kafka+storm 单机运行
环境:
1、kafka+zookeeper
2、window平台
3、eclipse
设置:
1、kafka和zookeeper安装,另一篇有介绍(https://www.cnblogs.com/51python/p/10870258.html)
2、eclipse代码(建立maven工程)
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>hadoop</groupId>
<artifactId>eclipseandmaven</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>eclipseandmaven</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies> <dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.1</version>
<!-- 本地测试注释集群运行打开 -->
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
主函数
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.TopologyBuilder; public class MainTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
KafkaSpoutConfig.Builder<String, String> kafkaBuilder = KafkaSpoutConfig.builder("127.0.0.1:9092", "test0811");
// .builder("127.0.0.1:9092,node-2:9092,node-3:9092", "test0811");
// 设置kafka属于哪个组
kafkaBuilder.setGroupId("testgroup");
// 创建kafkaspoutConfig
KafkaSpoutConfig<String, String> build = kafkaBuilder.build();
// 通过kafkaspoutConfig获得kafkaspout
KafkaSpout<String, String> kafkaSpout = new KafkaSpout<String, String>(build);
// 设置5个线程接收数据
builder.setSpout("kafkaSpout", kafkaSpout, 5);
// 设置2个线程处理数据
builder.setBolt("printBolt", new PrintBolt(), 2).localOrShuffleGrouping("kafkaSpout");
Config config = new Config();
if (args.length > 0) {
// 集群提交模式
config.setDebug(false);
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
// 本地测试模式
config.setDebug(true);
// 设置2个进程
config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("kafkaSpout", config, builder.createTopology());
}
}
}
storm输出
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple; public class PrintBolt extends BaseBasicBolt {
/**
* execute会被storm一直调用
*
* @param tuple
* @param basicOutputCollector
*/
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
// 为了便于查看消息用err标红
System.err.println(tuple.getValue(4));
System.err.println(tuple.getValues());
} public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { }
}
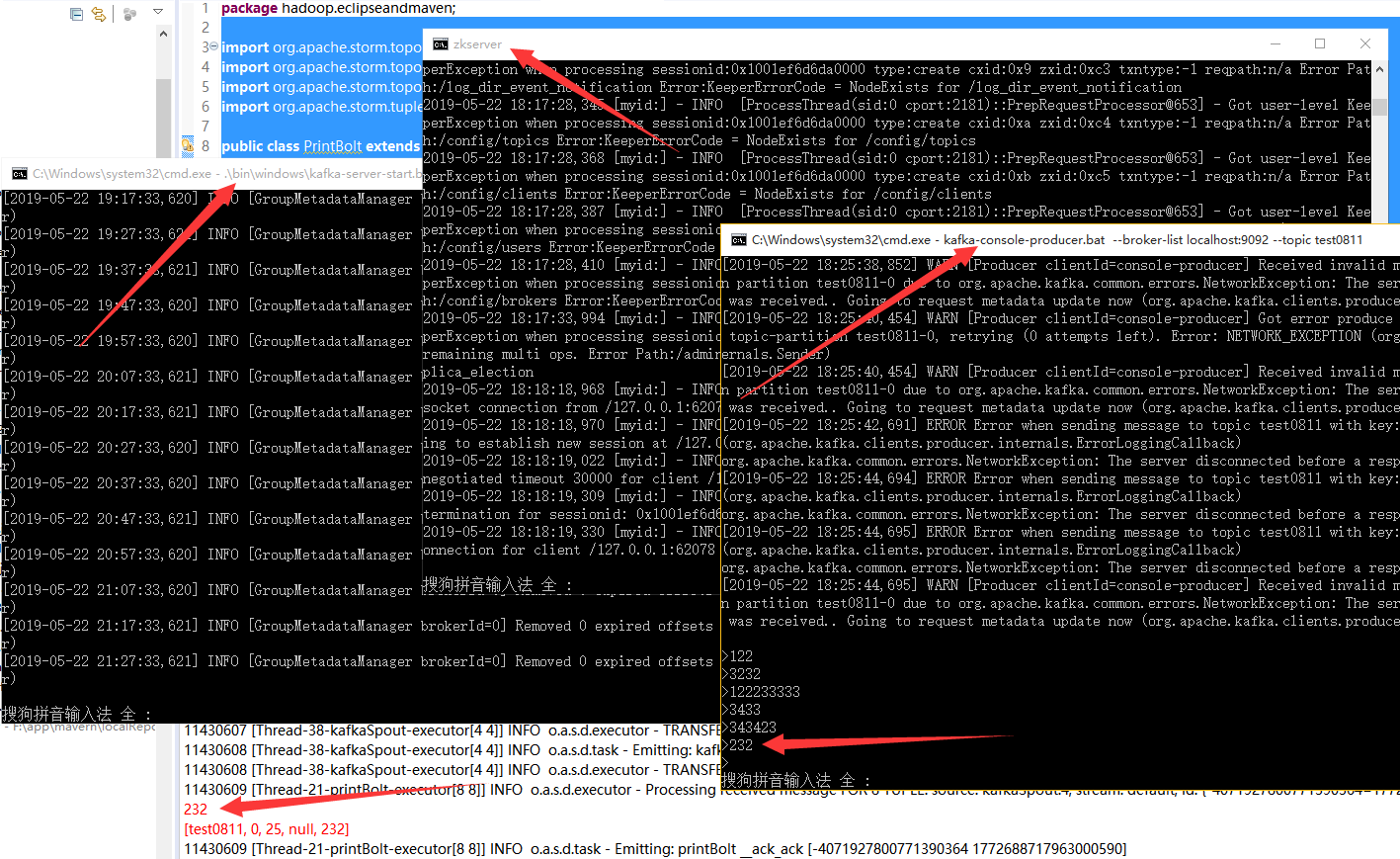
3、运行
1)启动zookeeper
zkserver
2)启动kafka服务(在D:\bigdata\kafka_2.11-0.9.0.1安装目录打开cmd)
.\bin\windows\kafka-server-start.bat .\config\server.properties
3)创建主题(在D:\bigdata\kafka_2.11-0.9.0.1\bin\windows安装目录打开cmd)
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test0811
4)创建生产者(在D:\bigdata\kafka_2.11-0.9.0.1\bin\windows安装目录打开cmd)
kafka-console-producer.bat --broker-list localhost:9092 --topic test0811
5)启动主函数
运行eclipse主函数
结果:
在4中的cmd窗口输入字符串,会在eclipse中收到。
这是单机版,后面会做多机通信,敬请期待!
