使用spark 计算netflow数据初探
spark是一个高性能的并发的计算平台,而netflow是一种一般来说数量级很大的数据。本文记录初步使用spark 计算netflow数据的大致过程。
本文包括以下过程:
1. spark环境的搭建
2. netflow数据的生成与处理
3. 通过spark 计算netflow数据
spark环境的搭建
spark环境的搭建主要分2部分。
- hadoop的环境的搭建
- spark的安装
hadoop的安装
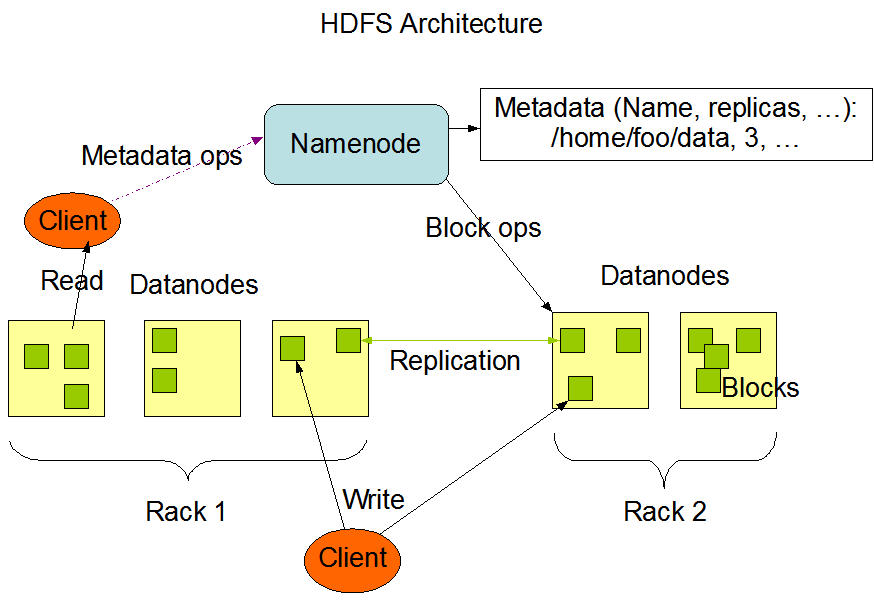
hadoop的安装包括,hdfs的安装和yarn的安装。 读本部分之前要先去查阅hdfs和yarn的概念。hdfs是hadoop的分布式文件系统。hdfs的架构为master/slave架构。cluster中有一个唯一的NameNode(master节点),剩下的节点为DataNodes(slave 节点),通常有多个。 hdfs把文件分成多个block,这些block存储在不同的DataNode上。NameNode负责执行对文件进行open,close,rename file&&directory 操作,也负责维护block和DataNode之间的map关系。DataNode则负责block级别 create delete read replication 等操作。 整个架构如下图所示:
YARN全称是yet another resource manager。 由于hadoop是一个分布式的架构,所以需要一个统一的资源管理器来调度分配各种资源。
spark的安装
如下
netflow数据的生成与处理
netflow是路由器设备在激活了netflow feature后生产的一些统计数据,这些数据会发给收集器如pmacct。 数据转换成csv格式大概如下:
TAG,IN_IFACE,OUT_IFACE,SRC_IP,DST_IP,SRC_PORT,DST_PORT,PROTOCOL,ip_dscp,flow_direction,PACKETS,BYTES
,,,42.120.83.100,42.120.85.157,,,ipv6-crypt,,,,
,,,42.120.83.246,42.120.87.145,,,ospf,,,,
,,,42.120.87.154,42.120.86.250,,,ipv6-auth,,,,
具体请了解netflow。
这里说的处理是指做两件事:
1. 去掉第一行的TAG
2. 加入 timestamp 列
3. 把文件放入HDFS
通过spark 计算netflow数据
这里用spark计算我们需要的数据。
使用spark 计算netflow数据初探的更多相关文章
- Spark及其应用场景初探
最近老大让用Spark做一个ETL项目,搭建了一套只有三个结点Standalone模式的Spark集群做测试,基础数据量大概8000W左右.看了官方文档,Spark确实在Map-Reduce上提升了很 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- Spark计算模型
[TOC] Spark计算模型 Spark程序模型 一个经典的示例模型 SparkContext中的textFile函数从HDFS读取日志文件,输出变量file var file = sc.textF ...
- [转载] Spark:大数据的“电光石火”
转载自http://www.csdn.net/article/2013-07-08/2816149 Spark已正式申请加入Apache孵化器,从灵机一闪的实验室“电火花”成长为大数据技术平台中异军突 ...
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- 【Spark深入学习 -13】Spark计算引擎剖析
----本节内容------- 1.遗留问题解答 2.Spark核心概念 2.1 RDD及RDD操作 2.2 Transformation和Action 2.3 Spark程序架构 2.4 Spark ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Spark计算模型RDD
RDD弹性分布式数据集 RDD概述 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
随机推荐
- Winform窗体验证登陆
用户名,密码尽量不要在BLL,UIL判断,尽可能的在储存过程判断,通过返回的值不同,进行判断,这样提高安全性SQL Server储存过程代码: BEGINif(exists ( select User ...
- cksum - 一个文件的检查和以及字节数
SYNOPSIS(总览) ../src/cksum [OPTION]... [FILE]... DESCRIPTION(描述) 输出CRC(循环冗余校验码)检查和以及每个FILE的字节数. --hel ...
- dom监听事件class
layui.use(['layer', 'form'], function(){ var layer = layui.layer ,form = layui.form; var $ = layui.j ...
- Adobe Dreamweaver CC 2014 代码颜色目录 dw
他的颜色代码配置文件,不在安装目录下,这让我好找啊~ C:\Users\Administrator\AppData\Roaming\Adobe\Dreamweaver CC 2014\zh_CN\Co ...
- C# 如何发送Http请求
HttpSender是一个用于发送Http消息的轻量C#库,使用非常简单,只需要一两行代码,就能完成Http请求的发送 使用 Nuget,搜索 HttpSender 就能找到这个库 这个库的命名空间是 ...
- R-FCN:Object Detection via Region-based Fully Convolutional Networks
fast.faster这些网络都可以被roi-pooling层分成两个子网络:1.a shared,'fully convolutional' subnetwork 2.an roi-wise sub ...
- (独孤九剑)--PHP简介与现况
(1)为什么学习PHP? 1.好就业: 2.入门简单,学习周期短,两个月即可: 3.学习编程思路,使编程习惯更加规范: 4.大公司直招: 5.处理大并发数据: 6.开源,所以更加安全 (2)PHP是什 ...
- 编程规范:allocator
一.作用 标准库allocator类定义在头文件memory中,它帮助我们将内存分配和对象构造分离开来 allocator<T> a //定义一个名为a的allocator对象,它可以为类 ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
- 显微镜下的webpack4入门
前端的构建打包工具很多,比如grunt,gulp.相信这两者大家应该是耳熟能详的,上手相对简单,而且所需手敲的代码都是比较简单的.然后webpack的出现,让这两者打包工具都有点失宠了.webpack ...