mysql 开发基础系列12 选择合适的数据类型(上)
一. char 与varchar比较
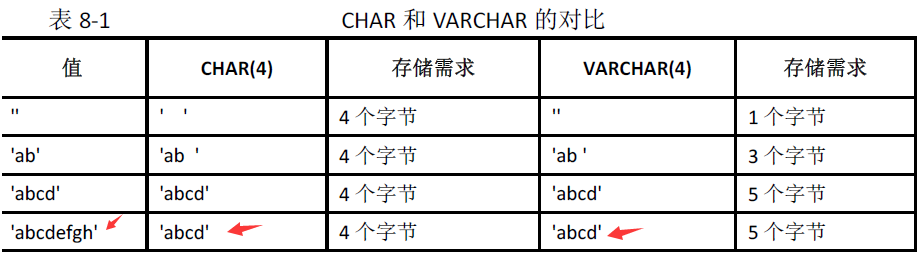
在上图的最后一行的值只适用在"非严格模式",关于严格模式后面讲到。在“开发基础系列4“ 中讲到CHAR 列删除了尾部的空格。
由于char是固定长度,所以字的处理速度比varchar快,但也浪费存储空间,随着mysql 的不断升级,varchar数据类型的性能也在不断改进提高,varchar的字节是L+1字节,1字节是用来记录其长度的字节。
char长度可选范围在0-255之间,也就是char最大能存储255个字符,varchar的长度范围为0-65535个字节。
下面重点区别下mysql与sql server中对varchar(n) n的区别
-- 在sql server中varchar(10) 10代表字节数,而不是字符数, 一个汉字二个字节所以最多放五个汉字
INSERT INTO table_1 values('你好中国人民')

-- 在mysql中varchar(10) 10代表字符数,而不是字节数,一个汉字是1个字符所以最多可放10个汉字
INSERT INTO Myisam_char VALUES('你好中国人民','你好中国人民')

在mysql中,不同的存储引擎对char和varchar的使用原则有所不同,这里简单概括下:
myisam 存储引擎:建议使用固定长度的数据列代替可变长度的数据列。
memory 存储引擎:目前都使用固定长度的数据行存储,因此无论使用char或varchar列都没有关系,两者都是作为char类型处理。
innodb 存储引擎:建议使用varchar类型,在innodb内部行存储格式没有区分固定长度和可变长度。
二. text与blob
二者通常用来保存较大文本,如文章或日记, 主要差别是BloB能用来保存二进制数据如照片,text只能保存字符数据。
这里介绍blob与text存在的一些常见问题:
1. "空洞"性能问题
在大量删除操作时,数据表中会留下很大的"空洞",以后填入这些空洞的记录在插入的性能上会有影响,为了提高性能,建议定期使用optimize table功能对表来进行碎片整理。下面来验证下
-- 创建表t
CREATE TABLE t(id VARCHAR(1000),context TEXT);
-- 往里面插入大量数据
INSERT INTO t VALUES(1,REPEAT('haha',100));
INSERT INTO t VALUES(2,REPEAT('haha',100));
INSERT INTO t VALUES(3,REPEAT('haha',100));
INSERT INTO t SELECT * FROM t;
-- ...
INSERT INTO t SELECT * FROM t;
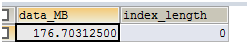
-- 获取表的空间大小 176.70 MB
SELECT (data_length/1024.0/1024.0) 'data_MB',
index_length FROM information_schema.tables
WHERE table_schema='test' AND table_name = 't';
-- 从表中删除ID为1的数据,占1/3 (共 131072 行受到影响)
DELETE FROM t WHERE id=1;
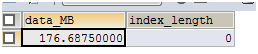
-- 再次获取表的空间大小, 是176.68 MB,并没有因为数据删除而减少
-- 使用optimize table 优化
OPTIMIZE TABLE t;

