kafka+spark-streaming实时推荐系统性能优化笔记
2) --conf spark.streaming.concurrentJobs=10
someDF.repartition(sparkSession.sparkContext.getConf.getInt("spark.executor.instances", 10)).foreachPartition {
p =>
bcVariables.value.get("_")
}
5)去掉所有不必要的join
join确实有很多可以优化的配置,但是没必要把时间花在join的优化上,尤其是在可以用广播变量来作为代替方案的情况下。
需要注意的是,广播变量和broadcast join是不一样的,前者效率在大部分时候要更高。
6)kafka partition个数和executor个数的关系
executor个数要能被partition个数整除。例如,如果partition个数为24个,那么12个executor和18个executor处理数据的性能差距不大。如果集群可以分配的executor个数为18个,那么partition数可以从24个调整为18个(或者36个等等)。
原因比较明显,就不多提了。展示几个实验数据
下图为性能测试实验中3,6,12个executor下数据处理时间(纵坐标)和数据量(横坐标)的关系,是明显的线性关系。
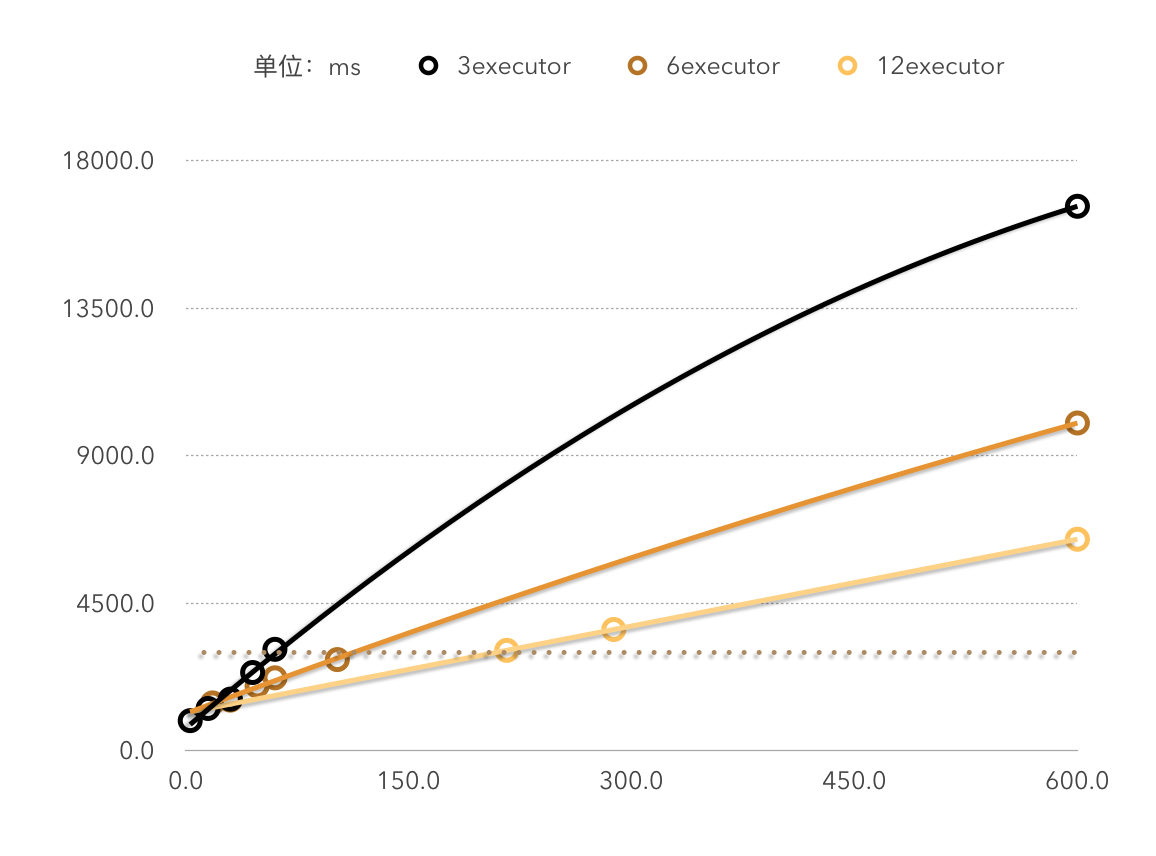
下图为性能测试实验中在处理600条数据时,executor数(横坐标)和时间(纵坐标)的关系(分区个数为executor的整数倍)