参考:https://blog.csdn.net/qq_41455420/article/details/79385566
kafka+storm 单机运行的更多相关文章
- storm单机运行与集群运行问题
使用trident接口时,storm读取kafka数据会将kafka消费记录保存起来,将消费记录的位置保存在tridentTopology.newStream()的第一个参数里, 如果设置成从头开始消 ...
- storm单机运行报错 ERROR backtype.storm.daemon.executor -
单机本地运行storm报错: 错误如下: java.lang.NullPointerException: null at test2.Spot2.nextTuple(Spot2.java:) ~[cl ...
- flume+kafka+storm单机部署
flume-1.6.0 kafka0.9.0.0 storm0.9.6 一.部署flume 1.解压 tar -xzvf apache-flume-1.6.0-bin.tar.gz -C ../app ...
- 简单测试flume+kafka+storm的集成
集成 Flume/kafka/storm 是为了收集日志文件而引入的方法,最终将日志转到storm中进行分析.storm的分析方法见后面文章,这里只讨论集成方法. 以下为具体步骤及测试方法: 1.分别 ...
- storm单机环境部署
前面说过storm集群的部署,这篇主要介绍storm单机环境部署,其实他们之间很类似,就是将之前配置文件中所有的集群条目改成本机的地址即可,部署之前应该按前面solr和zookeeper单机环境部署那 ...
- Kafka+Storm+HDFS整合实践
在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统计分析,但是对于实时的需求Hive就不合适了.实时应用场景可以使用Storm,它是一 ...
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- Zookeeper+Kafka+Storm+HDFS实践
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Hadoop一般用在离线的分析计算中,而storm区别于hadoop,用在实时的流式计算中,被广泛用来 ...
- [转载] Kafka+Storm+HDFS整合实践
转载自http://www.tuicool.com/articles/NzyqAn 在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统 ...
随机推荐
- Android开发笔记(12)——ListView & Adapter
转载请注明:http://www.cnblogs.com/igoslly/p/6947225.html 下一章是关于ListFragment的内容,首先先介绍ListView的相关配置,理解ListF ...
- MatLab之Simulink之simple model
Use Simulink to model a system and then simulate the dynamic behavior of that system. 1 Open in Comm ...
- 图像局部显著性—点特征(Fast)
fast作为几乎最快的角点检测算法,一般说明不附带描述子.参考综述:图像的显著性检测--点特征 详细内容,请拜访原=文章:Fast特征点检测算法 在局部特征点检测快速发展的时候,人们对于特征的认识也越 ...
- 使用CImage类 显示图片
在不适用openCv的一种时候,使用CImage显示图片数据,并且直接嵌入DC框中. 使用CImage 在pic控件里显示图片 void CMyCalLawsDlg::MyShowImage( CIm ...
- 原来这才是Kafka的“真面目”
作者介绍 郑杰文,腾讯云存储,高级后台工程师,2014 年毕业加入腾讯,先后从事增值业务开发.腾讯云存储开发.对业务性.技术平台型后台架构设计都有深入的探索实践.对架构的海量并发.高可用.可扩展性都有 ...
- eslint 校验去除
不允许对 function 的参数进行重新赋值 /* eslint no-param-reassign: ["error", { "props": false ...
- Python检测删除你的好友-wxpy模块(发送特殊字符式)
下面是代码: from wxpy import *import timeprint("本软件采用特殊字符检测,即对方收不到任何信息!")print("或许某个版本微信就会 ...
- 【codeforces 483B】Friends and Presents
[链接] 我是链接,点我呀:) [题意] [题解] 我们可以二分n的值,设为mid 那么对于n=mid 我们可以算出来以下3个东西 temp1 = n/x; temp2 = n/y; temp3 = ...
- mybatis传入两个String类型的参数
1.项目spring +mybatis +oracle 2.报错信息: [DEBUG] -- :: org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debu ...
- C语言——定义&&声明
1.变量的定义&声明 变量的声明有两种情况: <1>一种是需要建立存储空间的.例如:int a 在声明的时候就已经建立了存储空间. <2>另一种是不需要建立存储空间的. ...