Clustering[Spectral Clustering]
0. 背景
谱聚类在2007年前后十分流行,因为它可以快速的通过标准的线性代数库来实现,且十分优于传统的聚类算法,如k-mean等。
至于在任何介绍谱聚类的算法原理上,随便翻开一个博客,都会有较为详细的介绍,如这里。当然这些都来自《A Tutorial on Spectral Clustering》一文。为了上下文一致性和便于理解,我就直接截图别人基于这篇论文中翻译好的部分(偷懒):
- 1 - 无向权重图:谱聚类是基于图论结构,也是数据结构的毗邻矩阵来实现的,即将所有的点的看成是一个相互连接的图(graph);
上图中\(|A|\)即为聚类后的一个类别的数据点集合;- 2 - 相似矩阵:通过定义相似函数,计算不同点之间的相似性,将其作为两点之间连线上的权重值。相距越近,则权重越大,越远则权重值越小;
其中第三种全连接方法的高斯方差决定了近邻的范围是多大;- 3 - 最后当然就是想着怎么把图给切割开,fisher准则就是聚类的目的为:类内间距最小,类间间距最大。从而期望于切割整个图之后,子图之间连线的权重之和最小;


1. 谱聚类
如上述第三点所述,当我们构建了图,定义了相似函数,得到了毗邻矩阵和度矩阵之后。一步到位的想法就是怎么切割,不过显然还是需要其他知识介入。
谱聚类可以通过线性代数关于这两个矩阵的特征值和特征向量来考虑,而通过这两个矩阵组合的叫做图拉普拉斯矩阵“graph laplacian matrices”。有个领域叫做“spectral graph theory”,研究了不少这些矩阵的特性,这么说是图拉普拉斯矩阵不止一个形式。
1.1 未归一化的图拉普拉斯矩阵
我们总假设\(G\)是一个无向的,具有权重矩阵\(W\)的权重图,其中\(w_{ij}=w_{ji}>0\)。当使用这个矩阵的特征向量时,不需要进行归一化,且特征值以升序排序。前k个特征向量,表示的就是前k个最小特征值对应的特征向量。
未归一化的拉普拉斯矩阵的特性

