掌握Spark机器学习库-09.3-kmeans算法实现分类
数据集
iris.data
数据集概览
代码
package org.apache.spark.examples.hust.hml.examplesforml
import org.apache.spark.ml.clustering.{KMeans, LDA}
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.SparkSession
import scala.util.Random
object kmeans1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("iris")
val spark = SparkSession.builder().config(conf).getOrCreate()
val file = spark.read.format("csv").load("D:\\9-1kmeans\\iris.data")
file.show()
import spark.implicits._
val random = new Random()
val data = file.map(row => {
val label = row.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
}
(row.getString(0).toDouble,
row.getString(1).toDouble,
row.getString(2).toDouble,
row.getString(3).toDouble,
label,
random.nextDouble())
}).toDF("_c0", "_c1", "_c2", "_c3", "label", "rand").sort("rand")
val assembler = new VectorAssembler()
.setInputCols(Array("_c0", "_c1", "_c2", "_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val Array(train, test) = dataset.randomSplit(Array(0.8, 0.2))
train.show()
val kmeans = new KMeans().setFeaturesCol("features").setK(3).setMaxIter(20)
val model = kmeans.fit(train)
model.transform(train).show()
}
}
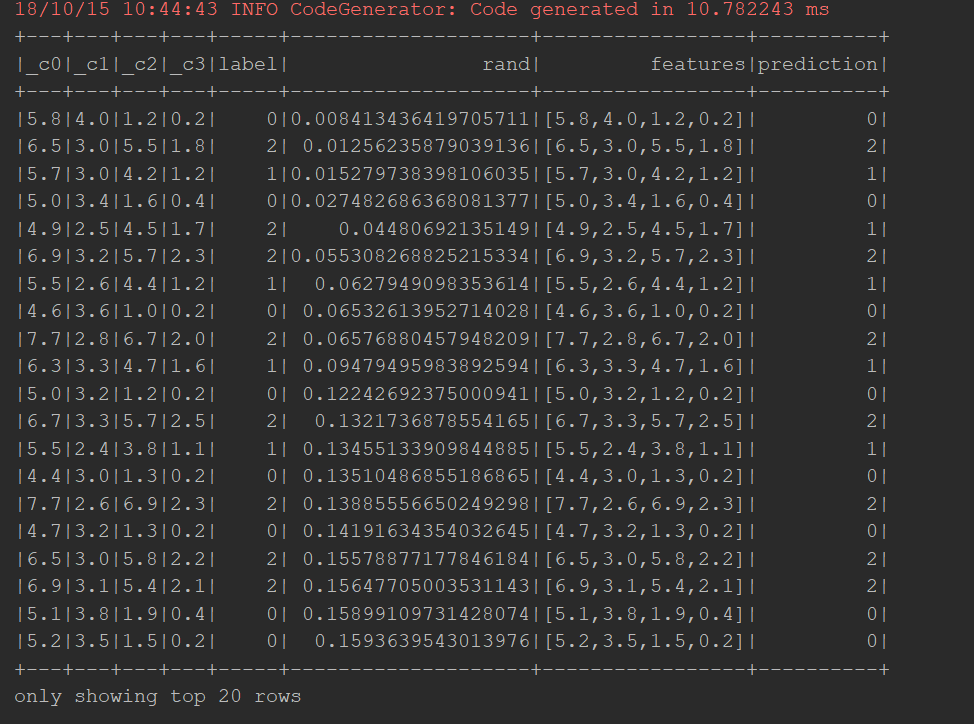
输出结果
掌握Spark机器学习库-09.3-kmeans算法实现分类的更多相关文章
- 掌握Spark机器学习库-09.6-LDA算法
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-07-线性回归算法概述
1)简介 自变量,因变量,线性关系,相关系数,一元线性关系,多元线性关系(平面,超平面) 2)使用线性回归算法的前提 3)应用例子 沸点与气压 浮力与表面积
- 掌握Spark机器学习库-08.7-决策树算法实现分类
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.Spark ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- UCI机器学习库和一些相关算法(转载)
UCI机器学习库和一些相关算法 各种机器学习任务的顶级结果(论文)汇总 https://github.com//RedditSota/state-of-the-art-result-for-machi ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 掌握Spark机器学习库-07.14-保序回归算法实现房价预测
数据集 house.csv 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-08.2-朴素贝叶斯算法
数据集 iris.data 数据集概览 代码 import org.apache.spark.SparkConf import org.apache.spark.ml.classification.{ ...
- 掌握Spark机器学习库-07-回归算法原理
1)机器学习模型理解 统计学习,神经网络 2)预测结果的衡量 代价函数(cost function).损失函数(loss function) 3)线性回归是监督学习
随机推荐
- PS人物脸部去高光简单之法
案例素材图: 方法原理步骤:得到高光面的选区,然后吸取高光面附近的颜色填充上去,这样就达到了去高光的效果. 得到高光选区的方法有很多种,要提取这种选区,通过阿尔法通道是最合适不过的了,本案例就通过阿尔 ...
- Apache Flink 1.5.0 Release Announcement
Apache Flink: Apache Flink 1.5.0 Release Announcement https://flink.apache.org/news/2018/05/25/relea ...
- 基于struts环境下的jquery easyui环境搭建
下载地址: http://download.csdn.net/detail/cyberzhaohy/7348451 加入了json包:jackson-all-1.8.5.jar,项目结构例如以下: 測 ...
- CRM 配置 ADFS后,使用自定义STS遇到的问题总结
1 登录ADFS服务查看 ADFS日志 2 根据日志提示的错误,设置ADFS对应的属性 (Get-ADFSRelyingPartyTrust) | Set-ADFSRelyingPartyTrust ...
- +Java中的native关键字浅析(Java+Native+Interface)++
JNI是Java Native Interface的 缩写.从Java 1.1开始,Java Native Interface (JNI)标准成为java平台的一部分,它允许Java代码和其他语言写的 ...
- bzoj1833: [ZJOI2010]count 数字计数&&USACO37 Cow Queueing 数数的梦(数位DP)
难受啊,怎么又遇到我不会的题了(捂脸) 如题,这是一道数位DP,随便找了个博客居然就是我们大YZ的……果然nb,然后就是改改模版++注释就好的了,直接看注释吧,就是用1~B - 1~A-1而已,枚举全 ...
- YTU 2975: 我的编号
2975: 我的编号 时间限制: 1 Sec 内存限制: 128 MB 提交: 42 解决: 15 题目描述 建立一个学生链表,每个链表结点含有学生的基本信息,编号和姓名.现在n个学生站成一列,根 ...
- RabbitMQ简述
官网教程 RabbitMQ是流行的开源消息队列系统,用erlang语言开发.RabbitMQ是AMQP(高级消息队列协议)的标准实现.支持多种客户端,如:Python.Ruby..NET.Java.J ...
- Ubuntu18开启redis服务自启动
设置redis服务开机自启动. 1.创建配置文件夹 sudo mkdir /etc/redis sudo cp /usr/local/redis/redis.conf /etc/redis sudo ...
- 服务器mysql授权连接用户
以下是创建到写入到删除,到drop的全部的过程: //1:创建数据库 create database it1110; //2:进入这个数据库 Use it1110; //3:创建一个数据表 Creat ...