-- 再次获取表的空间大小, 是134.65MB 发现表的数据大大缩小了,"空洞"被回收了
mysql 开发基础系列12 选择合适的数据类型(上)的更多相关文章
- mysql 开发基础系列13 选择合适的数据类型(下)
一. BloB和Text 1. 合成索引 合成索引可以提高大文本字段BLOB和Text的查询性能, 合成索引是在表中增加一个字段存放散列值,这种技术只能用于精确匹配的查询,可以使用md5()或sha ...
- mysql 开发基础系列14 字符集
字符集是一套文字符号及其编码,比较规则的集合.第一个字符集是ascll(american standard code for information interchange). 1. 选择合适的字 ...
- mysql 开发基础系列11 存储引擎memory和merge介绍
一. memory存储引擎 memoery存储引擎是在内存中来创建表,每个memory表只实际对应一个磁盘文件格式是.frm. 该引擎的表访问非常得快,因为数据是放在内存中,且默认是hash索引, ...
- mysql 开发基础系列17 存储过程和函数(上)
一. 概述 存储过程和函数是事先经过编译并存储在数据库中的一段sql语句集合,可以简化应用开发人员的很多工作,减少数据在数据库与应用服务器之间的传输,提高数据处理效率是有好处的.存储过程和函数的区别在 ...
- mysql 开发基础系列15 索引的设计和使用
一.概述 所有mysql 列类型都可以被索引,是提高select查询性能的最佳方法. 根据存储引擎可以定义每个表的最大索引数和最大索引长度,每种引擎对每个表至少支持16个索引,总索引长度至少为256字 ...
- mysql 开发基础系列8 表的存储引擎
一. 表的存储引擎 1. 概述 插件式存储引擎是mysql数据库最重要的特性之一, 用户可以根据应用的需要选择如何存储和索引数据,是否使用事务等.在mysql 5.0里支持的引擎包括: MyISAM, ...
- mysql 开发基础系列1 表查询操作
在安装完数据库后,不管是windows 还是linux平台, mysql的sql命令都大同小异,相关命令都是相同的,每个命令结束后 都以 ; 结尾, 注意在windows平台中表名是不区分大小写 ...
- mysql 开发基础系列22 SQL Model
一.概述 与其它数据库不同,mysql 可以运行不同的sql model 下, sql model 定义了mysql应用支持的sql语法,数据校验等,这样更容易在不同的环境中使用mysql. sql ...
- mysql 开发基础系列21 事务控制和锁定语句(下)
1. 隐含的执行unlock tables 如果在锁表期间,用start transaction命令来开始一个新事务,会造成一个隐含的unlock tables 被执行,如下所示: 会话1 会话2 ...
随机推荐
- HDU-6060 RXD and dividing
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6060 多校的题目,每次只能写两道SB题,剩下的要么想不到,要么想到了,代码不知道怎么实现,还是写的 ...
- 图解HTTP系列
第一章 第二章 第三章 第四章 第五章 第六章 第七章 第九章 第十章
- 操作系统组成和工作原理以及cpu的工作原理
- sqlserver存储过程分页记录
USE [HK_ERP]GO/****** Object: StoredProcedure [dbo].[GetPageBillsByShopID] Script Date: 2018/10/30 1 ...
- 实现highcharts放大缩小
原文地址:http://www.stepday.com/topic/?800 当我们将图表某个区域放大值某一个倍数后发现刻度间隔距离也放大了,由于刻度间隔还是原来初始所设定的值,从而让局部数据的X轴刻 ...
- Eclipse配置python开发环境
1.打开Eclipse,找到Help菜单栏,进入Install New Software…选项. 点击work with:输入框的旁边点击Add…,Name可以随便是什么,我输入的是PyDev,Loc ...
- HDU 6346 整数规划 (最佳完美匹配)
整数规划 Time Limit: 5500/5000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Subm ...
- robotframework-databaselibrary安装步骤
我这里主要介绍离线安装的方式 第一步:下载robotframework-databaselibrary-0.6 包可以去网上找安装包下载,如果实在找不到可以联系我 第二步:下载PyMySQL-0.9. ...
- 【原创】岁月如歌 一款网易歌单生成pdf的软件
介绍 这是一款可以将网易云音乐的歌单中所有歌词输出为pdf的软件. 项目持续维护地址 http://brightguo.com/song-list-to-pdf/ 目前没有搜到相关网易歌单导出为pdf ...
- 虚拟机找不到/mnt/hgfs挂载目录——debian与 vmware
如果在安装好 VMware Tools 并在设置里面设定好共享目录之后仍然找不到 /mnt/hgfs 默认挂载目录,那么尝试以下步骤: 1. 确认VMware Tools 和共享目录设定已经完成: 2 ...