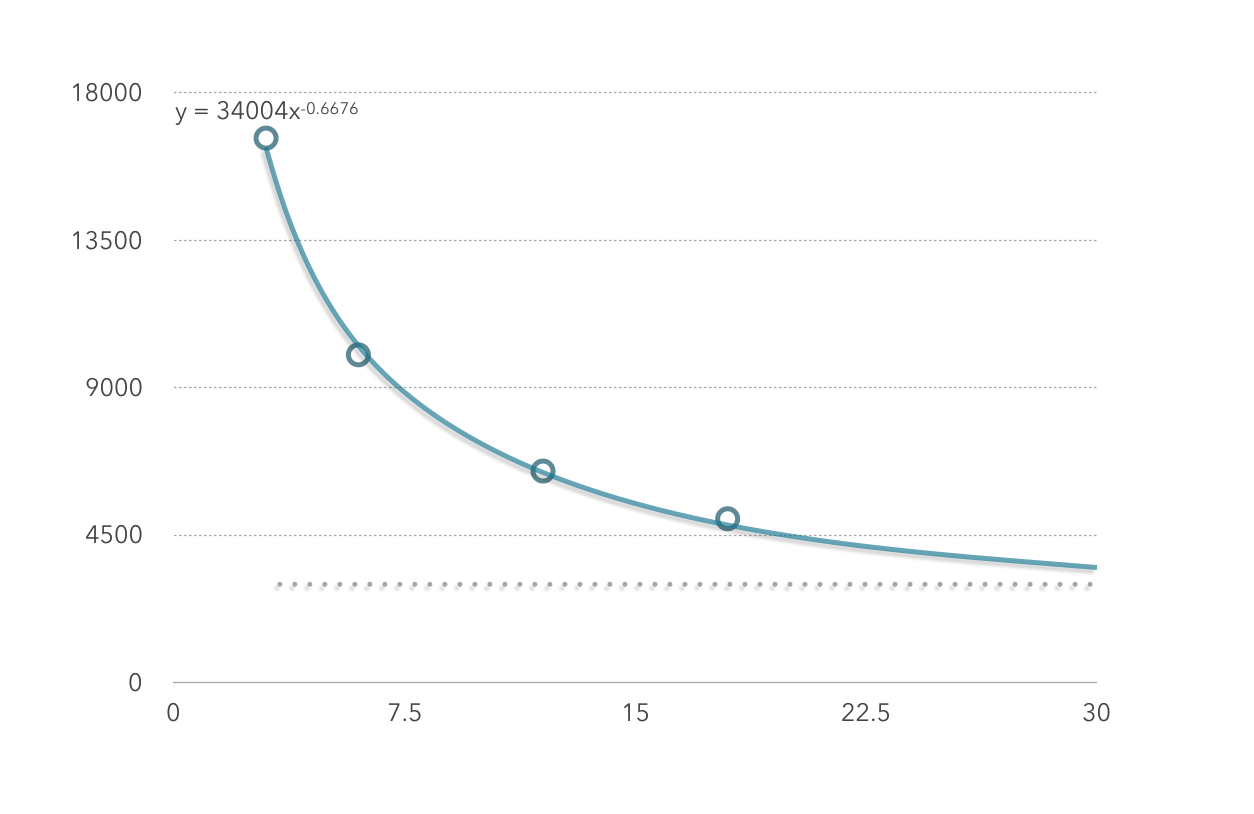
由图一的三组数据也可以看出,每秒能处理的数据的条数和executor的个数约等于线性关系。即如果当前集群每3秒能处理x条数据,那么集群扩容一倍后,每3秒应该能处理2x条数据。
由图二可看出,executor数和数据的处理时间不是简单的线性关系,也就是说,如果当前集群处理100条数据耗时6秒,并不能保证将集群扩容一倍后100条数据的处理时间变为3秒。
7)kafka的hash分区
kafka的各个分区处理的数据应该保证尽量按照某一特征(比如用户id)hash分区,这样能够保证某一用户的所有记录都在某一个partition,这样spark-streaming在处理reduceByKey时会提升效率。
8)提交任务时指定sql shuffle partition ,否则默认是200
--conf spark.sql.shuffle.partitions=6
kafka+spark-streaming实时推荐系统性能优化笔记的更多相关文章
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- Apache Kafka + Spark Streaming Integration
1.目标 为了构建实时应用程序,Apache Kafka - Spark Streaming Integration是最佳组合.因此,在本文中,我们将详细了解Kafka中Spark Streamin ...
