使用spark 计算netflow数据初探
spark是一个高性能的并发的计算平台,而netflow是一种一般来说数量级很大的数据。本文记录初步使用spark 计算netflow数据的大致过程。
本文包括以下过程:
1. spark环境的搭建
2. netflow数据的生成与处理
3. 通过spark 计算netflow数据
spark环境的搭建
spark环境的搭建主要分2部分。
- hadoop的环境的搭建
- spark的安装
hadoop的安装
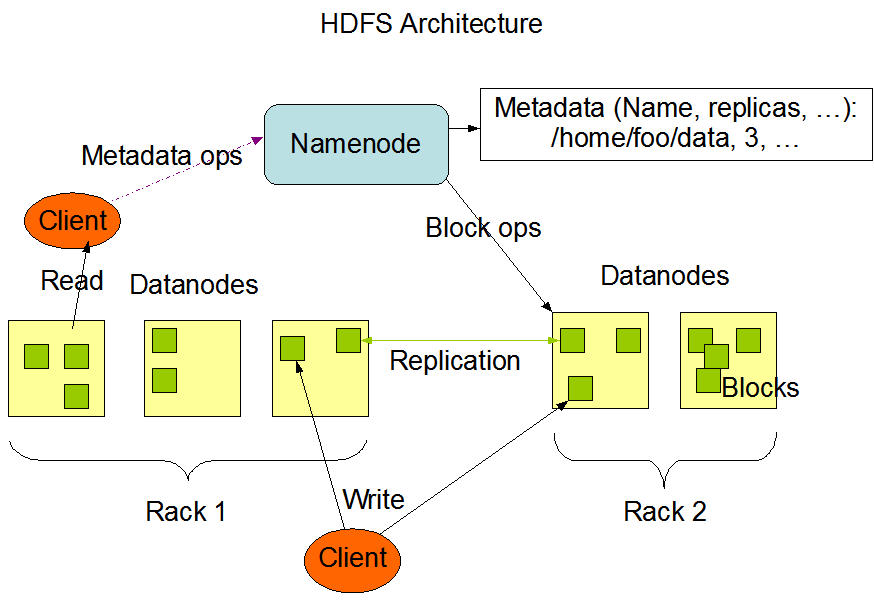
hadoop的安装包括,hdfs的安装和yarn的安装。 读本部分之前要先去查阅hdfs和yarn的概念。hdfs是hadoop的分布式文件系统。hdfs的架构为master/slave架构。cluster中有一个唯一的NameNode(master节点),剩下的节点为DataNodes(slave 节点),通常有多个。 hdfs把文件分成多个block,这些block存储在不同的DataNode上。NameNode负责执行对文件进行open,close,rename file&&directory 操作,也负责维护block和DataNode之间的map关系。DataNode则负责block级别 create delete read replication 等操作。 整个架构如下图所示:
YARN全称是yet another resource manager。 由于hadoop是一个分布式的架构,所以需要一个统一的资源管理器来调度分配各种资源。
spark的安装
如下
netflow数据的生成与处理
netflow是路由器设备在激活了netflow feature后生产的一些统计数据,这些数据会发给收集器如pmacct。 数据转换成csv格式大概如下:
TAG,IN_IFACE,OUT_IFACE,SRC_IP,DST_IP,SRC_PORT,DST_PORT,PROTOCOL,ip_dscp,flow_direction,PACKETS,BYTES
,,,42.120.83.100,42.120.85.157,,,ipv6-crypt,,,,
,,,42.120.83.246,42.120.87.145,,,ospf,,,,
,,,42.120.87.154,42.120.86.250,,,ipv6-auth,,,,
具体请了解netflow。
这里说的处理是指做两件事:
1. 去掉第一行的TAG
2. 加入 timestamp 列
3. 把文件放入HDFS
通过spark 计算netflow数据
这里用spark计算我们需要的数据。
使用spark 计算netflow数据初探的更多相关文章
- Spark及其应用场景初探
最近老大让用Spark做一个ETL项目,搭建了一套只有三个结点Standalone模式的Spark集群做测试,基础数据量大概8000W左右.看了官方文档,Spark确实在Map-Reduce上提升了很 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- Spark计算模型
[TOC] Spark计算模型 Spark程序模型 一个经典的示例模型 SparkContext中的textFile函数从HDFS读取日志文件,输出变量file var file = sc.textF ...
- [转载] Spark:大数据的“电光石火”
转载自http://www.csdn.net/article/2013-07-08/2816149 Spark已正式申请加入Apache孵化器,从灵机一闪的实验室“电火花”成长为大数据技术平台中异军突 ...
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- 【Spark深入学习 -13】Spark计算引擎剖析
----本节内容------- 1.遗留问题解答 2.Spark核心概念 2.1 RDD及RDD操作 2.2 Transformation和Action 2.3 Spark程序架构 2.4 Spark ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Spark计算模型RDD
RDD弹性分布式数据集 RDD概述 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
随机推荐
- fatal: Authentication failed for 问题解决
执行以下code git config --system --unset credential.helper 参考地址: https://www.jianshu.com/p/8a7f257e07b8
- js中cookie的操作
JavaScript中的另一个机制:cookie,则可以达到真正全局变量的要求. cookie是浏览器 提供的一种机制,它将document 对象的cookie属性提供给JavaScript.可以由J ...
- postgresql update from
1,update from 关联表的更新 update table a set name=b.name from table B b where a.id=b.id; update test ...
- ES6扩展运算符的使用
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- RequireJS 上手使用
首先 点击此处 得到requirejs. 捣鼓了俩小时终于运行成功了,原因是因为require(['我是空格underscore',...],function(){...})的时候 变量多个空格(坑爹 ...
- 函数式编程:上线文、包裹、容器-我们可以将一个值用Context(上下文)包裹起来
Functor,即函子,是 Haskell 中普遍存在的.最基本的类型类.你可以用以下两种方式来理解 Functor: 它代表某种容器,该容器能够将某一函数应用到其每一个元素上. 它代表某种“可计算上 ...
- swift potocol 作为参量时函数的派发顺序
1.检查protocol本体是否声明调用函数: 2.如果没有,检查protocol扩展是否有该函数:如果扩展中也没有,报错: 3.如果本体声明了函数,使用动态派发机制进行派发:扩展中的实现位于最末位.
- 递归删除N天前的文件夹及子文件夹下的特定文件
@echo offrem 设置被删除文件夹路径set SrcDir=D:\tmp\test\rem 设置文件保存天数set Days=2rem /p指定搜索文件的路径 /s 在子目录中搜索 /m 指定 ...
- JFinal项目eclipse出现the table mapping of model: com.gexin.model.scenic.Scenic not exists or the ActiveRecordPlugin not start.
JFinal项目eclipse出现the table mapping of model: com.gexin.model.scenic.Scenic not exists or the ActiveR ...
- ZOJ - 3204 Connect them 最小生成树
Connect them ZOJ - 3204 You have n computers numbered from 1 to n and you want to connect them to ma ...