 电子放大这个功能思考了很久,也是一直拖到近期才静下心来完整这个小功能,这个功能的前提,主要得益于之前把滤镜打通了,玩出花样来了,只要传入对应的滤镜字符串,就可以实现各种各样的效果,然后查阅滤 ...
- Qt编写可视化大屏电子看板系统22-平滑曲线图
一.前言 平滑曲线是所有涉及到曲线图的项目中,绕不开的一个话题,尽管很多人爱看折线图,但是很多时候来个平滑曲线图,会更加赏心悦目,这就好比现在的手机app移动客户端上,从最初的四方四正到现在的平滑圆角 ...
- 对CGAL5.0及以后版本编译的说明
CGAL5.0及以后版本只有头文件,没有库文件了.这意味着CGAL无需编译,只需安装好CGAL的依赖项即可.类似Eigen库.
- 即时通讯技术文集(第16期):IM架构设计技术精选(第一部分) [共17篇]
为了更好地分类阅读总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第16 期. [- 1 -] 浅谈IM系统的架构设计 [链接] http://www.52im.net/thread ...
- pytorch模型降低计算成本和计算量
下面是如何使用PyTorch降低计算成本和计算量的一些方法: 压缩模型:使用模型压缩技术,如剪枝.量化和哈希等方法,来减小模型的大小和复杂度,从而降低计算量和运行成本. 分布式训练:使用多台机器进行分 ...
- C# AIModelRouter:使用不同的AI模型完成不同的任务
AIModelRouter AI模型路由,模型的能力有大小之分,有些简单任务,能力小一点的模型也能很好地完成,而有些比较难的或者希望模型做得更好的,则可以选择能力强的模型.为什么要这样做呢?可以降低A ...
- 用于决策的世界模型 -- 论文 World Models (2018) & PlaNet (2019) 讲解
参考资料: [2411.14499] Understanding World or Predicting Future? A Comprehensive Survey of World Models ...
- 分布式全局唯一ID解决方案详解
--------------------- ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Inn ...