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
随机推荐
- 【转】Linux系统编程---dup和dup2详解
正常的文件描述符: 在linux下,通过open打开以文件后,会返回一个文件描述符,文件描述符会指向一个文件表,文件表中的节点指针会指向节点表.看下图: 打开文件的内核数据结构 dup和dup2两个函 ...
- [Usaco2005 oct]Flying Right 飞行航班
Description 为了表示不能输给人类,农场的奶牛们决定成立一家航空公司.她们计划每天早晨,从密歇根湖湖岸的最北端飞向最南端,晚上从最南端飞往最北端.在旅途中,航空公司可以安排飞机停在某些机场. ...
- ACM_N皇后问题
N皇后问题 Time Limit: 2000/1000ms (Java/Others) Problem Description: 在N*N的方格棋盘放置了N个皇后,使得它们不相互攻击(即任意2个皇后不 ...
- android序列化(2)Parcelable与Parcel
1.简介 Parcel : 包裹 Android采用这个它封装消息数据.这个是通过IBinder通信的消息的载体.需要明确的是Parcel用来存放数据的是内存(RAM),而不是永久性介质(Nand等 ...
- 跨站脚本攻击XXS(Cross Site Scripting)修复方案
今天突然发现,网站被主页莫名奇妙的出现了陌生的广告. 通过排查发现是跨站脚本攻击XXS(Cross Site Scripting).以下为解决方案. 漏洞类型: Cross Site Scriptin ...
- JDBC使用游标实现分页查询的方法
本文实例讲述了JDBC使用游标实现分页查询的方法.分享给大家供大家参考,具体如下: /** * 一次只从数据库中查询最大maxCount条记录 * @param sql 传入的sql语句 * @par ...
- Magento 多站点多域名安装教程(可以设置手机模版哟,亲 \(^o^)/)
这篇文章是安装magento子域名的教程,请先进行安装之前,确认以下几点: 1.请先确认子域名是否已经指向你的服务器 2.可以编辑.htaccess文件 3. 熟悉Cpanel操作 我们的目标是建立一 ...
- PHP实现写LOG日志的代码
这篇文章给大家介绍的内容是关于PHP实现写LOG日志的代码,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. public function write_log(){ //设置目录时间 ...
- Flask框架 之request对象
一.request对象属性 属性 说明 类型 data 记录请求的数据,并转换为字符串 * form 记录请求中的表单数据 MultiDict args 记录请求中的查询参数 MultiDict co ...
- ORB-SLAM2:一种开源的VSLAM方案(译文)
摘要: ORB-SLAM2是基于单目,双目和RGB-D相机的一套完整的SLAM方案.它能够实现地图重用,回环检测和重新定位的功能.无论是在室内的小型手持设备,还是到工厂环境的无人机和城市里驾驶的汽车, ...