上述中,涉及到几个线性代数的知识:
- 一个实数对称矩阵的所有特征值都是实数(来自《introduction to linear algebra》chapter 6.4)
- 证明一个矩阵是半正定的方式如下(来自《introduction to linear algebra》chapter 6.5)
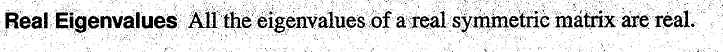
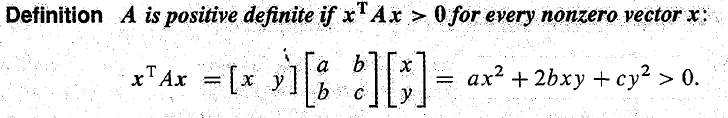
值得注意的是,上述的拉普拉斯矩阵是未归一化的,该矩阵不依赖于毗邻矩阵\(W\)的对角元素,且所有非对角位置上与W一致的邻接矩阵可以得到相同的非归一化的拉普拉斯矩阵,即图中所有的自连接的点不影响对应的图拉普拉斯,即点之间的关系才影响。
非归一化的图拉普拉斯矩阵和他的特征值和特征向量可以用来描述图的许多特性,下面的参考文献中Mohar等人的工作有较为详细的研究。
联通子图的个数
假设\(G\)是一个无向图,其中的权重都是非负的。那么特征值0的自由度个数(原文叫multiplicity,重数)等于联通子图的个数,即假设有k个重数,那么就有\(A_1,A_2,...A_k\)个子图,且特征值0的特征空间可以通过指示向量(基向量)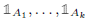 表示。
表示。
证明:
- k=1:即整个图被归为1类,假设\(f\)是特征值0的特征向量,那么:
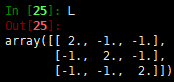
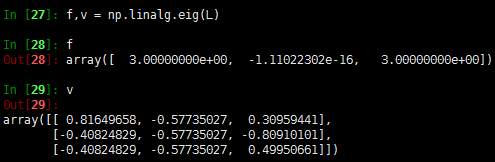
因为\(w_{ij}\)是非负的,所以和为0的时候即\(w_{ij}(f_i-f_j)^2\)等于0,那么假设两个点是相连的,即\(w_{ij}>0\),那么\(f_i=f_j\)。这样的话,可以发现对于所有可以通过某个路径进行相连的所有点,在\(f\)中的值都是相同的。那么如果只有一个类别,那么就只有一个向量。我们举个例子,假设有一个图,其中3个节点,两两相连,权重值都为1:
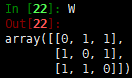
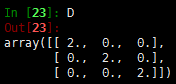
可以看出,第二个特征值为0(近似),其对应的特征向量为\([-0.57,-0.57,-0.57]=-0.57*[1,1,1]\),而\([1,1,1]\)被称为常量向量- k=其他值。
不失一般性,假设图中的所有的点都是按照其对应的子图类进行有序排列的,在这种情况下,毗邻矩阵\(W\)可以变成一个块矩阵组成的形式,当然对于\(L\)也是一样的:
可以发现每个块\(L_i\)都是一个对应的图拉普拉斯子矩阵,对应着第\(i\)个连通子图。那么依据矩阵的知识,相当于将整个矩阵划分成相同特性的多个子矩阵,其中\(L\)的特征向量就等于第\(L_i\)个特征向量的值加上其他子矩阵维度上为0。且\(L_i\)是一个联通图,那么其就有特征值为0且所有元素为1的特征向量。因此,矩阵\(L\)的子矩阵中特征值为0的个数就等于联通子图的个数。
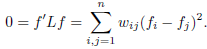
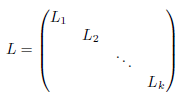
1.2 归一化的图拉普拉斯矩阵
有2个矩阵被称为归一化的图拉普拉斯。这两个矩阵较为相似:
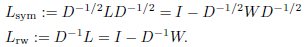
第一个矩阵是一个对称矩阵,第二个和随机游走十分相关。关于归一化图拉普拉斯矩阵的知识,可以参见参考文献中Chung的
\(L_{sym}\)和\(L_{rw}\)的特性
这两个归一化的拉普拉斯矩阵具有以下特性:
- 1 - 对于任何向量\(f\in R^n\),有:
- 2 - 有且仅有\(\lambda\)和\(w=D^{1/2}u\)分别是\(L_{sym}\)的特征值和特征向量时,\(\lambda\)和\(u\)就是是\(L_{rw}\)的特征值和特征向量;
- 3 - 有且仅有\(\lambda\)和\(u\)满足\(Lu=\lambda Du\)时,\(\lambda\)和\(u\)是\(L_{rw}\)的特征值和特征向量
- 4 - 0和常量向量
是\(L_{rw}\)的特征值和特征向量,0和\(D^{1/2}\)
是\(L_{sym}\)的特征值和特征向量
- 5 - \(L_{sym}\)和\(L_{rw}\)都是半正定的,且有n个非零的实值特征值,\(0\leq \lambda_1 \leq \lambda_2 ...\leq \lambda_n\)
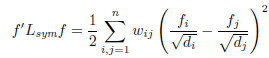
联通子图的个数
假设\(G\)是一个无向图,其中权重都是非负的,那么\(L_{rw}\)和\(L_{sym}\)的特征值为0的自由度个数等于图中联通子图的个数,
- 对于\(L_{rw}\),其0特征值对应的特征空间的基向量为这些子图对应的指示向量
;
- 对于\(L_{sym}\),其0特征值的特征空间的基向量为
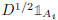
可以看出,上述就是第4个特性。将未归一化的拉普拉斯的联通子图的个数的推论等效应用到归一化的拉普拉斯矩阵上即可。
2.聚类方法
对于第一种未归一化的拉普拉斯矩阵情况:

上述步骤可以简单归纳为:
- 1 - 选择合适的相似函数,计算相似矩阵
- 2 - 计算度矩阵\(D\),毗邻权重矩阵\(W\),从而建立拉普拉斯矩阵\(L\)
- 3 - 计算拉普拉斯矩阵\(L\)的前k个特征向量,组成矩阵\(n\times k\)
- 4 - 用k-mean算法将上述的特征向量矩阵按行为样本(即\(n\)个样本),列为特征(即k个特征)进行k个类别的聚类。
对于第二种归一化的拉普拉斯矩阵情况,因为有2种矩阵,故而有两种情况:

- 上述图中,该算法使用的是\(L\)的广义特征向量。上述流程作用于\(L_{rw}\),所以称为归一化的谱聚类。

- 上述图中,该算法使用的是\(L_{sym}\),并且添加了一个额外的行归一化,同样也是归一化的谱聚类。
上述三个算法都基本大同小异,除了他们使用的是不同的拉普拉斯矩阵。这三个算法中,最主要的技巧就是将抽象的数据点\(x_i\)的表征转换成\(y_i\in R^k\)。这是因为拉普拉斯矩阵的特性可以让这样的转变十分有用。而且表征的转变增强了数据中的聚类属性,从而可以轻松的在新的表征中进行检测类的聚合。
【待续。。。】
参考文献:
[] 1 - Mohar, B. (1991). The Laplacian spectrum of graphs. In Graph theory, combinatorics, and applications. Vol. 2 (Kalamazoo, MI, 1988) (pp. 871 { 898). New York: Wiley
[] 2 - Mohar, B. (1997). Some applications of Laplace eigenvalues of graphs. In G. Hahn and G. Sabidussi (Eds.), Graph Symmetry: Algebraic Methods and Applications (Vol. NATO ASI Ser. C 497, pp. 225 { 275). Kluwer
[] 3 - Chung, F. (1997). Spectral graph theory (Vol. 92 of the CBMS Regional Conference Series in Mathematics). Conference Board of the Mathematical Sciences, Washington
Clustering[Spectral Clustering]的更多相关文章
- [Scikit-learn] 2.3 Clustering - Spectral clustering
From: 2.3.5 Clustering - Spectral clustering From: 漫谈 Clustering (4): Spectral Clustering From: 漫谈 C ...
- 转:浅谈Spectral Clustering 谱聚类
浅谈Spectral Clustering Spectral Clustering,中文通常称为“谱聚类”.由于使用的矩阵的细微差别,谱聚类实际上可以说是一“类”算法. Spectral Cluste ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
- Spectral Clustering
谱聚类算法(Spectral Clustering)优化与扩展 谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在 ...
- 谱聚类(Spectral Clustering)详解
谱聚类(Spectral Clustering)详解 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似 ...
- 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
原文请戳:http://blog.csdn.net/abcjennifer/article/details/8170687 聚类算法是ML中一个重要分支,一般采用unsupervised learni ...
- 谱聚类 Spectral Clustering
转自:http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算 ...
- 基于谱聚类的三维网格分割算法(Spectral Clustering)
谱聚类(Spectral Clustering)是一种广泛使用的数据聚类算法,[Liu et al. 2004]基于谱聚类算法首次提出了一种三维网格分割方法.该方法首先构建一个相似矩阵用于记录网格上相 ...
随机推荐
- Javascript 对象 - 数组对象
JavaScript核心对象 数组对象Array 字符串对象String 日期对象Date 数学对象Math 数组对象 数组对象是用来在单一的变量名中存储一系列的值.数组是在编程语言中经常使用的一种数 ...
- git 入门教程之里程碑式标签
"春风得意马蹄疾,一日看尽长安花",对于项目也是如此,最值得期待的恐怕就要数新版本发布的时刻了吧?每当发布新版本时要么是版本号命名(比如v0.0.1)或者代号命名(比如Chelse ...
- Html:html是什麽、html文件结构
相关内容: html是什麽 html文件结构 首发日期:2018-02-12 html是什么: hmtl超文本标记语言,标准通用标记语言下的一个应用. html专门用于网页,它的“标志符”告诉了浏览器 ...
- 智能ERP 交接班统计异常的解决方法
请注意,有交接班统计数据不准确的需开启离线统计即可解决,交接班统计是按照结账时间来进行统计的 1.点击左侧导航栏中‘更多’-进入系统设置 2.进入营业设置后-开启离线统计-点击保存
- 解决Protege打开owl文件时程序卡死问题
Protege在打开本地owl文件时,程序卡死,而且在终端或是命令行中也没有报错.这是因为存放该本体的文件夹下面有很多其他的文件,只需要创建一个新的文件夹并把owl文件放入其中就可以解决该问题.
- SQL Server DATA文件夹下audittrace20180124152845_52.trc类文件异常增多
同事告知某现场SQL Server2008R2数据库的DATA文件夹下audittrace开头的trc文件不断增多,占用较大空间,因此需要关停,尝试解决步骤如下: 1.查看是否有后台开启的trace ...
- python字符串处理以及字符串格式化
一.python字符串处理 目录: 1.算长度(len),某个元素出现的次数(count) 2.切片 [ ],repr:把不可见字符显示出来 3.查找 #find,rfind从右边查找 4.字符串 ...
- 持续集成-Jenkins常用插件安装
1. 更新站点修改 由于之前说过,安装Jenkins后首次访问时由于其他原因[具体未知]会产生离线问题.网上找了个遍还是不能解决,所以只能跳过常用插件安装这步.进入Jenkins后再安装这些插件. 在 ...
- ubuntu16.04如何安装多个版本的CUDA
我的机器是CUDA16.04的,之前装过CUDA10.0,因为一些原因,现在需要安转CUDA9.0. 1.首先https://developer.nvidia.com/cuda-90-download ...
- springcloud(十五):Spring Cloud 终于按捺不住推出了自己的服务网关 Gateway
Spring 官方最终还是按捺不住推出了自己的网关组件:Spring Cloud Gateway ,相比之前我们使用的 Zuul(1.x) 它有哪些优势呢?Zuul(1.x) 基于 Servlet,使 ...